滴滴Ceph分佈式存儲系統優化之鎖優化
- 2020 年 9 月 1 日
- 筆記


桔妹導讀:Ceph是國際知名的開源分佈式存儲系統,在工業界和學術界都有着重要的影響。Ceph的架構和算法設計發表在國際系統領域頂級會議OSDI、SOSP、SC等上。Ceph社區得到Red Hat、SUSE、Intel等大公司的大力支持。Ceph是國際雲計算領域應用最廣泛的開源分佈式存儲系統,此外,Ceph也廣泛應用在文件、對象等存儲領域。Ceph在滴滴也支撐了很多關鍵業務的運行。在Ceph的大規模部署和使用過程中,我們發現了Ceph的一些性能問題。圍繞Ceph的性能優化,我們做了很多深入細緻的工作。這篇文章主要介紹我們通過調試分析發現的Ceph在鎖方面存在的問題和我們的優化方法。
1. 背景
在支撐一些延遲敏感的在線應用過程中,我們發現Ceph的尾延遲較差,當應用並發負載較高時,Ceph很容易出現延遲的毛刺,對延遲敏感的應用造成超時甚至崩潰。我們對Ceph的尾延遲問題進行了深入細緻的分析和優化。造成尾延遲的一個重要原因就是代碼中鎖的使用問題,下面根據鎖問題的類型分別介紹我們的優化工作。本文假設讀者已熟悉Ceph的基本讀寫代碼流程,代碼的版本為Luminous。
2. 持鎖時間過長
2.1 異步讀優化
Ceph的osd處理客戶端請求的線程池為osd_op_tp,在處理操作請求的時候,線程會先鎖住操作對應pg的lock。其中,處理對象讀請求的代碼如下圖所示,在鎖住對象所屬pg的lock後,對於最常用的多副本存儲方式,線程會同步進行讀操作,直到給客戶端發送返回的數據後,才會釋放pg lock。
在進行讀操作時,如果數據沒有命中page cache而需要從磁盤讀,是一個耗時的操作,並且pg lock是一個相對粗粒度的鎖,在pg lock持有期間,其它同屬一個pg的對象的讀寫操作都會在加鎖上等待,增大了讀寫延遲,降低了吞吐率。同步讀的另一個缺點是讀操作沒有參與流量控制。
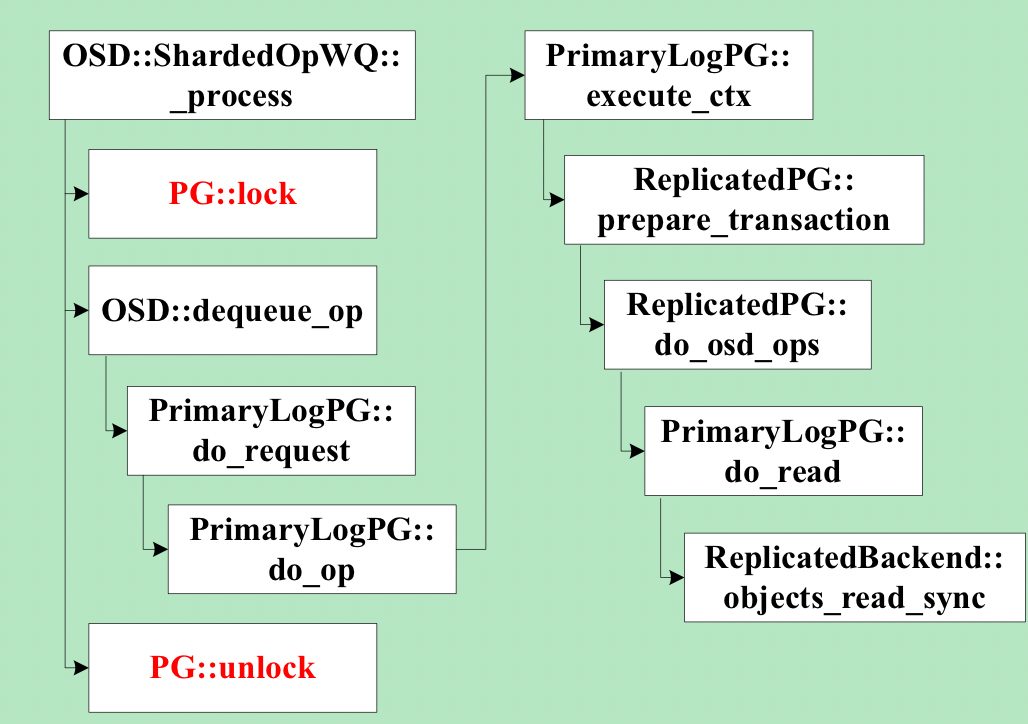
我們對線上集群日誌的分析也驗證了上述問題,例如,一個日誌片段如下圖所示,圖中列舉了兩個op的詳細耗時信息,這兩個op均為同一個osd的線程所執行,且操作的是同一個pg的對象。根據時間順序,第一個op為read,總耗時為56ms。第二個op為write,總耗時為69ms。圖中信息顯示,第二個op處理的一個中間過程,即副本寫的完成消息在處理之前,在osd請求隊列中等待了36ms。結合上圖的代碼可以知道,這36ms都是耗在等待pg lock上,因為前一個read操作持有pg lock,而兩個對象屬於相同pg。

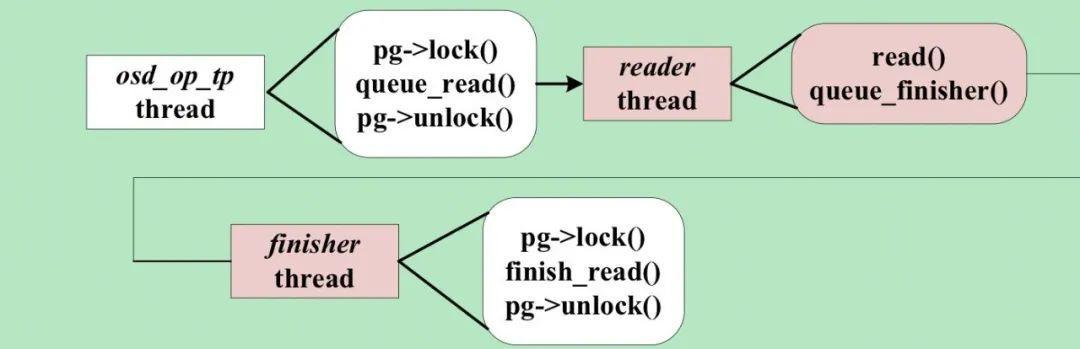
