CSAPP =1= 計算機系統漫遊
思維導圖
預計閱讀時間:15min
閱讀書籍 《深入理解計算機系統》
參考視頻 【精校中英字幕】2015 CMU 15-213 CSAPP 深入理解計算機系統 課程視頻
參考文章 《深入理解計算機系統(1.1)—計算機概述》
《深入理解計算機系統(1.2)—hello world的程序是如何運行的》
《深入理解計算機系統(1.3)—金字塔形的存儲設備、操作系統的抽象概念》
原文鏈接 《旻天:
譯序
《深入理解計算機系統》最大的優點是為程序員描述計算機系統的實現細節,幫助其在大腦中構建一個層次型的計算機系統。從最底層的數據在內存中的表示(如整數、浮點數表示),到流水線指令的構成,之後到虛擬存儲器,編譯系統,動態加載庫,再到最後的用戶態應用。
貫穿本書的一條主線是使程序員在設計程序時,能充分意識到計算機系統的重要性,建立起被所寫的程序可能被執行的數據和指令的流程圖,明白當程序的執行過程中,計算機到底都發生了什麼事。從而能夠設計出一個高效的、可移植的、健壯的程序。並能夠更快地對程序進行排錯、性能調優等。
本書的主要內容是關於計算機體系結構(高級硬件設計)與編譯器和操作系統的交互,包括:
- 數據表示
- 彙編語言和彙編計算機體系結構
- 處理器設計
- 程序的性能度量和優化
- 程序的加載器、鏈接器和編譯器
- I/O 和設備的存儲器層次結構
- 虛擬存儲器
- 外部存儲管理
- 中斷、信號和進程控制
計算機系統就像自然界的生態環境一樣,對每一個部分的設計都要求它能融洽地和系統內其他部分和平相處,我們不能站在一個微觀的視角去判斷某個系統部件是否最優,而是應該以計算機這個宏觀的整體來觀察和思考。
一、計算機系統漫遊
我們將通過跟蹤 hello.c 程序的生命周期來對計算機系統有個簡單的了解。它的生命周期從它被程序員創建開始,包括在系統上保存、運行、在屏幕上輸出信息到最後的程序終止。
1.1 信息就是位(bit) + 上下文(context)
hello.c 程序的生命是從一個源程序(或者叫源文件)開始的,該源文件由程序員編寫,並保存為hello.c的一個由 ASCII 構成的文本文件。
這個 hello.c 也說明了一個基本的思想:系統中所有的信息,包括磁盤文件、存儲器中的程序、存儲器中的數據以及網絡上傳輸的數據,都是由一串比特(bit,或者叫做位)序列表示的,這些比特 8 個為一組,稱為位元組。
同樣的位元組序列可能表示一個整數、浮點數、字符串或者機器指令,而區分不同數據對象的唯一方法就是它們所在的上下文(context),在不同語境中表示不同的意義。
1.2 程序被其他程序翻譯成不同的格式
編程語言的設計是為了讓人可以讀懂,然而為了讓計算機可以運行這個 C 程序,就需要將每條有效的語句轉換成一系列的低級機器語言指令,並以二進制磁盤文件的形式存放起來。
在 Unix 系統中,從源文件到可執行文件的轉化是由編譯器驅動程序完成的。
unix> gcc -o hello hello.c
編譯器驅動程序的執行過程如下:
hello.c == 預處理器 ==> hello.i == 編譯器 ==> hello.s == 彙編器 ==> hello.o + printf.o == 鏈接器 ==> hello
源程序(文本文件) (cpp) 預處理程序 (ccl) 彙編語言(文本文件) (as) 可重定位目標文件(二進制) (ld) 可執行文件
- 預處理階段:預處理器(cpp)根據以
#開頭的命令,修改原始的 C 程序。如將#include <stdio.h>中引用的頭文件stdio.h的內容插入到程序的開頭,來得到一個新的 C 程序。 - 編譯階段:編譯器(ccl)將預處理程序
hello.i翻譯成彙編程序hello.s。彙編語言程序中的每條語句都以一種標準的文本格式確切的描述了一條低級機器語言指令。彙編語言為不同高級語言的不同編譯器提供了通用的輸出語言。 - 彙編階段:彙編器(as)將
hello.s翻譯成機器語言指令集合。並以可重定位目標程序的格式,將結果保存到hello.o的二進制文件中。 - 鏈接階段:如果程序調用了一下標準 C 庫中的函數,如
printf, 而該函數存在於一個單獨的名為printf.o的可重定位目標程序文件中。因此就必須以某種方式將其併入到我們的hello.o文件中並得到最終的可執行目標文件hello。
1.3 了解編譯系統如何工作是大有益處的
對於像 hello.c 這樣的簡單程序,我們可以依靠編譯系統生成正確有效的機器代碼。但還是有一些重要的原因促使程序員必須知道編譯系統是如何工作的。
- 優化程序性能:比如,
- (開關)一個 switch 是不是總比一系列的 if-then-else 語句要高效?
