聊一聊高並發高可用那些事 – Kafka篇
- 2020 年 6 月 7 日
- 筆記
- kafka, 聊聊高並發高可用那些事
目錄

為什麼需要消息隊列
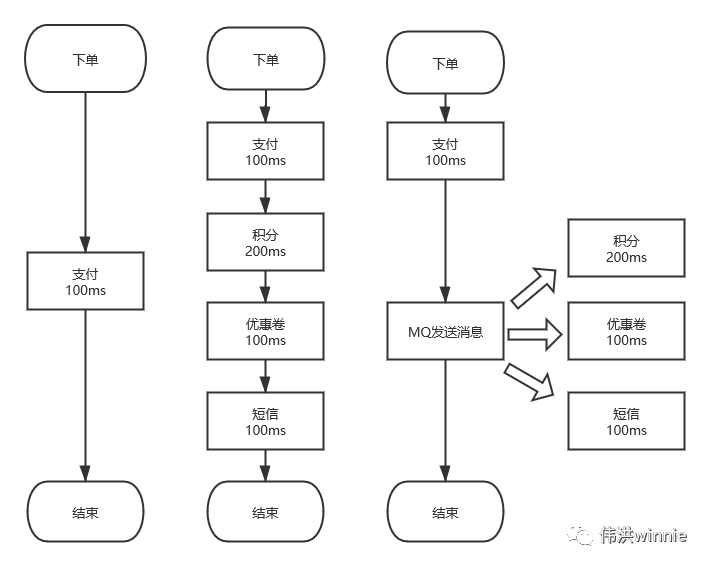
1.異步 :一個下單流程,你需要扣積分,扣優惠卷,發短訊等,有些耗時又不需要立即處理的事,可以丟到隊列里異步處理。
2.削峰 :按平常的流量,服務器剛好可以正常負載。偶爾推出一個優惠活動時,請求量極速上升。由於服務器 Redis,MySQL 承受能力不一樣,如果請求全部接收,服務器負載不了會導致宕機。加機器嘛,需要去調整配置,活動結束後用不到了,即麻煩又浪費。這時可以將請求放到隊列里,按照服務器的能力去消費。
3.解耦 :一個訂單流程,需要扣積分,優惠券,發短訊等調用多個接口,出現問題時不好排查。像發短訊有很多地方需要用到, 如果哪天修改了短訊接口參數,用到的地方都得修改。這時可以將要發送的內容放到隊列里,起一個服務去消費, 統一發送短訊。
高吞吐、高可用 MQ 對比分析
看了幾個招聘網站,提到較多的消息隊列有:RabbitMQ、RocketMQ、Kafka 以及 Redis 的消息隊列和發佈訂閱模式。
Redis 隊列是用 List 數據結構模擬的,指定一端 Push,另一端 Pop,一條消息只能被一個程序所消費。如果要一對多消費的,可以用 Redis 的發佈訂閱模式。Redis 發佈訂閱是實時消費的,服務端不會保存生產的消息,也不會記錄客戶端消費到哪一條。在消費的時候如果客戶端宕機了,消息就會丟失。這時就需要用到高級的消息隊列,如 RocketMQ、Kafka 等。
ZeroMQ 只有點對點模式和 Redis 發佈訂閱模式差不多,如果不是對性能要求極高,我會用其它隊列代替,畢竟關解決開發環境所需的依賴庫就夠折騰的。
RabbitMQ 多語言支持比較完善,特性的支持也比較齊全,但是吞吐量相對小些,而且基於 Erlang 語言開發,不利於二次開發和維護。
RocketMQ 和 Kafka 性能差不多,基於 Topic 的訂閱模式。RocketMQ 支持分佈式事務,但在集群下主從不能自動切換,導致了一些小問題。RocketMQ 使用的集群是 Master-Slave ,在 Master 沒有宕機時,Slave 作為災備,空閑着機器。而 Kafka 採用的是 Leader-Slave 無狀態集群,每台服務器既是 Master 也是 Slave。