我們的優化如下圖所示,我們創建了獨立的讀線程,負責處理讀請求,osd_op_tp線程只需將讀請求提交到讀線程的隊列即可返回解鎖,大大減少了pg lock的持有時間。讀線程完成磁盤讀之後,將結果放到finisher線程的隊列,finisher線程重新申請pg lock後負責後續處理,這樣將耗時的磁盤訪問放在了不持有pg lock的流程中,結合我們在流量控制所做的優化,讀寫操作可以在統一的框架下進行流量控制,從而精準控制磁盤的利用率,以免磁盤訪問擁塞造成尾延遲。
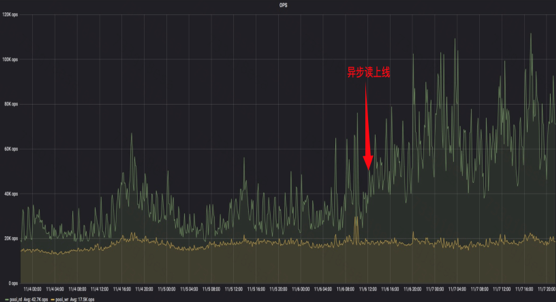
我們用fio進行了異步讀優化效果的測試,測試方法:對同一個pool的兩個rbd,一個做隨機讀,另一個同時做隨機寫操作,將pg number配置為1,這樣所有對象讀寫會落到同一個osd的同一個pg。異步讀優化後,隨機寫平均延遲下降了53%。下圖為某業務的filestore集群異步讀上線前後讀吞吐率的數據,箭頭所指為上線時間,可見上線之後,集群承載的讀操作的吞吐率增加了120%。
上述優化在使用filestore存儲後端時取得了明顯的效果,但在使用bluestore存儲後端時,bluestore代碼中還存在持有pg粒度鎖同步讀的問題,具體見BlueStore::read的代碼。我們對bluestore的讀也進行了異步的優化,這裡就不詳細介紹了。
3. 鎖粒度過粗
3.1 object cache lock優化
Ceph在客戶端實現了一個基於內存的object cache,供rbd和cephfs使用。但cache只有一把大的互斥鎖,任何cache中對象的讀寫都需要先獲得這把鎖。在使用寫回模式時,cache flusher線程在寫回臟數據之前,也會鎖住這個鎖。這時對cache中緩存對象的讀寫都會因為獲取鎖而卡住,使讀寫延遲增加,限制了吞吐率。我們實現了細粒度的對象粒度的鎖,在進行對象的讀寫操作時,只需獲取對應的對象鎖,無需獲取全局鎖。只有訪問全局數據結構時,才需要獲取全局鎖,大大增加了對象間操作的並行。並且對象鎖採用讀寫鎖,增加了同一對象上讀的並行。測試表明,高並發下rbd的吞吐率增加了超過20%。
4. 不必要的鎖競爭
4.1減少pg lock競爭
Ceph的osd對客戶端請求的處理流程為,messenger線程收到請求後,將請求放入osd_op_tp線程池的緩存隊列。osd_op_tp線程池的線程從請求緩存隊列中出隊一個請求,然後根據該請求操作的對象對應的pg將請求放入一個與pg一一對應的pg slot隊列的尾部。然後獲取該pg的pg lock,從pg slot隊列首部出隊一個元素處理。