- (循環)while循環比do循環更有效嗎?
- (數組&指針)指針引用比數組索引更有效嗎?
- (函數)一個函數調用的代價有多大?
- (參數)相對於通過引用傳遞過來的參數求和,為什麼用本地變量求和的循環會快很多倍?
- 為什麼兩個功能相近的循環,運行時間會有巨大差異?
- 理解鏈接時出現的錯誤:比如,
- (引用)鏈接器報告說它無法解析一個引用。
- (變量)靜態變量和全局變量的區別。
- (作用域)在不同的文件中定義相同名字的兩個全局變量會怎樣。
- (鏈接庫)靜態庫和動態庫的區別。
- 為什麼命令行上排列庫的順序會對程序有影響。
- 為什麼有些鏈接錯誤直到運行時才出現。
- 避免安全漏洞:近年來的緩衝區溢出錯誤造成了大多數網絡和服務器上的安全漏洞。錯誤原因大多是程序員忽視了編譯器用來為函數產生代碼的堆棧規則。
1.4 處理器讀並解釋存儲在存儲器中的指令
之前編寫的 hello 程序,源碼和可執行文件都已經存放在了磁盤上。執行我們之前編寫的 hello 小程序,就可以在 shell 中看到程序的輸出:
unix> ./hello
hello, world
存放在磁盤的程序是如何運行,並在 shell 中打印信息的呢?這時就需要理解一個典型系統的硬件組織。
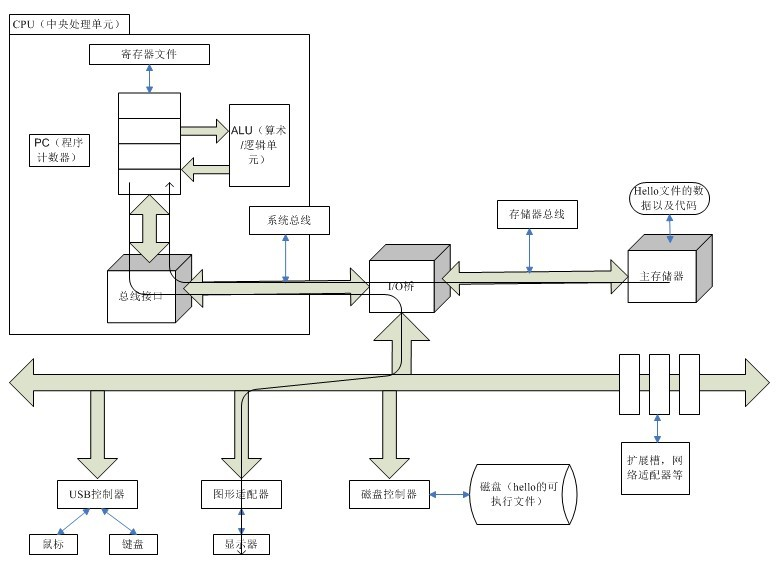
1.4.1 系統的硬件組成
如圖展示的是 Inter Pentium 系統產品組的模型,但和其他系統也都大同小異。
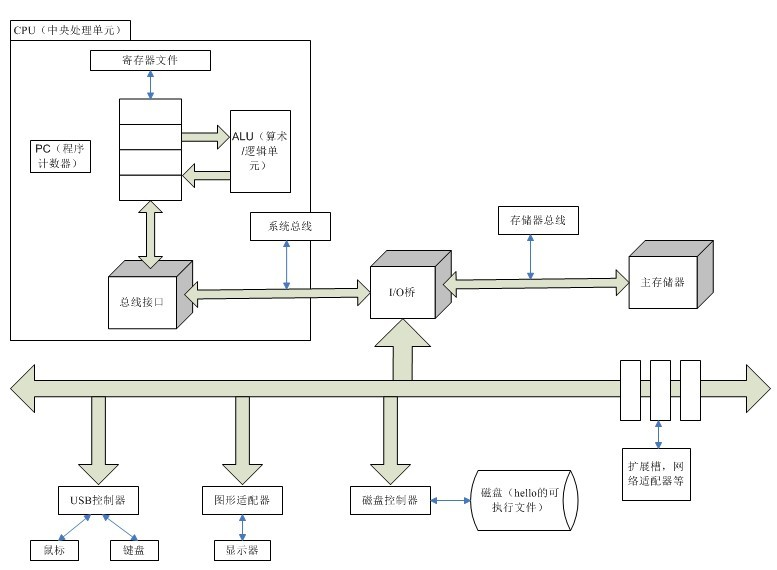
- CPU: 中央處理單元
- ALU:算術/邏輯單元
- PC:程序計數器
- USB:通用串行總線
總線
貫穿整個系統的一組電子管道,稱作總線。它攜帶信息位元組並負責在各個部件間傳遞。
通常總線被設計成傳遞定長的位元組塊,也就是字(word)。字中的位元組數(即字長)是一個基本的操作系統參數。
