流量控制–概覽
Overview of Concepts
本章將介紹流量控制,研究出現流量控制的原因及其優缺點,並介紹流量控制的關鍵概念。
了解Linux的流量控制的目的:一是為了更好地理解底層對報文的處理邏輯,二是在流量控制中使用了很多很好的流量處理方法,可以學習一下這些方法和思想,翻譯自://tldp.org/en/Traffic-Control-HOWTO/index.html。
2.1. 什麼是流量控制
流量控制是指在路由器上接收和傳輸數據包的隊列系統和機制的統稱。包括決定(如果和)輸入接口上以哪種速率接收哪個包,以及決定在輸出接口上以哪種順序傳輸那些包。
在最簡單的模型中,流量控制包含簡單的隊列,該隊列收集了所有的報文,並在硬件(或底層設備)可以接收報文時儘快讓這些報文出隊列。這種隊列即FIFO。它就像一個進入高速公路的收費站,每輛車必須停下並繳納過路費,而此時其他汽車也必須等待。
註:Linux下默認的qdisc為
pfifo_fast,它比FIFO更加複雜。
在各種軟件中都有隊列的影子。隊列是一種組織掛起的任務或數據(參見Section 2.5, 「Queues」)的方式。由於網絡鏈接通常會以序列化的方式攜帶數據,因此需要一個隊列來管理出站的數據包。
在台式機和一台高效的網絡服務器共享(到互聯網的)同一上行鏈路的情況下,可能會對帶寬資源產生競爭。例如,服務器填充路由器上的輸出隊列的速度可能比通過鏈路傳輸數據的速度還要快,此時路由器開始丟包(緩衝已經滿了),這樣台式機(可能是交互應用的用戶)可能會面臨丟包和高延遲。通過劃分內部隊列來服務這兩種不同的應用,就可以在兩個應用間更好地共享網絡。
流量控制是一組允許管理員對這些隊列進行精細控制的工具和網絡設備的排隊機制的統稱。雖然這些工具重新分配流量和包的能力是強大的,同時也可能會很複雜,但最好留有足夠的帶寬。
術語Quality of Service (QoS)通常作為ip層的流量控制的代名詞。
2.2. 為什麼使用流量控制
流量控制工具允許實現者對傳輸到網絡中的數據包或網絡流應用首選項、組織或業務策略,進而管理網絡資源,如吞吐量或延遲。
從根本上說,由於網絡中的分組交換,流量控制變得非常必要。
為了簡要說明數據包交換的新穎性和巧妙性,考慮一下在整個20世紀構建起來的電路交換電話網絡。為了發起一個呼叫,網絡設備需要了解建立呼叫的規則。當一個呼叫者嘗試發起連接時,網絡會使用這些規則來為整個呼叫或連接期間保留一個電路。當有一個使用該資源的通話佔線時,其他呼叫或呼叫者都不能使用該資源,意味着由於資源不可用,許多設備可能會因為單個部件而阻塞通話的建立。
