主成分分析PCA數據降維原理及python應用(葡萄酒案例分析)
目錄
主成分分析(PCA)——以葡萄酒數據集分類為例
1、認識PCA
(1)簡介
數據降維的一種方法是通過特徵提取實現,主成分分析PCA就是一種無監督數據壓縮技術,廣泛應用於特徵提取和降維。
換言之,PCA技術就是在高維數據中尋找最大方差的方向,將這個方向投影到維度更小的新子空間。例如,將原數據向量x,通過構建 維變換矩陣 W,映射到新的k維子空間,通常(
)。
原數據d維向量空間 經過
,得到新的k維向量空間
.
第一主成分有最大的方差,在PCA之前需要對特徵進行標準化,保證所有特徵在相同尺度下均衡。
(2)方法步驟
- 標準化d維數據集
- 構建協方差矩陣。
- 將協方差矩陣分解為特徵向量和特徵值。
- 對特徵值進行降序排列,相應的特徵向量作為整體降序。
- 選擇k個最大特徵值的特徵向量,
。
- 根據提取的k個特徵向量構造投影矩陣
。
- d維數據經過
下面使用python逐步完成葡萄酒的PCA案例。
2、提取主成分
下載葡萄酒數據集wine.data到本地,或者到時在加載數據代碼是從遠程服務器獲取,為了避免加載超時推薦下載本地數據集。
來看看數據集長什麼樣子!一共有3類,標籤為1,2,3 。每一行為一組數據,由13個維度的值表示,我們將它看成一個向量。
開始加載數據集。
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# load data
df_wine = pd.read_csv('D:\\PyCharm_Project\\maching_learning\\wine_data\\wine.data', header=None) # 本地加載,路徑為本地數據集存放位置
# df_wine=pd.read_csv('//archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)#服務器加載
下一步將數據按7:3劃分為training-data和testing-data,並進行標準化處理。
# split the data,train:test=7:3
x, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y, random_state=0)
# standardize the feature 標準化
sc = StandardScaler()
x_train_std = sc.fit_transform(x_train)
x_test_std = sc.fit_transform(x_test)
這個過程可以自行打印出數據進行觀察研究。
接下來構造協方差矩陣。 維協方差對稱矩陣,實際操作就是計算不同特徵列之間的協方差。公式如下:
公式中,jk就是在矩陣中的行列下標,i表示第i行數據,分別為特徵列 j,k的均值。最後得到的協方差矩陣是13*13,這裡以3*3為例,如下:
下面使用numpy實現計算協方差並提取特徵值和特徵向量。
# 構造協方差矩陣,得到特徵向量和特徵值
cov_matrix = np.cov(x_train_std.T)
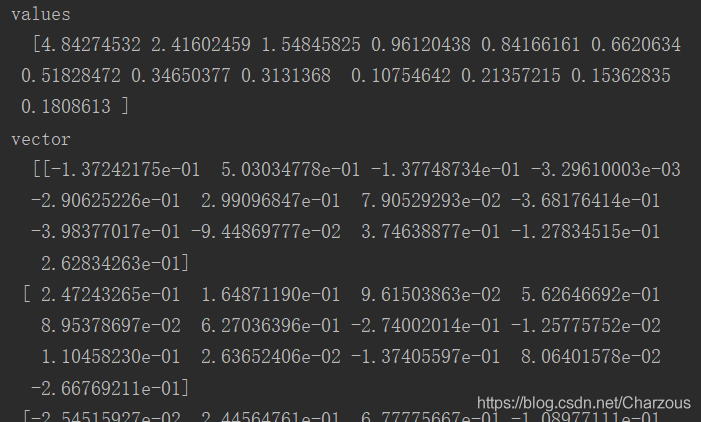
eigen_val, eigen_vec = np.linalg.eig(cov_matrix)
# print("values\n ", eigen_val, "\nvector\n ", eigen_vec)# 可以打印看看
3、主成分方差可視化
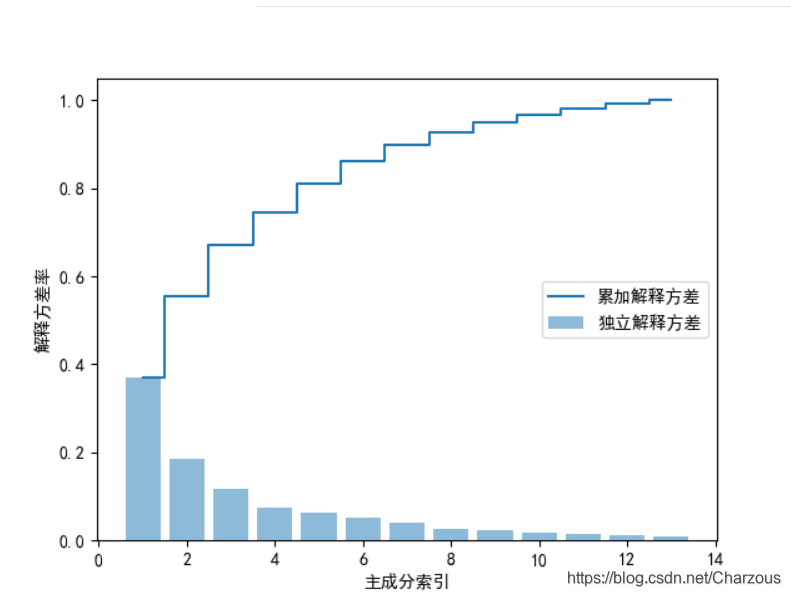
首先,計算主成分方差比率,每個特徵值方差與特徵值方差總和之比:
代碼實現:
# 解釋方差比
tot = sum(eigen_val) # 總特徵值和
var_exp = [(i / tot) for i in sorted(eigen_val, reverse=True)] # 計算解釋方差比,降序
