human_pose_estimation_demo的再進一步研究
- 2019 年 11 月 1 日
- 筆記
這次研究的主要是速度問題,後來還獲得了其它方面的收穫。
1、原始的抽幀
對於這樣一個問題,想提高速度,能夠想到的最簡單、最直接的方法就是“抽幀”。比如添加一個計數器

這裡,只有當SumofFrames達到FRAMEBLOCK的時候,才進行下面的圖像處理,否則只是顯示圖像本身而不處理。
但是這樣做,得到的結果很詭異,就是這個人走走停停的。
這樣想來,這個圖像處理的過程,還是不能放到主線程中去,還是要獨立出來。
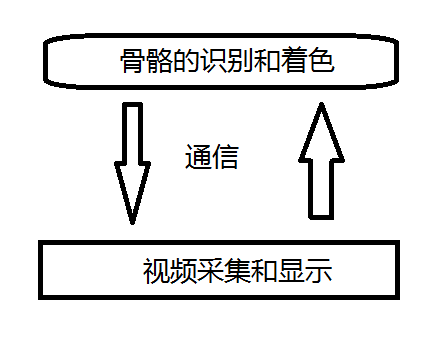
就是起碼要2個線程。這個時候Console程序的能力就不夠了,所以開始修改GOMFCTemplate。
2、對human_pose_estimation_demo結構的進一步理解
當我開始移植human_pose_estimation_demo到GOMfcTemplate中的時候,才發現它的結構化方法提供了非常多的便利:
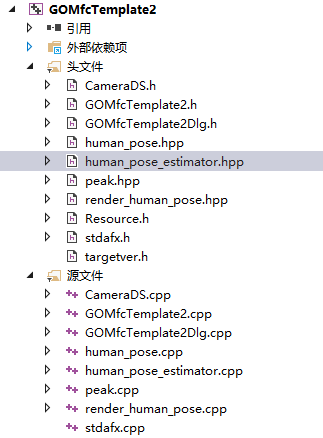
引入它的文件
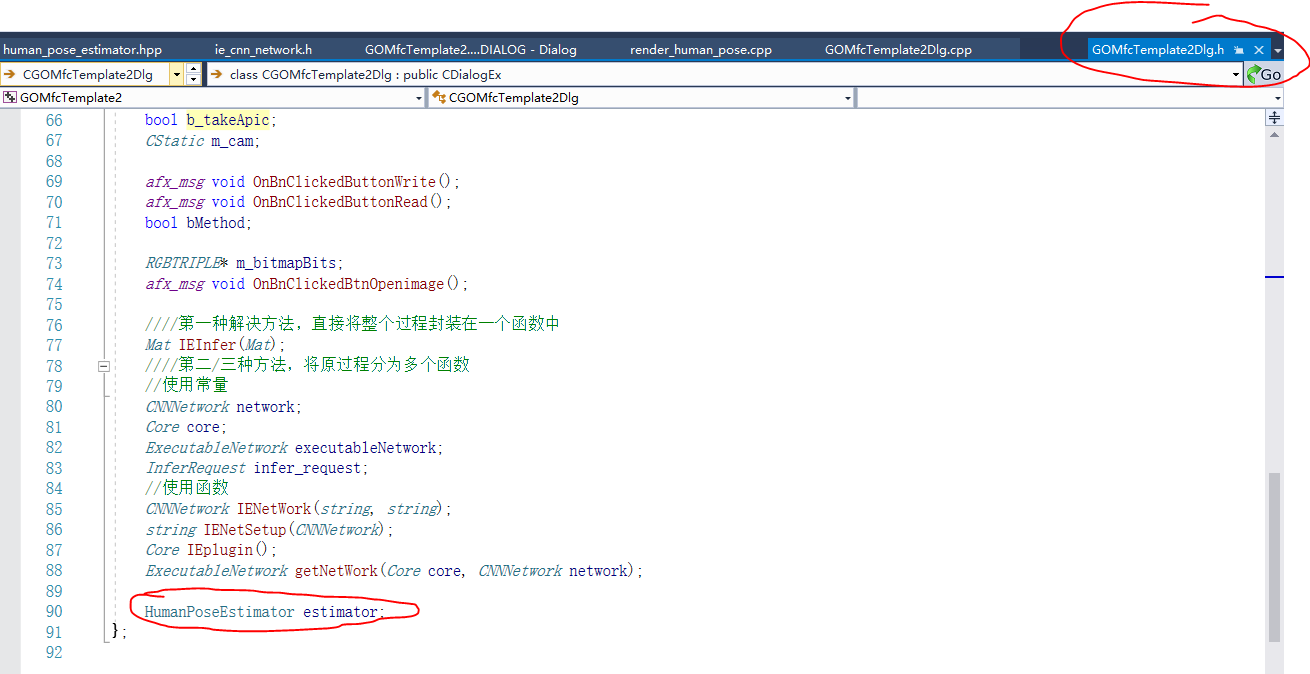
執行它的過程

就可以。
 當然看上去簡單,細節還是很多的,這個放到第4個部分來講。
當然看上去簡單,細節還是很多的,這個放到第4個部分來講。3、Dshow提供的加成
當我花了一番心思把算法移植過來,準備開始搞“2線程”的時候,測試發現速度已經有了明顯的提升:
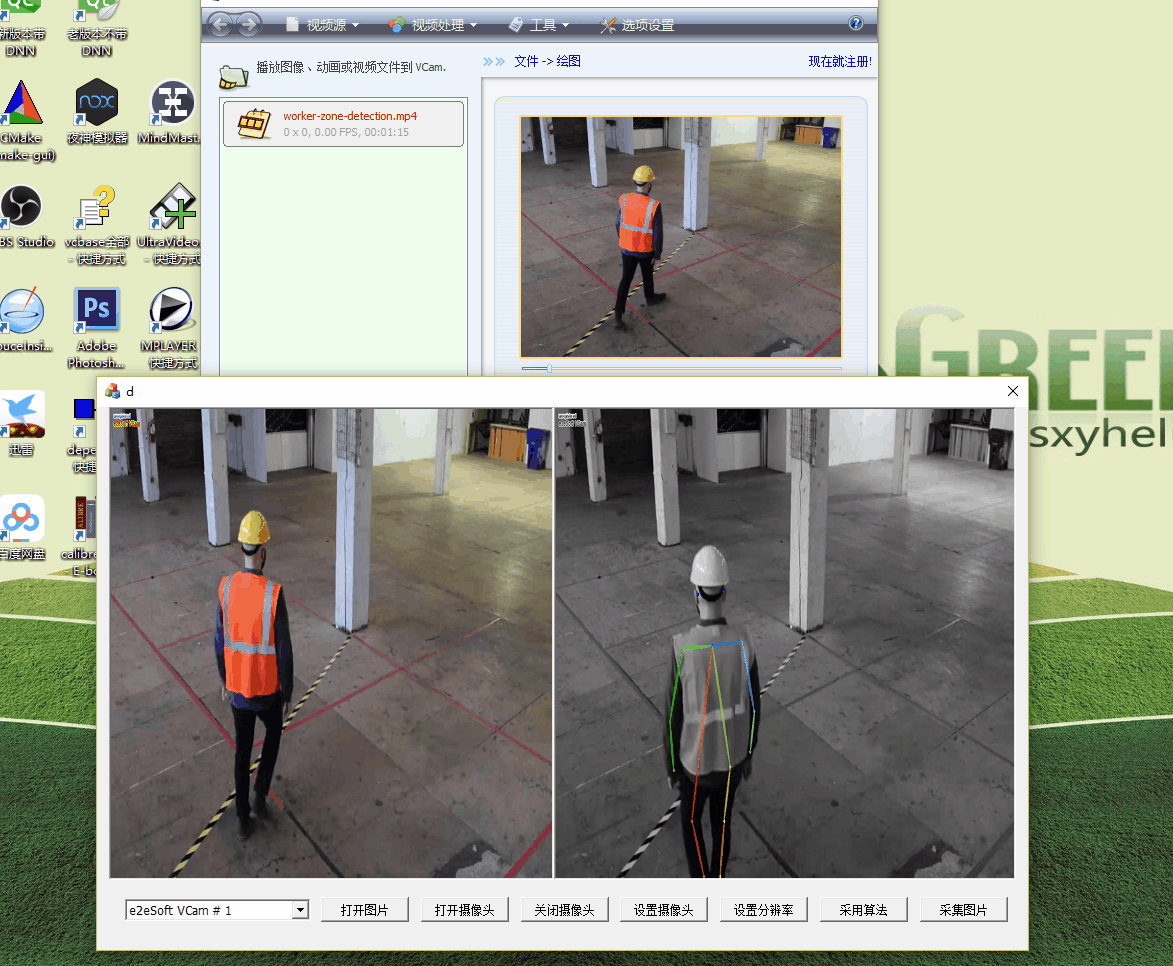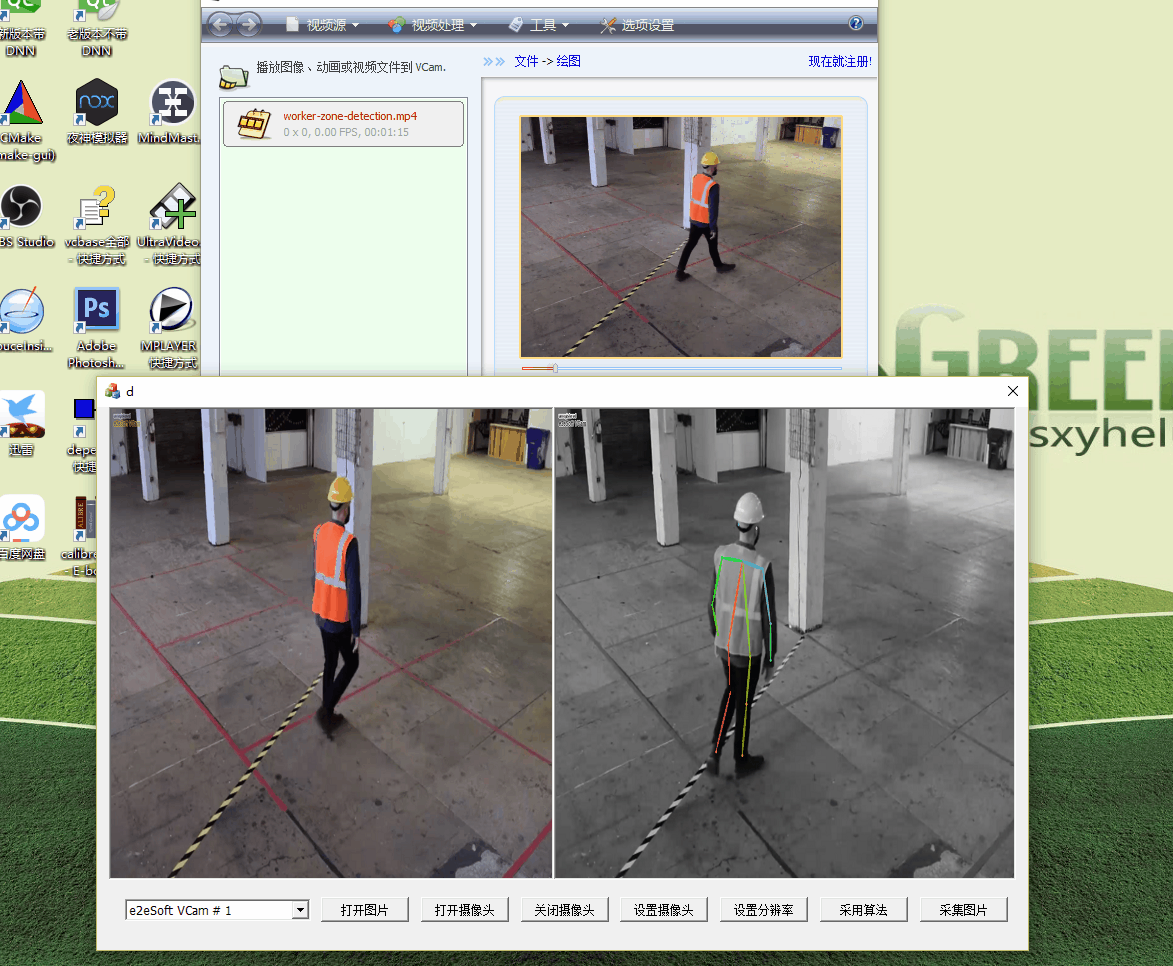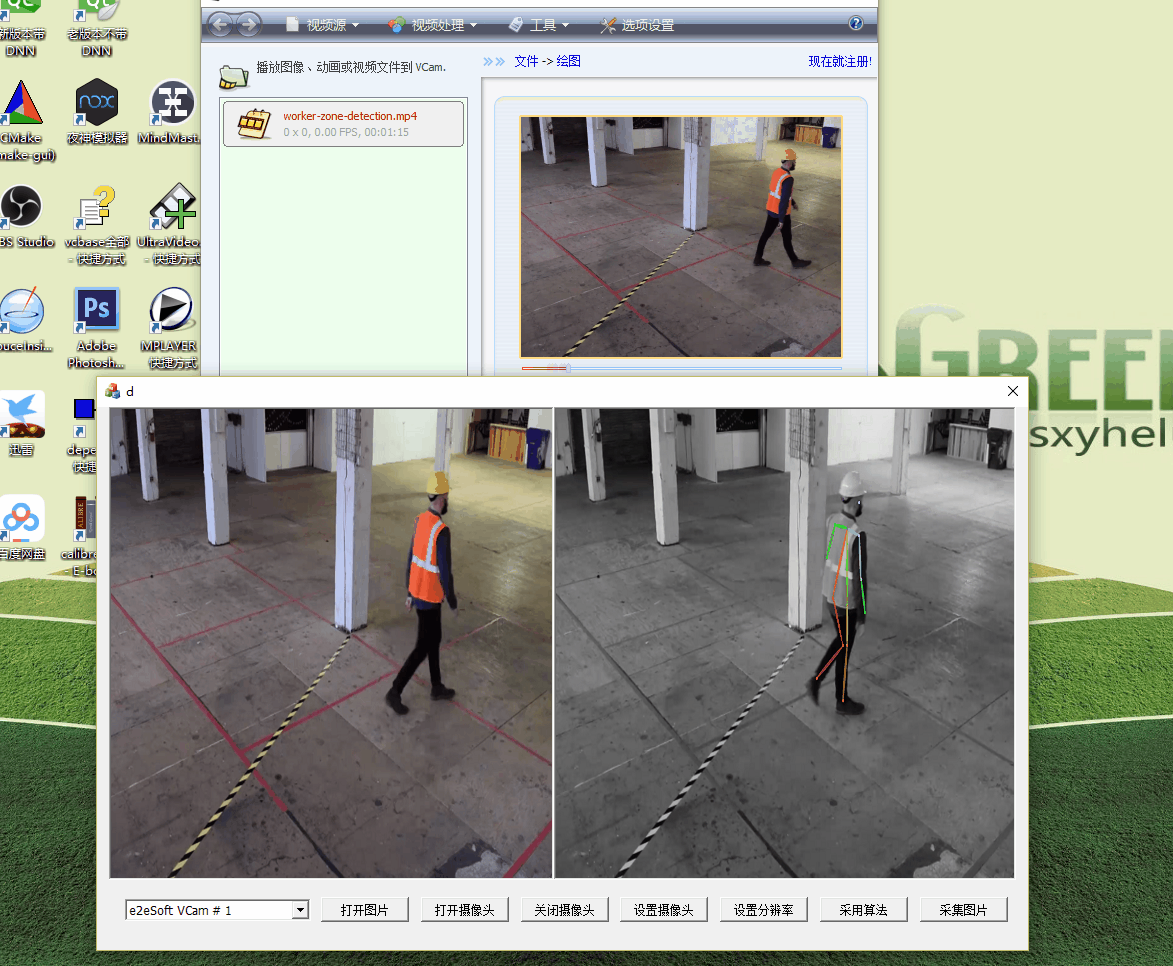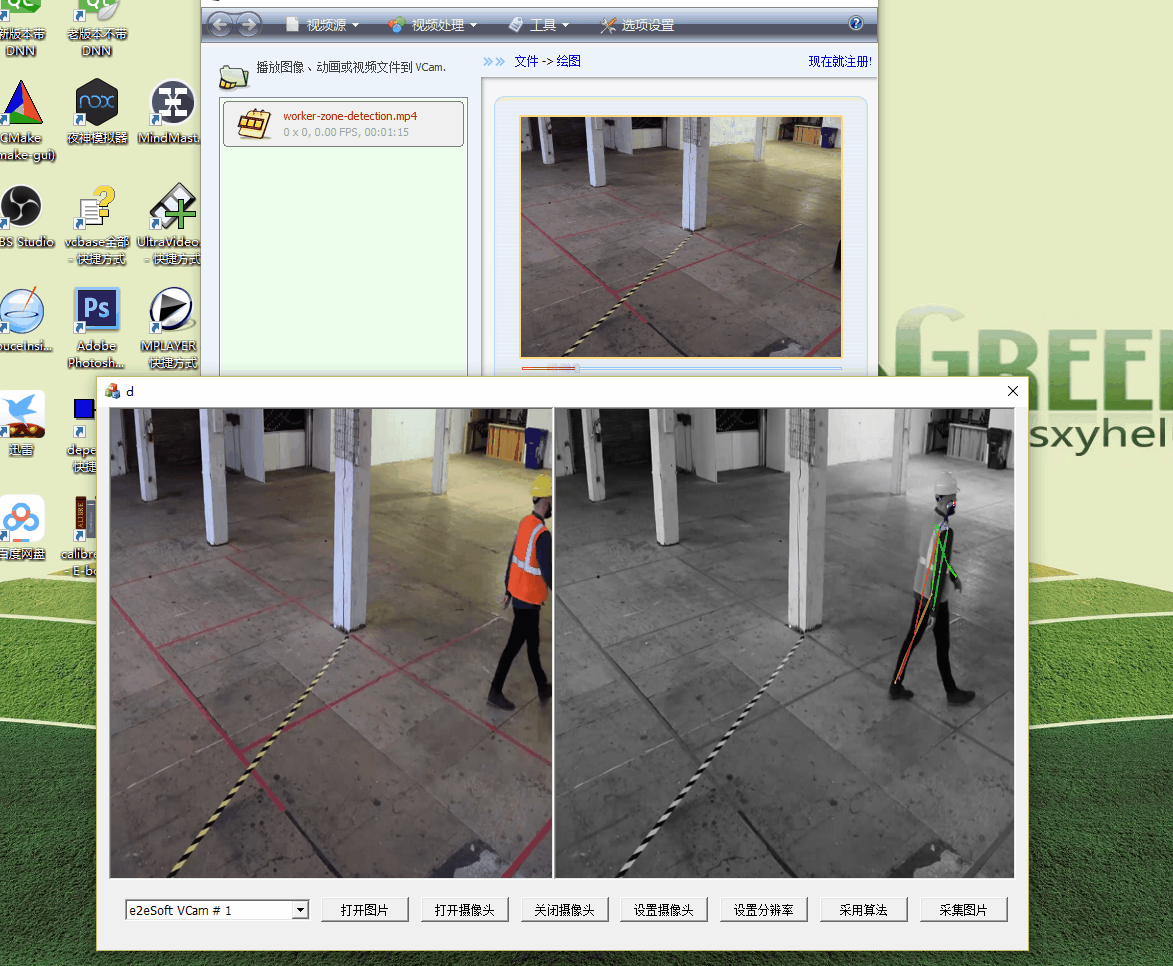
注意,這裏已經將視頻設置成了1920*1080的原始大小。可以看到,最上面的VCam是虛擬攝像頭,它比較流暢,而GOMfctemplate裏面的算法處理也是比較快的,並且DShow自動進行了抽幀處理!原理我還沒有考證,但是結果看上去是這樣的,這也是採用專業基礎庫的紅利吧。
這樣,我就不研究雙線程了……等到後面有需要的時候再研究。這裡實現的功能已經符合我的預期。
4、注意事項
a、因為OpenVINO的原因,所有的項目不要放在有中文和空格的地方;
b、正確設置分辨率進行測試,否則小分辨率測試不出來什麼效果;
c、matU8ToBlob 等函數在引用過來的時候會批量報錯,需要改寫。