像我們平時買電腦說的 64 位處理器,指的就是 CPU 總線字長為 8 位元組(64 位)的 CPU。而裝系統時的 64 位操作系統,指的是可以完全的利用 CPU 64 位尋址能力的操作系統,當然也可以在 64 位 CPU 的機器上裝 32 位的操作系統,只不過會大大浪費 CPU 尋址能力。
I/O 設備
I/O(Input/Output,輸入/輸出)設備是系統與外界聯繫的通道。如用戶用來輸入的鼠標、鍵盤;系統用來給用戶輸出信息的顯示器;以及長期存儲用戶程序和數據的磁盤驅動器。
每個 I/O 設備都是通過一個控制器或適配器與 I/O 總線連接起來的。區別是控制器是 I/O 設備本身或系統主電路板上的芯片組。而適配器則是一塊插在主板插槽上的卡。
主存
主存是一個臨時存儲設備。在處理器執行程序時,它被用來存放程序和數據。
物理上來說,主存就是一組 DRAM(動態隨機存取存儲器)芯片組成。
邏輯上來說,存儲器是由一個線性的位元組數組組成的,每個位元組都有自己唯一的地址(從 0 開始的數組索引)。
一般來說,組成程序的每條機器指令都由不定量的位元組構成,每種語言也有所不同。比如,運行在 Inter 上的 Linux 機器中,short 類型數據為 2 個位元組,而 int、float 為 4 個位元組。
處理器
中央處理單元(CPU)簡稱處理器,是解釋(或執行)存儲在主存中指令的引擎。
處理器細分,又有:
程序計數器(PC)
處理器的核心是程序計數器(PC)的字長大小的存儲設備(或寄存器)。在任何時間點上,PC 都指向主存中的某條機器語言指令的地址。
從系統啟動開始直至斷電,處理器都在重複執行相同的簡單任務,即:
- 從 PC 當前指向的地址處讀取指令
- 解釋指令中的位
- 執行指令指示的簡單操作
- 更新 PC 到下一條指令(兩條指令並不一定相鄰)
- 重複執行 1.
