大數據學習之旅2——從零開始搭hadoop完全分佈式集群
- 2019 年 10 月 3 日
- 筆記
前言
本文從零開始搭hadoop完全分佈式集群,大概花費了一天的時間邊搭邊寫博客,一步一步完成完成集群配置,相信大家按照本文一步一步來完全可以搭建成功。需要注意的是本文限於篇幅和時間的限制,也是為了突出重點,一些很基礎的操作就不再詳細介紹,如果是完全不懂linux,建議先看一下Linux的基礎教程,再進行hadoop配置。同時建議,hadoop安裝版本不宜很高。第一次寫這麼長的博客,希望對大家有所幫助,如果有幫到你,可以點個推薦哦。哈哈。(圖片壓縮的有些模糊,大家諒解一下)
1 安裝linux
篇幅限制,不再介紹,網上很多教程。
1.1添加一個用戶
useradd hduser passwd *****
2配置用戶具有root權限
(1)查看並修改sudoers的文件權限:
首先在root用戶下修改 /etc/sudoers 文件權限,將 只讀 改為 可以修改
修改權限命令
chmod 777 /etc/sudoers
修改前:

修改後:

(2)修改sudoers配置文件
命令
vim /etc/sudoers
添加 haduer權限信息

(3)將sudosers訪問權限恢復440
命令
chmod 440 /etc/sudoers

3創建文件夾module、software
(1)將賬戶切換為新建用戶hduser ,並在/opt目錄下創建文件夾module、software文件夾
module文件夾用於存放解壓後的文件,software文件夾用於存放原始的壓縮文件
命令
su hduser sudo mkdir module sudo mkdir software
(2)創建後修改module、software文件夾的所有者為hduser
修改文件或文件夾所有者命令
sudo chown hduser:hduser module/ software/

原有的rh空文件夾可以刪掉(也可以不刪)
命令 sudo rm -rf rh

4安裝JDK
(1)刪除原有openJDK(如果有的話)
查詢命令 rpm -qa | grep java
卸載命令 sudo rpm -e 軟件名稱
(我這個機器沒發現openJDK就不展示了,但是大多數的linux默認都存在openJDK,需要卸載後再安裝Oracle的JDK)
(2)安裝JDK
JDK安裝有兩種方式,一種直接yum安裝,方便快捷,前提是連着網。
首先執行查看可安裝jdk版本的命令 yum -y list java*
然後選擇自己需要的jdk版本進行安裝,比如安裝JDK1.8,輸入命令
yum install -y java-1.8.0-openjdk-devel.x86_64
然後等待安裝完成即可,輸入 java -version 查看安裝完成後的jdk版本
這個jdk安裝目錄可以在 usr/lib/jvm下找到
第二種就是手動安裝了,也是本文採用的方法
首先在Oracle官網下載jdk,注意下載linux版本,我使用的是jdk-8u144-linux-x64.tar.gz
將jdk複製到Linux中,並將其移動到/opt/software目錄下
移動命令 sudo mv “當前jdk壓縮包的路徑” /opt/software


解壓到/opt/module目錄下
解壓命令 tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
解壓完成後配置jdk環境變量
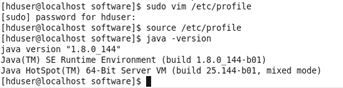
命令 sudo vim /etc/profile
在文件尾部追加jdk路徑,並保存
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin

生效配置文件命令 source /etc/profile
輸入java -version查看是否成功
5安裝hadoop
從官網下載Hadoophttps://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
然後的安裝步驟和安裝jdk步驟基本一樣。
將hadoop-2.7.2.tar.gz複製到Linux中,並移動到/opt/softwate目錄下
移動命令 sudo mv /hadoop-2.7.2.tar.gz /opt/software/
解壓到/opt/module命令 tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
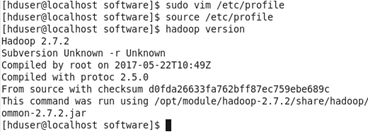
配置hadoop環境變量 sudo vim /etc/profile
在文件末尾添加
##HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin

保存退出後,生效配置文件 source /etc/profile
驗證是否成功 hadoop version
6修改主機靜態IP
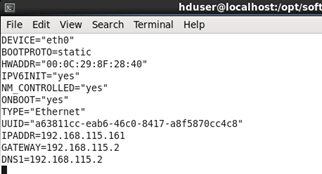
(1)命令 vim /etc/udev/rules.d/70-persistent-net.rules

複製本機的物理IP地址00:0c:29:8f:28:40
(2)命令 sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0 (etho為本機的名字,可以修改,上面的截圖最後一個就是這個名字)
將HDADDR的IP改為之前複製的那個IP(如果沒這個HDADDR項,那就跳過,不用改了)
將BOOTPROTO項改為static靜態獲取,將ONBOOT改為yes,那麼開機自動生效
添加IPADDR項並設置為192.168.115.161(當然你完全可以設置為其他的靜態IP)
添加GATEWAY項並設置為192.168.115.2(這個為網關,根據你的IP設置相應的網關,前三個如:192.168.115和設置的IP前三個要一樣,最後一位一般都設為2)
添加DNS1並設置為
7修改主機名稱
命令 sudo vim /etc/sysconfig/network
為hadoop201 (你也可以設為其他名字)