可見,如果osd_op_tp線程池的請求緩存隊列中連續兩個請求操作的對象屬於相同的pg,則一個osd_op_tp線程出隊前一個請求加入pg slot隊列後,獲取pg lock,從pg slot隊列首部出隊一個請求開始處理。另一個osd_op_tp線程從請求緩存隊列出隊第二個請求,因為兩個請求是對應相同的pg,則它會加入相同的pg slot隊列,然後,第二個線程在獲取pg lock時會阻塞。這降低了osd_op_tp線程池的吞吐率,增加了請求的延遲。我們的優化方式是保證任意時刻每個pg slot隊列只有一個線程處理。因為在處理pg slot隊列中的請求之前需要獲取pg lock,因此同一個pg slot隊列的請求是無法並行處理的。我們在每個pg slot隊列增加一個標記,記錄當前正在處理該pg slot的請求的線程。當有線程正在處理一個pg slot的請求時,別的線程會跳過處理該pg slot,繼續從osd_op_tp線程池的請求緩存隊列出隊請求。
4.2 log lock優化
Ceph的日誌系統實現是有一個全局的日誌緩存隊列,由一個全局鎖保護,由專門的日誌線程從日誌緩存隊列中取日誌打印。工作線程提交日誌時,需要獲取全局鎖。日誌線程在獲取日誌打印之前,也需要獲取全局鎖,然後做一個交換將隊列中的日誌交換到一個臨時隊列。另外,當日誌緩存隊列長度超過閾值時,提交日誌的工作線程需要睡眠等待日誌線程打印一些日誌後,再提交。鎖的爭搶和等待都增加了工作線程的延遲。
我們為每個日誌提交線程引入一個線程局部日誌緩存隊列,該隊列為經典的單生產者單消費者無鎖隊列。線程提交日誌直接提交到自己的局部日誌緩存隊列,該過程是無鎖的。只有隊列中的日誌數超過閾值後,才會通知日誌線程。日誌線程也會定期輪詢各個日誌提交線程的局部日誌緩存隊列,打印一些日誌,該過程也是無鎖的。通過上述優化,基本避免了日誌提交過程中因為鎖競爭造成的等待,降低了日誌的提交延遲。測試在高並發日誌提交時,日誌的提交延遲可降低接近90%。
4.3 filestore apply lock優化
對於Ceph filestore存儲引擎,同一個pg的op需要串行apply。每個pg有一個OpSequencer(簡稱osr),用於控制apply順序,每個osr有一個apply lock以及一個op隊列。對於每個待apply的op,首先加入對應pg的osr的隊列,然後把osr加到filestore的負責apply的線程池op_tp的隊列,簡稱為apply隊列。op_tp線程從apply隊列中取出一個osr,加上它的apply lock,再從osr的隊列里取出一個op apply,邏輯代碼如下圖左所示。可見,每個op都會把其對應的osr加入到apply隊列一次。如果多個op是針對同一個pg的對象,則這個pg的osr可能多次加入到apply隊列。如果apply隊列中連續兩個osr是同一個pg的,也就是同一個osr,則前一個op被一個線程進行apply時,osr的apply lock已經加鎖,另一個線程會在該osr的apply lock上阻塞等待,降低了並發度。