Kafka 相關概念
在高可用環境中,Kafka 需要部署多台,避免 Kafka 宕機後,服務無法訪問。Kafka集群中每一台 Kafka 機器就是一個 Broker。Kafka 主題名稱和 Leader 的選舉等操作需要依賴 ZooKeeper。
同樣地,為了避免 ZooKeeper 宕機導致服務無法訪問,ZooKeeper 也需要部署多台。生產者的數據是寫入到 Kafka 的 Leader 節點,Follower 節點的 Kafka 從 Leader 中拉取數據同步。在寫數據時,需要指定一個 Topic,也就是消息的類型。
一個主題下可以有多個分區,數據存儲在分區下。一個主題下也可以有多個副本,每一個副本都是這個主題的完整數據備份。Producer 生產消息,Consumer 消費消息。在沒給 Consumer 指定 Consumer Group 時會創建一個臨時消費組。Producer 生產的消息只能被同一個 Consumer Group 中的一個 Consumer 消費。
- Broker:Kafka 集群中的每一個 Kafka 實例
- Zookeeper:選舉 Leader 節點和存儲相關數據
- Leader:生產者與消費者只跟 Leader Kafka 交互
- Follower:Follower 從 Leader 中同步數據
- Topic:主題,相當於發佈的消息所屬類別
- Producer:消息的生產者
- Consumer:消息的消費者
- Partition:分區
- Replica:副本
- Consumer Group:消費組
分區、副本、消費組
- 分區
主題的數據會按分區數分散存到分區下,把這些分區數據加起來才是一個主題的完整的數據。分區數最好是副本數的整數倍,這樣每個副本分配到的分區數比較均勻。同一個分區寫入是有順序的,如果要保證全局有序,可以只設置一個分區。
如果分區數小於消費者數,前面的消費者會配到一個分區,後面超過分區數的消費者將無分區可消費,除非前面的消費者宕機了。如果分區數大於消費者數,每個消費者至少分配到一個分區的數據,一些分配到兩個分區。這時如果有新的消費者加入,會把有兩個分區的調一個分配到新的消費者。
分區數可以設置成 6、12 等數值。比如 6,當消費者只有一個時,這 6 個分區都歸這個消費者,後面再加入一個消費者時,每個消費者都負責 3 個分區,後面又加入一個消費者時,每個消費者就負責 2 個分區。每個消費者分配到的分區數是一樣的,可以均勻地消費。