寄存器文件
寄存器文件是一個很小的高速存儲設備,由一些字長大小的寄存器組成。這些寄存器每個都有唯一的名字。
算術邏輯單元(ALU)
ALU 計算新的數據和地址值。
處理器在指令的要求下可能會有以下操作:
- 加載:從主存拷貝一個位元組或一個字到寄存器,並覆蓋寄存器原來的值
- 存儲:從寄存器拷貝一個位元組或一個字到主存某個位置,並覆蓋原來的值
- 更新:拷貝兩個寄存器的值到 ALU,ALU將兩數相加並將結果存放到一個寄存器中,並覆蓋原來的值
- I/O 讀:從 I/O 設備中拷貝一個位元組或者一個字到寄存器
- I/O 寫:從寄存器中拷貝一個位元組或一個字到一個 I/O 設備
- 轉移:從指令本身抽取一個字,並將這個字拷貝到 PC 中,並覆蓋原來的值
1.4.2 執行 hello 程序流程
現在我們已經初步了解了程序的編譯過程和計算機硬件的組成,但一台計算機又是如何執行 hello 這個可執行文件的呢?
大體流程可以參考左瀟龍大佬重繪的這版高清圖片:
1.shell 監聽用戶輸出,字符從輸入設備經由總線到寄存器,在從寄存器保存到主存,並在接受到回車後執行相關指令
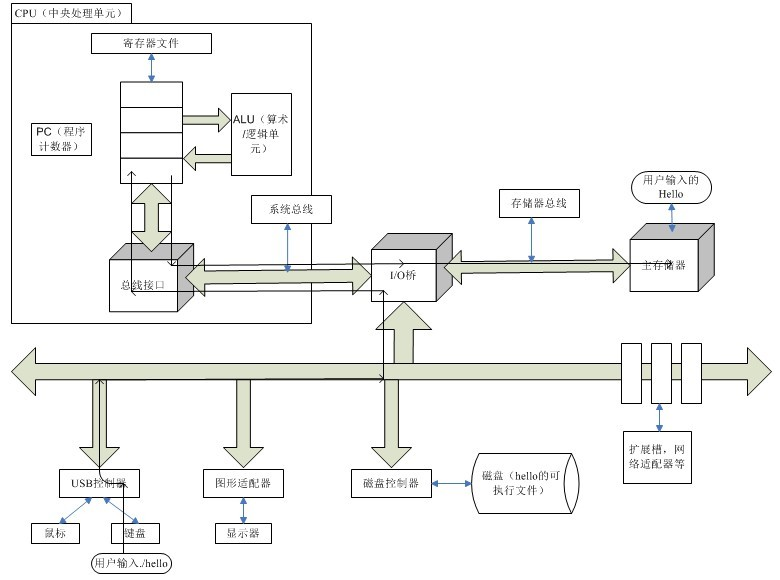