# print(var_exp)
cum_var_exp = np.cumsum(var_exp) # 累加方差比率
plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文
plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='獨立解釋方差') # 柱狀 Individual_explained_variance
plt.step(range(1, 14), cum_var_exp, where='mid', label='累加解釋方差') # Cumulative_explained_variance
plt.ylabel("解釋方差率")
plt.xlabel("主成分索引")
plt.legend(loc='right')
plt.show()
可視化結果看出,第一二主成分佔據大部分方差,接近60%。
4、特徵變換
這一步需要構造之前講到的投影矩陣,從高維d變換到低維空間k。
先將提取的特徵對進行降序排列:
# 特徵變換
eigen_pairs = [(np.abs(eigen_val[i]), eigen_vec[:, i]) for i in range(len(eigen_val))]
eigen_pairs.sort(key=lambda k: k[0], reverse=True) # (特徵值,特徵向量)降序排列
從上步驟可視化,選取第一二主成分作為最大特徵向量進行構造投影矩陣。
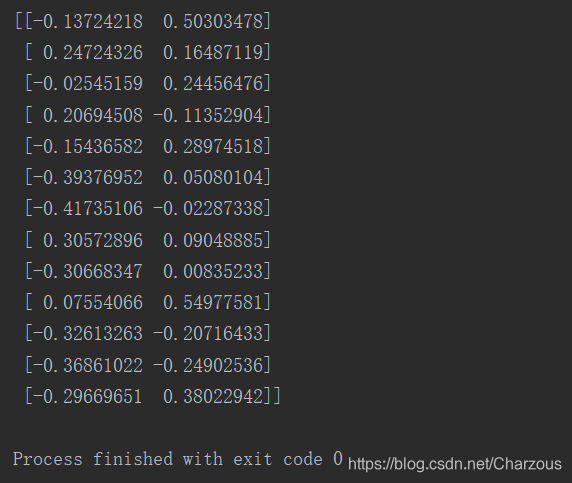
w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) # 降維投影矩陣W
13*2維矩陣如下:
這時,將原數據矩陣與投影矩陣相乘,轉化為只有兩個最大的特徵主成分。
x_train_pca = x_train_std.dot(w)
5、數據分類結果
使用 matplotlib進行畫圖可視化,可見得,數據分佈更多在x軸方向(第一主成分),這與之前方差佔比解釋一致,這時可以很直觀區別3種不同類別。
代碼實現:
color = ['r', 'g', 'b']
marker = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), color, marker):
plt.scatter(x_train_pca[y_train == l, 0],
x_train_pca[y_train == l, 1],
c=c, label=l, marker=m)
plt.title('Result')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='lower left')
plt.show()
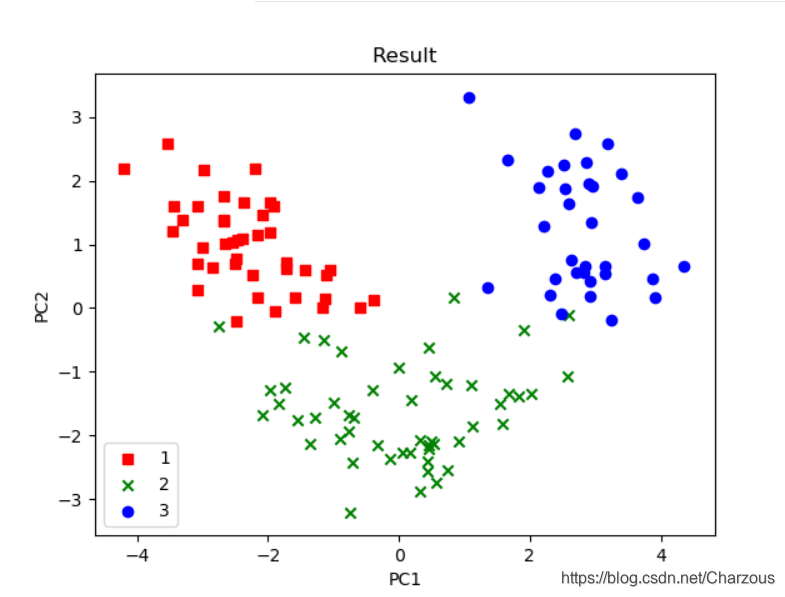
本案例介紹PCA單個步驟和實現過程,一點很重要,PCA是無監督學習技術,它的分類沒有使用到樣本標籤,上面之所以看出3類不同標籤,是後來畫圖時候自行添加的類別區分標籤。
6、完整代碼


import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
def main():
# load data
df_wine = pd.read_csv('D:\\PyCharm_Project\\maching_learning\\wine_data\\wine.data', header=None) # 本地加載
# df_wine=pd.read_csv('//archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)#服務器加載
# split the data,train:test=7:3
x, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y, random_state=0)