保存後,可以輸入hostname查看本機的主機名(hostname在重啟後生效,當然也有其他生效方式,reboot重啟最簡單)
8配置hosts文件
配置hosts文件,方便以後的集群操作
輸入命令 sudo vim /etc/hosts
在文件末尾追加
192.168.115.161 hadoop201
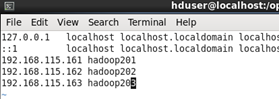
(集群最少要有三個節點,我就順便把要裝的其他的節點也加上了)
9關閉防火牆
關閉防火牆,方便遠程操控(不同版本命令有所不同,可以上網百度一下, centos6和centos7命令有些區別)
關閉防火牆命令: systemctl stop firewalld.service
關閉開機啟動: systemctl disable firewalld
執行完以上8步驟後可以reboot重啟一下,這樣基礎的準備工作就完成了。
如果使用的是虛擬機的話,就將配置好的一個虛擬機完全克隆一下,克隆2個新節點,克隆完成後只需要修改新節點的靜態IP和修改hostname名就行了(使用克隆節點修改靜態IP時,注意vim /etc/udev/rules.d/70-persistent-net.rules編輯時要刪掉多餘的之前的IP設置,並將文件末尾NAME=”eth1”這樣的名字改為NAME=”eth0”)
如果是真實主機的話,就重複上述8個步驟,再新建兩個節點
有三個節點後,下面開始進行集群配置
10配置集群
建議使用root賬號登錄
首先在第一台機器上配置
(1)配置hadoop-env.sh
首先進入/opt/module/hadoop-2.7.2目錄下 cd /opt/module/hadoop-2.7.2
修改JAVA_HOME路徑
命令 vim etc/hadoop/hadoop-env.sh
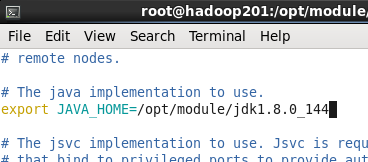
(2)配置core-site.xml
命令與上面相似 vim etc/hadoop/core-site.xml
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop201:9000</value> </property> <!-- 指定Hadoop運行時產生文件的存儲目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
(3)配置hdfs.site.xml
<!-- 指定HDFS副本的數量 --> <property> <name>dfs.replication</name> <value>3</value> </property>
上述配置在第一台機器上完成後,其他機器暫時不用管
11 SSH無密登錄配置
(1)生成公鑰私鑰
在第一台機器上使用 hduser賬號登錄
修改配置 vim /etc/ssh/sshd_config
找到以下三行,去除注釋保存
#RSAAuthentication yes #PubkeyAuthentication yes #PermitRootLogin yes
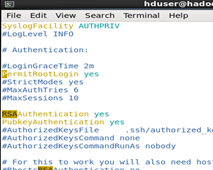
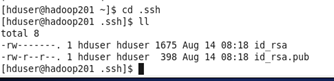
然後在任意目錄下輸入命令
ssh-keygen -t rsa
回車3次,生成公鑰和私鑰
(2)將公鑰拷貝到要免密登錄的目標機器上
ssh-copy-id hadoop201 ssh-copy-id hadoop202 ssh-copy-id hadoop203
(分發密鑰過程中需要輸入yes和對應目標機器的密碼)
hadoop201剛剛使用的是hduser賬號生成和分發的密鑰,切換賬號為root再進行一次生成密鑰和分發密鑰
同樣在即將配置為yarn節點的hadoop202主機採用hduser賬號配置無密登錄到hadoop201、hadoop202、hadoop203節點
以上操作是為了後續集群群起做鋪墊
(3)編寫xsync腳本(用於文件同步)
hadoop201上,在在/home/atguigu目錄下創建bin目錄,並在bin目錄下xsync創建文件,
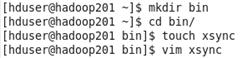
文件內容如下:
#!/bin/bash #1 獲取輸入參數個數,如果沒有參數,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 獲取文件名稱 p1=$1 fname=`basename $p1` echo fname=$fname #3 獲取上級目錄到絕對路徑 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 獲取當前用戶名稱 user=`whoami` #5 循環 for((host=201; host<204; host++)); do echo ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done
然後修改腳本 xsync 具有執行權限 命令
chmod 777 xsync
12同步文件
首先將xsync腳本文件分發到其他節點
命令
xsync /home/hduser/bin
注意:如果將xsync放到/home/atguigu/bin目錄下仍然不能實現全局使用,可以將xsync移動到/usr/local/bin目錄下。
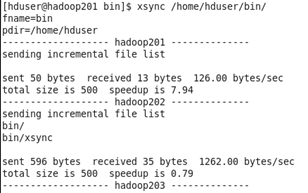
(1)在hadoop201上操作,將hosts文件分發給其他節點(如果是虛擬機克隆的話,hosts裏面有節點信息就不用分發了)
xsync /etc/hosts
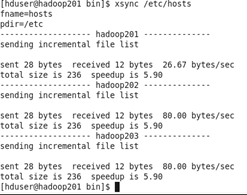
(2)配置slaves
首先進入目錄 cd /opt/module/hadoop-2.7.2/ 下
命令 vim etc/hadoop/slaves
在文件中增加下列內容
hadoop102 hadoop103 hadoop104
(注意:slaves文件內不允許有空格,如果有的話會導致一些節點群起失敗)
(注意2:配置slaves文件的前提是hosts文件已經有了這些節點的信息)
分發slaves配置文件 xsync etc/hadoop/slaves