2.shell 執行一系列指令,將 hello 可執行文件的代碼和數據經過總線和 I/O 橋從磁盤 copy 到主存,完成程序的加載(可以利用 DMA 繞過 CPU 直接將硬盤數據加載進主存)
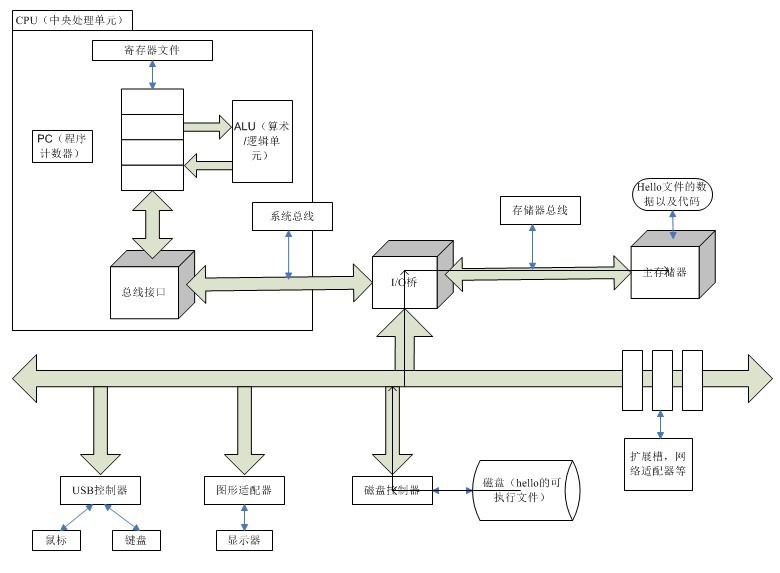
3.CPU 通過總線將主存中的指令逐條加載進 CPU 並翻譯程序指令,對於需要打印的字符,通過總線傳遞給顯示器顯示
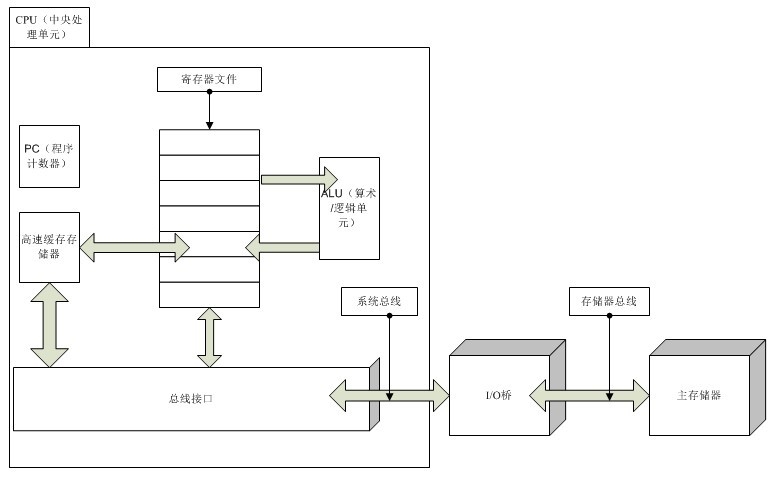
1.5 高速緩存
從上面例子我們可以看到,系統有大量的數據移動操作。比如開始的 hello 執行程序存放在磁盤上,之後程序加載被拷貝到主存,然後程序執行又把程序逐條拷貝到處理器,而對於其中的打印字符,又把字符拷貝到了顯示器終端。因此對於這幾步拷貝的次數和速度還是有很大的優化空間的。
硬件開發商為了減少這種數據傳輸的時間成本,而高速緩存應運而生。
高速緩存被放置在處理器當中,與處理器中的寄存器文件直接進行數據交換,這樣大大減少了數據傳輸的時間成本,使得程序的運行速度可以得到數倍的提升。
1.6 形成層次結構的存儲設備