回到分組交換網絡,這是20世紀中期的一項發明,後來被廣泛使用,並且在21世紀幾乎無處不在。分組交換網絡與基於電路的網絡有一個非常重要的區別,即網絡設備處理的數據單位不再是電路,而是一小塊的數據,稱為數據包。分組交換網絡只需要處理一小部分的工作:讀取目的地標識,並傳輸該數據包。
分組交換網絡有時會被認為為無狀態的,這是因為它不需要跟蹤網絡上所有的活動的流。因此,缺乏對特定數據包或網絡流重要性的區分是這種分組交換網絡的一個弱點。網絡可能會因數據包的相互競爭而超載。
簡單來說,流量控制工具允許根據數據包的屬性,通過不同的方式將數據包放入網絡。不同的工具用於解決不同的問題,可以組合多個工具來實現複雜的規則,滿足偏好或業務目標。
下面是一些常見問題的例子,可以用於解決或改善這些工具。
下面並沒有給出流量控制的所有解決方案,僅給出了可以使用流量控制工具解決的常見問題,用於最大化利用網絡。
常用的流量控制方案
- 將總帶寬限制為某個值:TBF,和帶子類的HTB。
- 限制特定用戶、服務或客戶的帶寬:HTB 類和帶filter的分類
- 最大化非對稱鏈路上的TCP吞吐量;提升傳輸的ACK包的優先級:wondershaper。
- 為特定應用或用戶預留帶寬:帶子類的HTB和分類。
- 偏好延遲敏感的流量:HTB類中的PRIO。
- 管理超額的帶寬:HTB租借
- 允許公平分配未預留的帶寬:HTB租借
- 確保丟棄特定類型的流量:給filter添加policer,使用drop動作。
需要注意的是,有時候最好訂購更多的帶寬,流量控制並不能解決所有的問題。
2.3 優點
正確引入流量控制可以更加可靠地對網絡資源地利用進行預測,並可以減少對這些資源的不穩定競爭,這樣就可以實現流量控制配置的目標。即使在為更高優先級的交互式流量提供服務同時,也可以為批量下載分配合理的帶寬;即使低優先級的數據傳輸(如郵件),也可以分配到一定的帶寬,而不會對其他類型的流量造成巨大的影響。
如果流量控制中的配置代表了用戶的策略,那麼該用戶(或應用)就應該知道後續會網絡的影響。
2.4 缺點
使用流量控制的最大缺點之一是其複雜性。實踐中,有一些方法可以用來熟悉流量控制工具,簡化關於流量控制及其機制的學習曲線,但如何確定一個流量控制的錯誤配置仍然是一個相當大的挑戰。
當正確配置流量控制時,可以公平地分配網絡資源。但不合理的使用可能導致對資源的分裂性爭奪。
路由器上支持流量控制方案所需的計算資源必須能夠處理維護流量控制結構的成本的增加。幸運的是,它的成本增量很小,但隨着配置和複雜度的增加,其成本可能顯著增加。
對於個人來說,不需要考慮引入量流量控制帶來的培訓成本,但對於一個公司來說,相比引入流量控制,採購更多的帶寬可能是一個更簡單的解決方案(員工的培訓成本可能要遠高於採購帶寬的成本)。
