自己實現一個 DFA 串模式識別器(二)
- 2020 年 9 月 20 日
- 筆記
正規表達式的實現原理
上文討論了串的模式的表達,即正規表達式。那麼這一小節將討論我們實現一個正規表達式的方法和原理。因為我們知道,一個正規表達式對應着一個串模式,而一個串模式又對應着一些列符合該模式描述的規則的串。那麼,我們是否可以通過實現出正規表達式,從而實現對一個給定串的判別呢?答案是肯定的。
狀態轉換圖
首先介紹,狀態轉換圖。
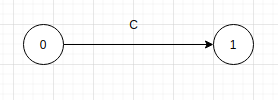
狀態轉換圖是一個有向圖,由節點和邊組成。每個節點代表一個狀態,狀態之間用箭頭連接,稱為邊。邊上的字符表示從該邊的出發節點讀取一個該邊上的字符後,可以抵達改變指向的狀態節點。如下圖:
狀態轉換圖中具有一個狀態標記為 start 狀態,被稱為初始狀態。識別一個字符串時,我們就從這個狀態開始。下圖展示了能夠識別 大於號 或者 大於等於號 的狀態轉換圖:
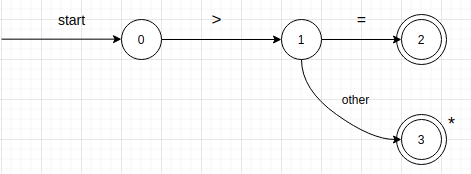
其開始狀態是狀態 0,在狀態 0 讀入下一個字符,如果該字符是 > ,那麼則轉向狀態 1,否則失敗。在狀態 1 時,讀入下一個字符,如果是 + ,則轉向狀態 2,否則標有 other 的邊表明轉向狀態 3.在狀態 2 上有雙圈,表示它是接受狀態。當進入這個狀態時,狀態轉換圖識別了記號 >= 。
通常會有多個狀態轉換圖,每個狀態轉換圖對應者一個類別(如記號)。如果沿着一個狀態轉換圖書別串時失敗,那麼就需要將前向指針回退到該狀態圖開始狀態時該指針所指向的輸入串的位置。並啟動下一個狀態轉換圖,試圖匹配下一個模式。顯然,我們可以通過不斷的組合狀態轉換圖來實現更加複雜的串模式匹配。可以說,狀態轉換圖為串模式識別提供了一種有效方法。
所以狀態轉換圖實現了正規表達式和圖結構的轉換。上面的狀態轉換圖對應着正規表達式:>(\(\epsilon\)|=) 。而圖結構十分容易使用計算機實現。
有窮自動機
有窮自動機是更一般化的狀態轉換圖。它可以是確定的即 DFA,也可以是不確定的即 NFA。其中「不確定」的含義是:對於某個輸入符號,在同一個狀態上存在不止一種轉換。我們可以通過構造有窮自動機把正規表達式編譯成識別器。二者都可以識別且僅能識別正規集,即能夠識別正規表達式所表示的字符串集合。但是二者有着時空上的權衡,DFA 導出的識別器比NFA導出的識別器要快得多,但DFA可能比與之等價的NFA大得多。(註:NFA,DFA 的數學模型定義這裡從略)
NFA
由於從正規式轉換成不確定的有窮自動機(NFA)更方便,所以先討論 NFA。
下圖是一個 NFA:

它所對應的正規表達式為:(a|b)*abb 。注意,NFA 是用帶標記的有向圖表示,稱為轉換圖,節點是狀態,有標記的邊是轉換關係。NFA 這種轉換圖與之前的狀態轉換圖很類似,但是區別是:同一個字符可以標記始於同一個狀態的兩個或多個轉換,邊上可以有輸入字符符號,也可以有特殊符號 \(\epsilon\) 。
從正規表達式構造 NFA
這裡採用一個簡單的算法來實現這種構造。首先構造自動機使其能夠識別任何 \(\epsilon\) 的字母表中的任何符號,然後由此構造自動機來識別包含一個交、一個連接或者一個克林閉包運算符的正規表達式。如對於正規表達式:a|b 可以先分別構造字符 a 和 b 的自動機,然後在從二者的 NFA 構造出 a|b 的 NFA。該算法被稱為 Thompson 構造法。