計算機領域有句名言:「計算機科學領域的任何問題都可以通過增加一個間接的中間層來解決」。
而在處理器和較慢的存儲器中間插入一個更快的存儲器這種想法也成為了一個普遍的概念。但硬件廠商經不起一個真理《越快的設備造價越高昂》,所以就需要在更快和更大之間產生一個平衡。
所以存儲結構就變成了如下的金字塔結構。
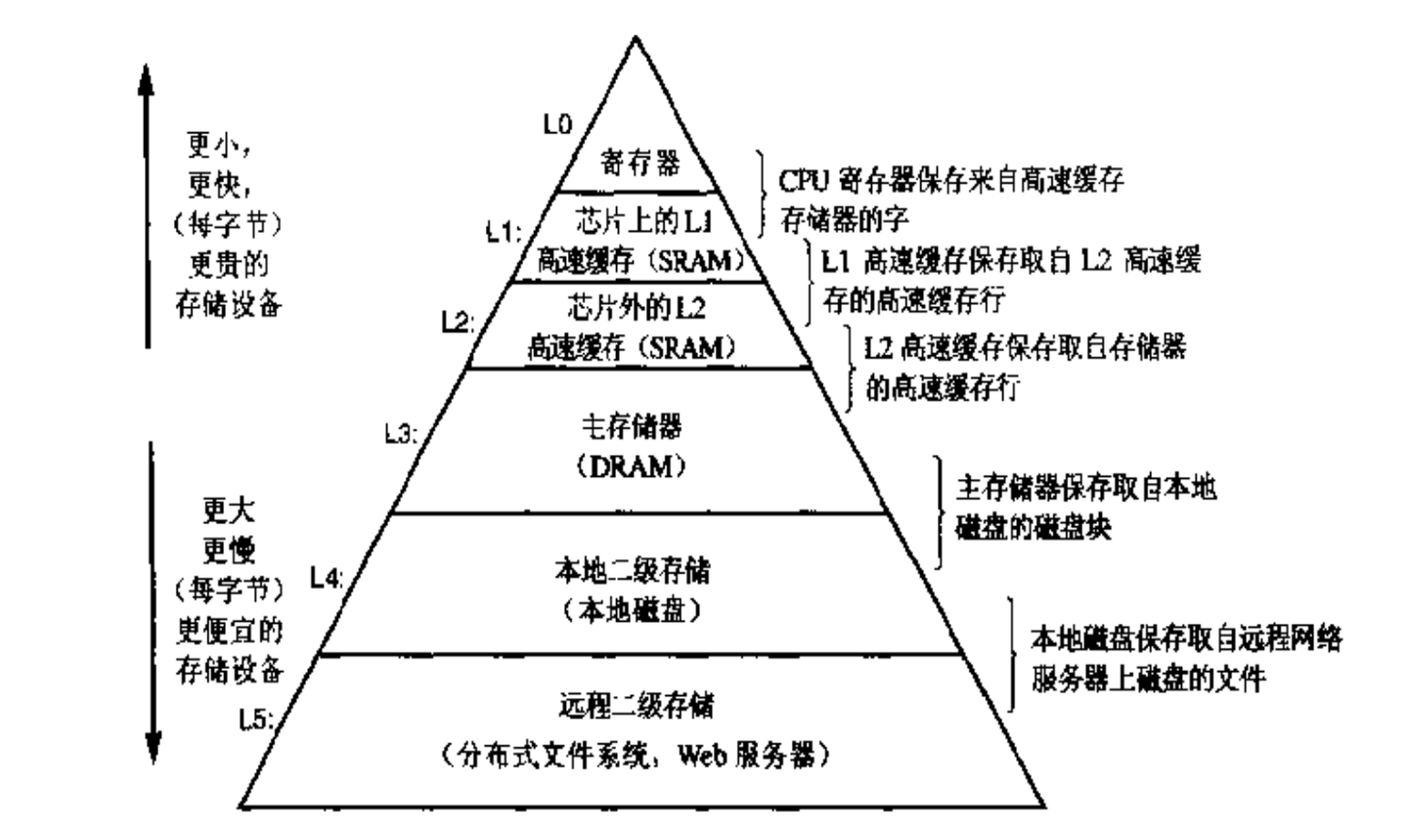
越靠近CPU的設備越小越快,但造價越高昂。
越遠離CPU的設備越大越慢,但造價越便宜。
1.7 操作系統管理硬件
為了簡化程序開發者使用硬件資源,計算機又產生了一個新的中間件 ———— 操作系統。
操作系統就是幫助應用軟件控制系統硬件的系統軟件,在應用軟件和系統硬件之間扮演者一個協調和管理的角色。
1.7.1 分層視圖
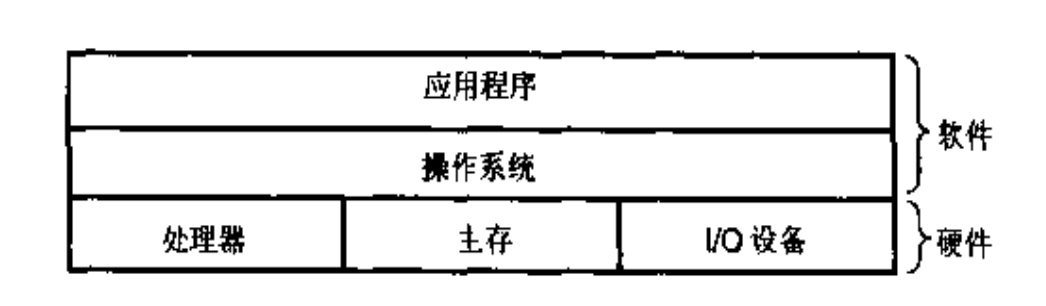
1.7.2 基本功能
- 防止硬件被失控(非法)的應用程序濫用,保護計算機
- 為不同硬件提供一套簡單一致的接口
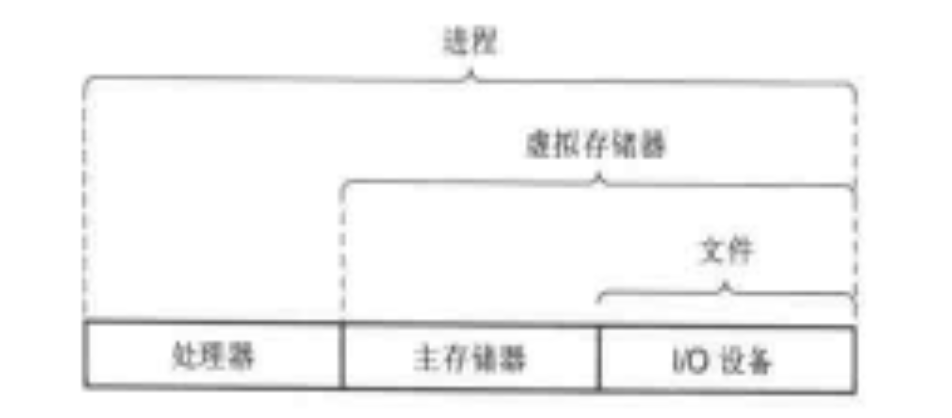
文件
文件是操作系統對硬件中 I/O 設備的抽象,它只是一組位元組序列。任何 I/O 設備,如磁盤、鍵盤、顯示器、甚至網絡都可以看成是一個文件。