2.5 隊列
所有的流量控制都會用到隊列,它是調度算法不可或缺的一部分。一個隊列是一個位置(或緩衝),包含有限數目的元素,等待相應的動作或服務。在網絡中,一個隊列是報文(單位)等待被硬件(服務)傳輸的地方。在最簡單的模型中,報文根據先進先出的方式進行傳輸。在計算機網絡(和更普遍的計算機科學)的學科中,這種隊列被稱為FIFO。
如果沒有其他機制,隊列是不會為流量控制提供任何優化。此時一個隊列只有兩個需要關注的動作:任何到達隊列的報文(或單位)都會在隊列中排隊;為了從隊列中移除一個元素,則需要對其執行出隊列操作。
當結合其他機制時,隊列可以提供更加豐富的功能,如延遲包容,重新排列,丟棄,以及優先處理多個隊列中的數據包。一個隊列可能會使用子隊列,用來處理更加複雜的調度行為。
從上層的軟件的角度來看,當一個報文入隊列後,該隊列對待傳輸報文的處理行為和處理順序對上層軟件來說是無關緊要的。因此,對上層來說,整個流量控制隊列系統可能只是一個單一的隊列,只有對使用了流量控制的那一層來說,流量控制結構才是可見的。
下圖展示了一個高度簡化的Linux網絡棧的傳輸路徑上的隊列圖:
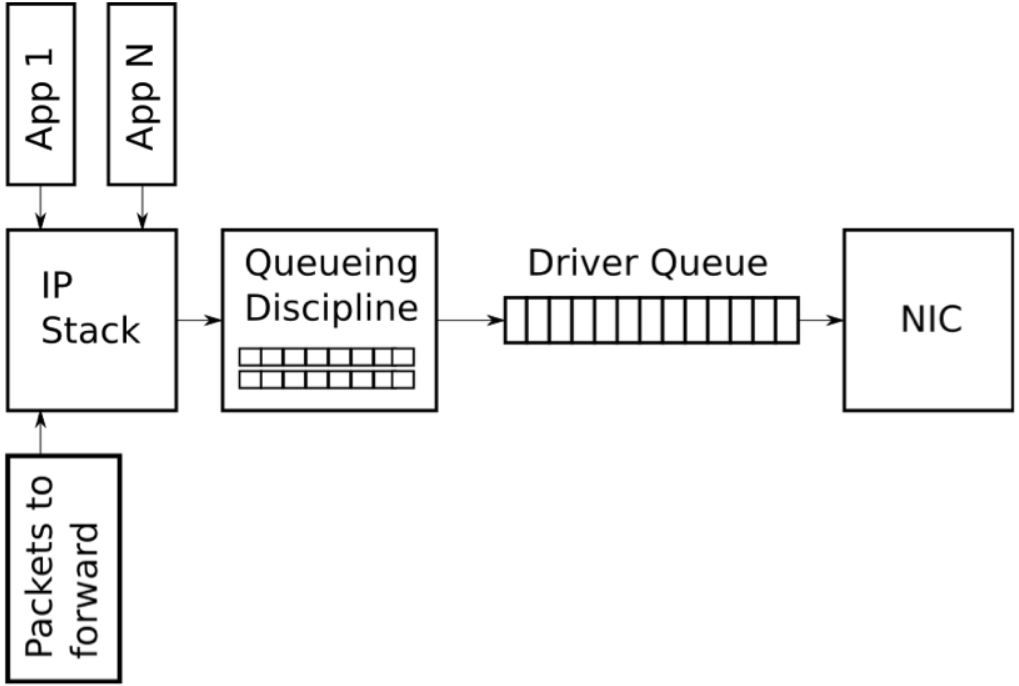
2.6 流
一條流指兩個主機之間的特定連接或會話。兩個主機之間的任何(唯一的)報文集都可以看作是一條流。TCP使用源IP和端口,目的IP和端口來表示一條流,UDP流也是類似的。
流量控制機制經常會將流量劃分為不同的類,並以聚合流的方式(如DiffServ)對這些流進行聚合和傳輸。類似的,可能會基於單個流來平均分配帶寬。
當嘗試在一組競爭流中平均分配帶寬時,對流的處理就變得很重要,尤其是在某些應用故意構建大量流時。
2.7 令牌和桶
整流機制的兩個關鍵概念是令牌和桶。
為了控制出隊列的速率,實現中可以在每個元素出隊列時計算出列的報文數或位元組數(雖然這樣會使用複雜的定時器和工具進行精確限制)。除了計算當前使用量和時間,還有一種方法廣泛用到流量控制中,即以一定速率生成令牌,只有存在可用的令牌是才允許報文或位元組出隊列。
考慮一個遊樂園遊樂設施,人們排隊等候體驗遊樂設施。讓我們將該設施想像成一個軌道,在這個軌道上,推車會通過一個固定的軌道。這些推車以固定的速率排在隊伍的前頭。為了享受乘坐的樂趣,每個人必須等待一輛可用的推車,每個推車類似於一個令牌,人類似於一個報文。這種機制就是限流或整流機制。 在特定時期內,只有一定數量的人可以體驗騎行。
為了擴展這個類比,想像遊樂園裡有一條空的線路,而軌道上有大量的推車準備載客,如果大量的人一起進入隊列,很多(也許全部)人可以體驗乘坐,因為此時有一定數量的可用的推車。推車的數量是一個類似於桶的概念。一個桶包含很多令牌,可以使用桶中現有的令牌,而無需等待。