13集群配置
還是在hadoop201上操作,然後把文件分發給其他節點,以減少工作量
(1)集群部署規劃
|
|
Hadoop201 |
Hadoop202 |
Hadoop203 |
|
HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
(2)配置集群
首先 cd /opt/module/hadoop-2.7.2/ 進入hadoop安裝目錄下
配置core-site.xml
命令 vim etc/hadoop/core-site.xml
在文件中編寫如下配置
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop201:9000</value> </property> <!-- 指定Hadoop運行時產生文件的存儲目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
配置hadoop-env.sh
命令 vim etc/hadoop/hadoop-env.sh
修改JAVA_HONE路徑 export JAVA_HOME=/opt/module/jdk1.8.0_144 (較詳細操作看第10小節)
配置hdfs-site.xml
命令 vim etc/hadoop/hdfs-site.xml
在文件中編寫如下配置
<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop輔助名稱節點主機配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop203:50070</value> </property>
配置yarn-env.sh
命令 vim etc/hadoop/yarn-env.sh
修改JAVA_HOME目錄(去掉注釋修改目錄)
export JAVA_HOME=/opt/module/jdk1.8.0_144 (詳情參考第10小節)
配置yarn-site.xml
命令 vim etc/hadoop/yarn-site.xml
在文件中增加下列配置
<!-- Reducer獲取數據的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop202</value> </property>
配置mapred-env.sh
(參考第10小節)
配置mapred-site.xml
首先修改文件名稱
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
再進行配置命令 vim etc/hadoop/mapred-site.xml
在文件中加入下列配置
<!-- 指定MR運行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
(3)集群文件配置好後分發配置文件
命令
xsync /opt/module/hadoop-2.7.2/
14集群群起
終於來到了激動人心的環節,集群群起(也就是一下啟動整個集群)
(1)如果集群是第一次啟動,需要格式化namenode (在格式化前,一定要停止上次啟動的所有namenode和datanode進程,然後再刪除hadoop安裝目錄下的data和log數據)
格式化命令
bin/hdfs namenode -format
每個節點都格式化一遍
(注意不要隨便格式化集群哦)
(2)啟動HDFS
在hadoop201上群起HDFS
群起命令
sbin/start-dfs.sh
查看當前節點啟動的項目
命令
jps
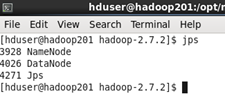
然後在hadoop202上啟動yarn
群起命令
sbin/start-yarn.sh
集群完全啟動後各節點的狀態如下
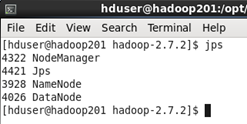

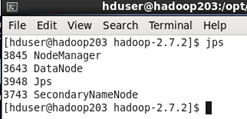
這樣整個集群就成功啟動了
如果要停止集群
在hadoop201上停止集群的hdfs命令
sbin/stop-dfs.sh
在hadoop202上停止集群yarn命令
sbin/stop-yarn.sh
15瀏覽器查看集群狀態
(前提瀏覽器那個主機的hosts有這些節點的信息,不然就老老實實輸入ip地址,如:把hadoop201替換為192.168.115.161)
在瀏覽器中輸入 http://hadoop201:50070 查看namenode狀態
輸入 http://hadoop201:50075 查看datanode狀態
輸入 http://hadoop203:50070 查看secondarynamenode狀態
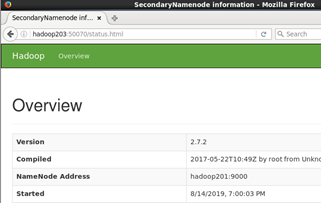
後續:
hadoop集群搭建完後,真正生產環境中還需要同步集群時間,操作集群時一般都是通過遠程終端(如xshell、SecureCRT等終端軟件ssh登錄)操控,這些大家可以查看一下相關博客,還是比較簡單的。
如果要轉載的話,大家註明一下轉載鏈接即可。