- 副本
主題的副本數即數據備份的個數,如果副本數為 1 , 即使 Kafka 機器有多個,當該副本所在的機器宕機後,對應的數據將訪問失敗。
集群模式下創建主題時,如果分區數和副本數都大於 1,主題會將分區 Leader 較均勻的分配在有副本的 Kafka 上。這樣客戶端在消費這個主題時,可以從多台機器上的 Kafka 消息數據,實現分佈式消費。
副本數不是越多越好,從節點需要從主節點拉取數據同步,一般設置成和 Kafka 機器數一樣即可。如果只需要用到高可用的話,可以採用 N+1 策略,副本數設置為 2,專門弄一台 Kafka 來備份數據。然後主題分佈存儲在 “N” 台 Kafka 上,”+1″ 台 Kafka 保存着完整的主題數據,作為備用服務。
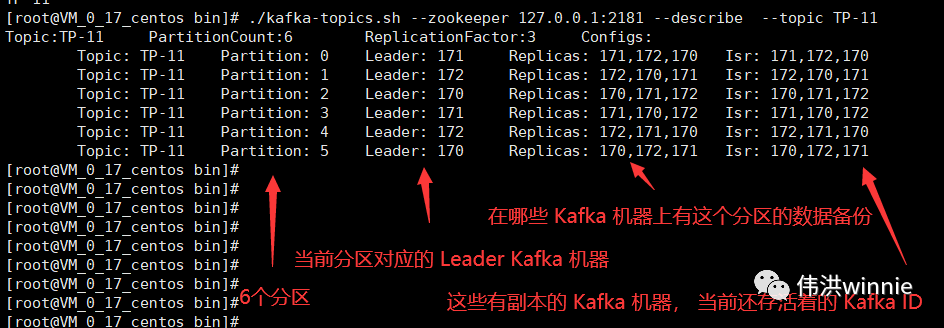
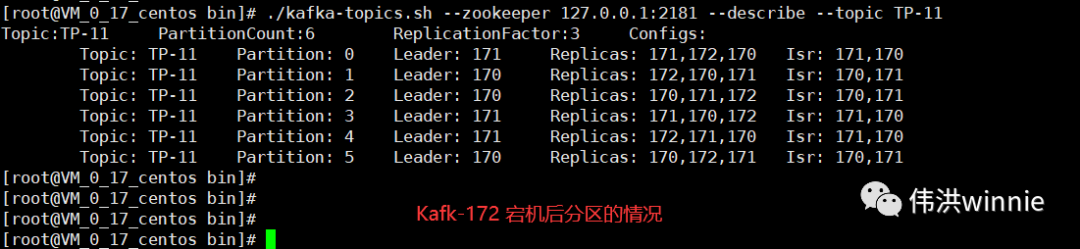
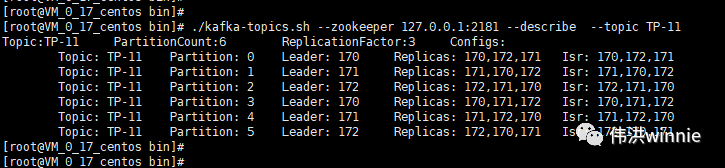
Replicas 表示在哪些 Kafka 機器上有主題的副本,Isr 表示當前有副本的 Kafka 機器上還存活着的 Kafka 機器。主題分區中所涉及的 Leader Kafka 宕機時,會將宕機 Kafka 涉及的分區分配到其它可用的 Kafka 節點上。如下:
- 消費組
每一個消費組記錄者各個主題分區的消費偏移量,在消費的時候,如果沒有指定消費組,會默認創建一個臨時消費組。生產者生產的消息只能被同一消費組下某個消費者消費。如果想要一條消息可以被多個消費者消費,可以加入不同的消費組。
偏移量最大值,消息存儲策略
- 偏移量的最大值
long 類型最大值是(2^63)-1 (為什麼要減一呢?第一位是符號位,正的有262,負的有262,其中+0 和 -0 是相等的 , 只不過有的語言把0算到負裏面,有的語言把0算到正裏面)。 偏移量是一個 long 類型,除去負數,包含0,其最大值為 2^62。
- 消息存儲策略
Kafka 配置項提供兩種策略, 一種是基於時間:log.retention.hours=168,另一種是基於大小:log.retention.bytes=1073741824 。符合條件的數據會被標記為待刪除,Kafka會在恰當的時候才真正刪除。
Zookeeper 上存的 Kafka 相關數據