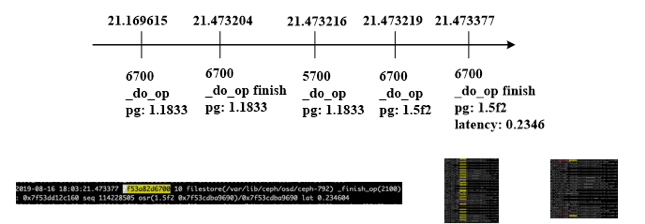
這個問題也體現在日誌中。一個線上集群日誌片段如下圖,有兩個op_tp線程6700和5700,apply隊列里三個對象依次來自pg: 1.1833, 1.1833. 1.5f2。線程6700先拿到第一個對象進行apply, 線程5700拿第二個對象進行apply時卡在apply lock上,因為兩個對象都來自pg 1.1833,直到6700做完才開始apply。而6700拿到第三個對象,即1.5f2的對象進行apply即寫page cache只用了不到1ms,但實際apply延遲234ms,可見第三個對象在隊列里等待了233ms。如果5700不用等待apply lock,則第二和第三個對象的apply延遲可以大大縮短。
我們優化後的邏輯代碼如上圖右所示,同一個osr只加入apply隊列一次,取消apply lock,利用原子操作實現無鎖算法。上面的算法可以進一步優化,在將一個osr出隊之後,可以一次從它的隊列中取m(m>1)個op進行apply,在op apply完成階段,改為如果atomic::fetch_sub(osr->queue_length, m) > m,則將osr重新入隊以提高吞吐率。
我們用fio進行了apply lock優化效果測試,方法為建兩個pool,每個pool的pg number為1,每個pool一個rbd, 對兩個rbd同時進行隨機寫的操作,一個pool寫入數據的量為31k10k,另一個pool寫入數據的量為4k100k, 衡量所有請求apply的總耗時。優化前總耗時434ks, 優化後總耗時45ks,減少89.6%。 ### !

團隊介紹
滴滴雲平台事業群滴滴雲存儲團隊原隸屬於滴滴基礎平台部,現隸屬於新成立的滴滴雲事業部。團隊承擔著公司在線非結構化存儲服務的研發,並參與運維工作。具體來說,團隊承擔了公司內外部業務的絕大部分的對象、塊、文件存儲需求,數據存儲量數十PB。團隊技術氛圍濃厚,同時具備良好的用戶服務意識,立足於用技術創造客戶價值,業務上追求極致。團隊對於分佈式存儲、互聯網服務架構、Linux存儲棧有着深入的理解。
作者介紹

負責滴滴在線非結構化存儲研發,曾任國防科技大學計算機學院副研究員,教研室主任,天河雲存儲負責人
延伸閱讀



內容編輯 | Charlotte
聯繫我們 | [email protected]
滴滴技術 出品