# standardize the feature 標準化單位方差
sc = StandardScaler()
x_train_std = sc.fit_transform(x_train)
x_test_std = sc.fit_transform(x_test)
# print(x_train_std)
# 構造協方差矩陣,得到特徵向量和特徵值
cov_matrix = np.cov(x_train_std.T)
eigen_val, eigen_vec = np.linalg.eig(cov_matrix)
# print("values\n ", eigen_val, "\nvector\n ", eigen_vec)
# 解釋方差比
tot = sum(eigen_val) # 總特徵值和
var_exp = [(i / tot) for i in sorted(eigen_val, reverse=True)] # 計算解釋方差比,降序
# print(var_exp)
# cum_var_exp = np.cumsum(var_exp) # 累加方差比率
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文
# plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='獨立解釋方差') # 柱狀 Individual_explained_variance
# plt.step(range(1, 14), cum_var_exp, where='mid', label='累加解釋方差') # Cumulative_explained_variance
# plt.ylabel("解釋方差率")
# plt.xlabel("主成分索引")
# plt.legend(loc='right')
# plt.show()
# 特徵變換
eigen_pairs = [(np.abs(eigen_val[i]), eigen_vec[:, i]) for i in range(len(eigen_val))]
eigen_pairs.sort(key=lambda k: k[0], reverse=True) # (特徵值,特徵向量)降序排列
# print(eigen_pairs)
w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) # 降維投影矩陣W
# print(w)
x_train_pca = x_train_std.dot(w)
# print(x_train_pca)
color = ['r', 'g', 'b']
marker = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), color, marker):
plt.scatter(x_train_pca[y_train == l, 0],
x_train_pca[y_train == l, 1],
c=c, label=l, marker=m)
plt.title('Result')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='lower left')
plt.show()
if __name__ == '__main__':
main()
View Code
總結:
本案例介紹PCA步驟和實現過程,單步進行是我更理解PCA內部實行的過程,主成分分析PCA作為一種無監督數據壓縮技術,學習之後更好掌握數據特徵提取和降維的實現方法。記錄學習過程,不僅能讓自己更好的理解知識,而且能與大家共勉,希望我們都能有所幫助!
我的博客園://www.cnblogs.com/chenzhenhong/p/13472460.html
我的CSDN:原創 PCA數據降維原理及python應用(葡萄酒案例分析)