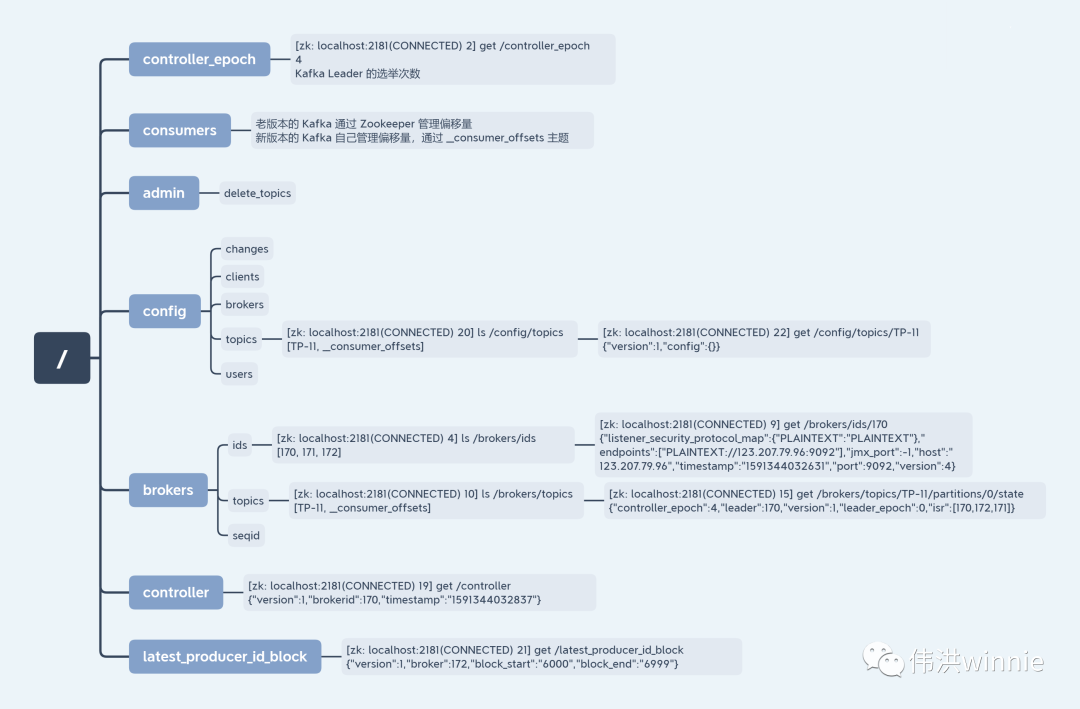
如何確保消息只被消費一次
前面已經講到,同一主題里的分區數據,只能被相同消費組裡其中一個消費者消費。當有多個消費者同時消費同一主題時,將這些消費者都加入相同的消費組,這時生產者的消息只能被其中一個消費者消費。
重複消費和數據丟失問題
- 生產者
生產者發送消息成功後,不等 Kafka 同步完成的確認,繼續發送下一條消息。在發的過程中如果 Leader Kafka 宕機了,但生產者並不知情,發出去的信息 Kafka 就收不到,導致數據丟失。解決方案是將 Request.Required.Acks 設置為 -1,表示生產者等所有副本都確認收到後才發送下一條消息。
Request.Required.Acks=0 表示發送消息即完成發送,不等待確認(可靠性低,延遲小,最容易丟失消息)
Request.Required.Acks=1 表示當 Leader 提交同步完成後才發送下一條消息
- 消費者
消費者有兩種情況,一種是消費的時候自動提交偏移量導致數據丟失:拿到消息的同時偏移量加一,如果業務處理失敗,下一次消費的時候偏移量已經加一了,上一個偏移量的數據丟失了。
另一種是手動提交偏移量導致重複消費:等業務處理成功後再手動提交偏移量,有可能出現業務處理成功,偏移量提交失敗,那下一次消費又是同一條消息。
怎麼解決呢?這是一個 or 的問題,偏移量要麼自動提交要麼手動提交,對應的問題是要麼數據丟失要麼重複消費。如果消息要求實時性高,丟個一兩條沒關係的話可以選擇自動提交偏移量。如果消息一條都不能丟的話可以選擇手動提交偏移量,然後將業務設計成冪等,不管這條消息消費多少次最終和消費一次的結果一樣。
Linux Kafka 操作命令
- 查看 Kafka 中 Topic

- 查看 Kafka 詳情
- 消費 Topic
- 查看所有消費組

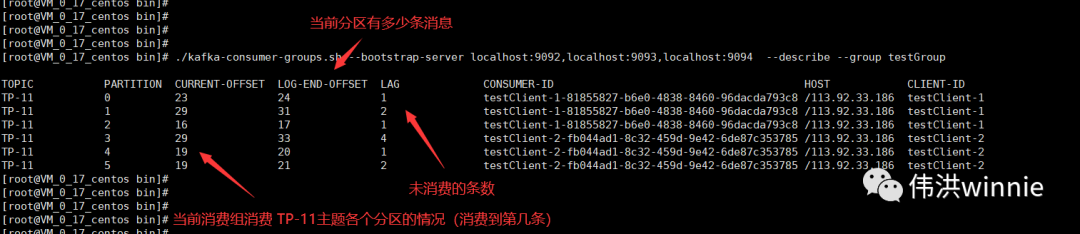
- 查看消費組的消費情況

Windows 可視化工具 Kafka Tool
- 配置 Hosts 文件
123.207.79.96 ZooKeeper-Kafka-01
- 配置 Kafka Tool 連接信息
- 查看 Kafka 主題數據
生產者和消費者使用代碼
- 具體操作參考 github.com/wong-winnie/library
訂閱號:偉洪winnie