為了完成這個類比,遊樂園裡的推車(我們的令牌)的到達的速率是固定的,且可用的推車不超過桶大小。因此,令牌會以固定速率填充到桶,如果沒有使用令牌,則桶可以被填滿。如果使用了令牌,則桶不會被填滿。桶是支持突發流量(如HTTP)的一個關鍵概念。
TBF qdisc是一個典型的整流器(關於TBF包括一個圖表,它可以幫助以可視化的方式展示令牌和桶的概念)。TBF會生成速率令牌,只有當令牌可用時才能傳輸報文。令牌是一個通用的整流概念。
當隊列不需要令牌時,這些令牌會被收集起來,並在後續需要時使用。無限制地收集令牌會抵消整流帶來的好處,因此需要限制收集的令牌的數量。隊列中的令牌可用於需要出隊列的報文或位元組。 這些無形的令牌存儲在無形的桶中,可以存儲的令牌數量取決於桶的大小。
這也意味着,在任意時刻都可能存在一個滿token的桶,可預測的流量可以使用小的桶,突發流量可以使用大的桶(除非目標是為了降低流的突發)。
總之,令牌使用一定速率來生成,最大可用的令牌數由桶的大小來決定。通過這種方式可以處理突發流量,使得傳輸的流量變得平滑。
令牌和桶是息息相關的,用於 TBF (classless qdiscs的一種) 和HTB (classful qdiscs的一種)。在tcng語言中,二色和三色標識法就是令牌桶的應用。
2.8 報文和幀
網絡上傳輸的數據的術語取決於其所在的網絡層。儘管在此處給出了報文和幀的技術上的區別,但本文並不作區分。
幀通常用於描述二層網絡上轉發的數據單位。以太接口,PPP接口和T1接口都將二層數據單位稱為幀。幀是流量控制的實際單位。
從另一方面將,報文時上層協議的概念,表示三層數據單位。本文檔的使用了報文。
2.9 NIC,網絡接口控制器
一個網絡接口控制器是一個計算機硬件組件,與前面的軟件組件不同,它將一個計算機連接到一個計算機網絡。網絡控制器使用特定的數據鏈路層和物理層標準實現了通信所需的電子電路,如 Ethernet, Fibre Channel, Wi-Fi or Token Ring。流量控制必須處理NIC接口的物理限制和特徵。
2.9.1 網絡棧的巨包
大多數NICs都有一個固定的傳輸單位(MTU),即物理媒介可以傳輸的最大幀。對於以太網來說,默認為1500位元組,但對於支持巨型幀的以太網來說,其MTU可以達到9000位元組。在IP網絡棧中,MTU作為發送或傳輸報文時的大小限制。例如,如果一個應用向TCP socket寫入了2000位元組的數據,那麼IP棧需要創建兩個IP報文來保證報文小於或等於1500位元組的MTU。當需要傳輸大於MTU的數據時,會導致創建大量的小報文,並傳輸到 驅動隊列。