虛擬存儲器
虛擬存儲器是一個抽象概念,為每個進程提供一個好似獨佔了主存的假象。由主存和文件組成。
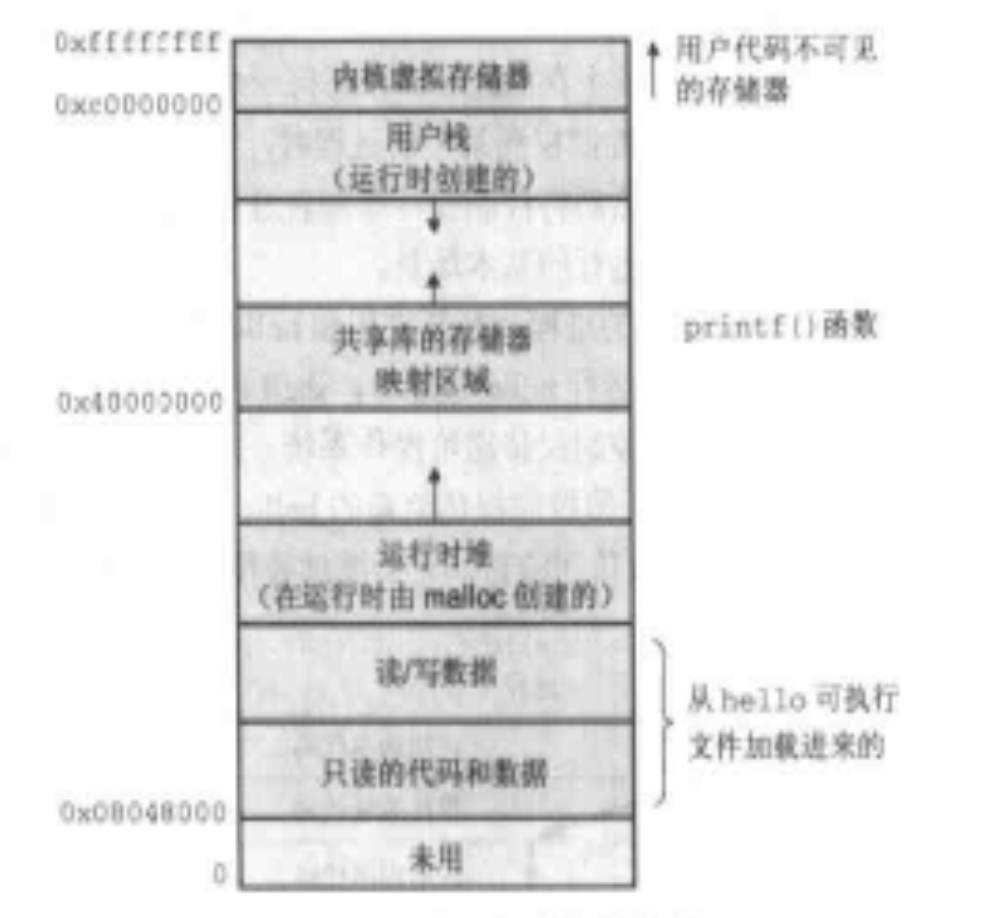
可以看到虛擬存儲器有五個區域構成,從下往上(地址從小往大)依次是:
程序代碼和數據(只讀和讀寫兩部分)
就是程序代碼和數據,全局變量
運行時堆
是運行時可以動態擴展的一部分內存區域,它可以由malloc和free這樣的標準庫函數操作
共享庫存儲
用於存放共享庫的代碼和數據
用戶棧
與函數的執行有密切的關係
內核虛擬存儲
內核是操作系統的一部分
進程
進程是操作系統對一個正在運行的程序的抽象,為程序提供一個好似獨佔了整個計算機的假象。由處理器和虛擬存儲器組成。
但實際上一個計算機會有多個進程同時執行,我們稱之為並發運行。每個進程交替獲得 CPU 時間並執行響應指令。
操作系統實現這種交錯執行的機制稱之為上下文切換(context switching)。而保存進程所需的所有狀態信息就稱為上下文(context)。
線程
在現代系統中,一個進程實際上可以由多個稱為線程的執行單元組成。每個線程都運行在進程的上下文中,並共享同樣的代碼和全局數據。