為了避免在傳輸路徑上對大報文處理產生的開銷,Linux內核實現了幾類優化:TCP分段卸載(TSO),UDP分片卸載(USO)以及通用的分段卸載 (GSO)。所有這些優化都允許IP棧創建的報文大於傳出的NIC上的MTU。對於IPv4,創建並放到驅動隊列中的報文可以達到65536位元組。在TSO和UFO場景下,NIC硬件負責將單個大報文切分為可以在物理接口上傳輸的小報文。對於沒有硬件支持的NIC,GSO會在報文進入驅動隊列之前對其進行相同的操作。
回顧一下,驅動隊列包含一個固定數目的描述符,每個描述符指向大小不同的報文,由於TSO, UFO 和GSO 允許更大長度的報文,因此這些優化會大大增加驅動隊列中保存的位元組數(即驅動中的描述符可能指向一個大於MTU的報文,後續會在NIC中進行報文切割)。
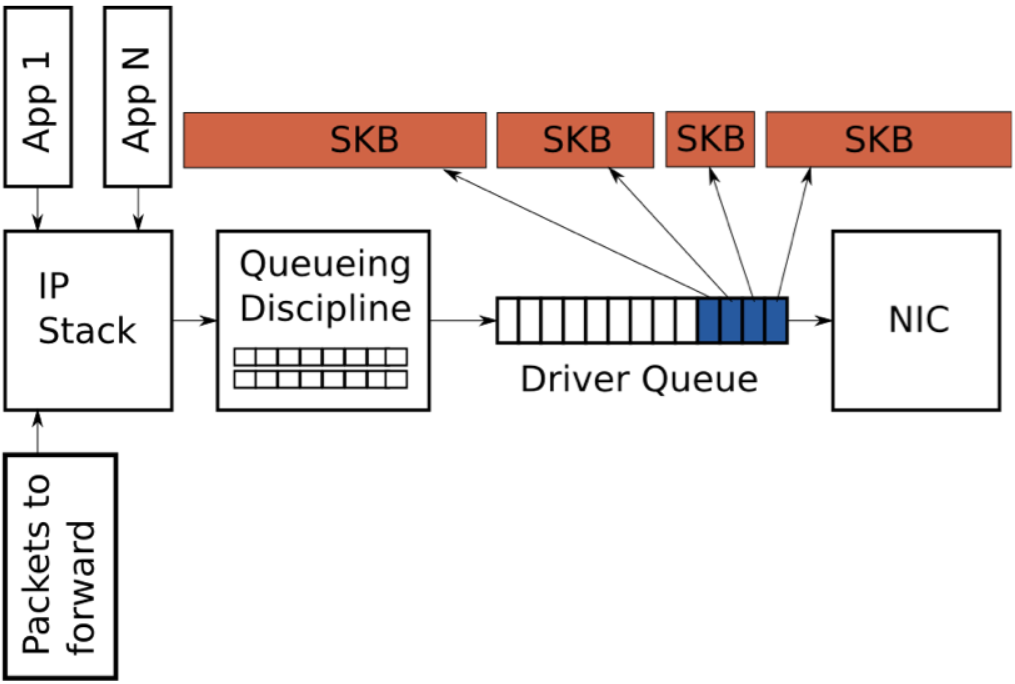
2.10 飢餓和延遲
IP棧和硬件(參見4.2章節的驅動隊列,和5.5章節對啟動隊列的管理)之間的隊列引入了兩個問題:飢餓和延遲。
NIC驅動程序從隊列中取出數據包進行傳輸,但隊列是空的,此時硬件會錯失一次傳輸的機會,進而導致系統吞吐量下降,這種情況稱為飢餓。注意,當系統不需要傳輸任何數據時,隊列也是空的,這是正常情況,並不歸類為飢餓。與避免飢餓相關的複雜情況是,正在填充隊列的IP棧和消耗隊列的硬件驅動程序是異步運行的,更糟糕的是,填充和獲取事件的間隔會隨着系統的負載和外部狀況(如網口的物理媒介)而變化。例如,在一個繁忙的系統上,IP棧向緩衝區添加報文的機會將變少,這會導致硬件在更多數據包入隊列之前耗盡緩衝區。基於這種原因,使用比較大的緩衝可以降低飢餓的概率,並保證高吞吐量。
當使用一個大的隊列來為一個繁忙的系統保持高吞吐量時,同時也會引入大量延遲。
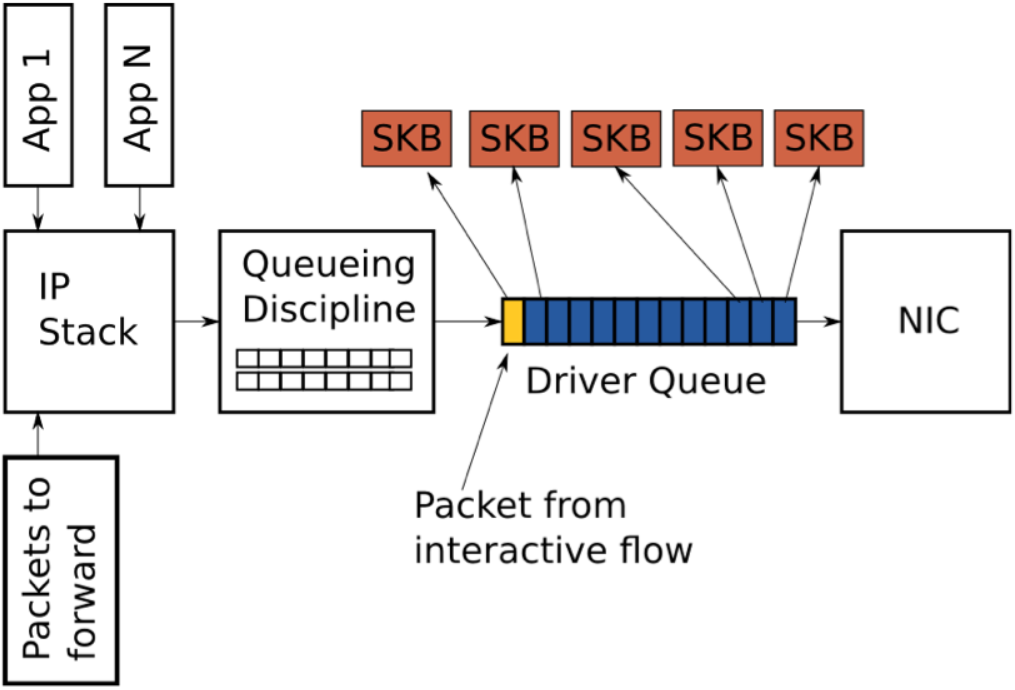
上圖展示了一個驅動隊列,其中幾乎填滿了高帶寬,大流量(藍色)下的TCP段。隊列的最後一個報文來自一個VoIP或遊戲流(黃色)。像VoIP或遊戲這樣的交互式應用通常會以固定間隔的時間發送小的報文,它們是延遲敏感型的。而高帶寬數據傳輸會產生更高的報文速率和更大的報文,更高的報文速率會填滿交互式報文之間的緩衝,導致交互式報文的傳輸被推遲。為了描述這種行為,考慮下面這種場景:
- 網口上允許傳輸的速率為5 Mbit/sec 或 5,000,000 bits/sec。
- 大流量上的每個報文是 1,500 bytes 或12,000 bits。
- 交互式流量上的每個報文是500 bytes。
- 隊列的深度為128個描述符。
- 此時隊列中有127個大流量報文和1個交互式報文。
鑒於上述假設,耗盡127個大流量報文並給交互式報文創造傳輸機會的時間為(127 * 12,000) / 5,000,000 = 0.304 seconds (對於根據ping來衡量的延遲結果為304毫秒),這樣的延遲對交互式應用來說是不可接受的,且不代表完整的往返時間(僅僅是交互式報文在隊列中等待傳輸前的時間)。如前面所述,當啟用TSO, UFO 或 GSO時,驅動隊列中的報文大小可以大於1500位元組,這將導致延遲更加嚴重。
為驅動隊列選擇一個合適的大小可以看作是一個Goldilocks 問題,為了保證吞吐量而不能大小,為了保證延遲而不能太大。
2.11 吞吐量和延遲之間的關係
在所有流量控制系統中,吞吐量和延遲都存在一定的關係。網絡鏈路上傳輸的的最大信息速率稱為帶寬,但是對於網絡上用戶來說,實際獲得的帶寬還有一個專用術語,吞吐量。
延遲
-
發送者傳輸和接收者解碼或接收數據之間的延遲,總是非負或非0的值。
-
原則上,延遲是單向的,但幾乎整個Internet網絡社區都在談論雙向延遲–發送方發送數據和通過某種方式確認收到數據之間的時間延遲,如ping
-
以毫秒計算延遲;在以太網上,延遲通常是0.3到1ms之間,在廣域網上,延遲為5到300ms之間。
吞吐量
-
衡量發送者和接收者之間成功傳輸的數據總量
-
以bit/sec為單位進行衡量;
註:延遲和吞吐量是常用的計算術語。例如,應用程序開發人員在嘗試構建響應工具時會提到了用戶感知的延遲。數據庫和文件系統人員會提到磁盤吞吐量。在網絡層上,在DNS中查詢網站名稱的延遲是感知一個網站性能的重要指標。
為了最大化下載吞吐量,設備供應商和供應商通常會調整他們的設備來容納大量數據包。當網絡準備接收另外一個報文時,網絡設備的隊列中如果有一個報文,則簡單地發送該報文即可。通過這種方式可以保證用戶的下載吞吐量。
該技術以延遲的代價來最大化吞吐量。想像一下,當高優先級的報文位於大隊列的末尾時,該報文在這個網絡上的理論上的延遲可能是100ms,但必須在隊列中等待傳輸。
雖然最大化吞吐量的決定非常成功,但對延遲的影響也是顯著的。
斯圖爾特·柴郡(Stuart Cheshire)在1990年代中期發出了一個名為愚蠢的延遲的警告,它採用了術語bufferbloat,大約15年後由吉姆·蓋蒂(Jim Getty)在他的博客的ACM隊列文章bufferbloat:互聯網中的黑暗緩衝和 Bufferbloat FAQ中重點介紹了最大化吞吐量的選擇。
在學術、網絡和Linux開發社區中,分組交換網絡存在的延遲和吞吐量之間的關係是眾所周知的。 Linux流量控制核心數據結構可以追溯到1990年代,並且一直在不斷開發和擴展,並增加了新的調度器和功能。