線程可以比進程更容易的共享數據,因此也更加高效。
1.8 利用網絡系統和其他系統通信
目前我們一直將系統視為一個孤立的個體,但實際上現代計算機經常通過網絡和其他系統連接到一起。
而前面我們也說過,網絡本就可以視為是一個 I/O 設備,它也可以被看做是一系列的位元組序列。網絡適配器的作用就是給計算機輸入一堆被傳送過來的位元組序列,這裏面可能包括圖片、文字,甚至可能是代碼等等。
總結
計算機是由硬件和軟件共同組成的。
軟件是由程序指令和數據組成的,由最初的 ASCII 文本逐步翻譯成可執行文件,可執行文件在計算機都是以二進制的形式保存的,二進制指令依據不同的上下文有不同的解釋方式。
操作系統將存在磁盤中的程序加載到主存中,CPU 再讀取並解釋主存中的二進制指令,產生程序期望的硬件效果。
因為計算機花費大量時間在存儲器和 I/O 設備到 CPU 之間的數據拷貝上,所以形成了金字塔模式的存儲模型。
操作系統內核是應用程序和硬件之間的媒介,通過操作系統提供的抽象接口,方便應用程序可以控制不同廠商的同種硬件。
完
《本章完》,期待各位道友指出文章的不足之處。
轉載請註明出處~~


