Dropout原理與實現
- 2019 年 10 月 8 日
- 筆記
Dropout是深度學習中的一種防止過擬合手段,在面試中也經常會被問到,因此有必要搞懂其原理。
1 Dropout的運作方式
在神經網絡的訓練過程中,對於一次迭代中的某一層神經網絡,先隨機選擇中的一些神經元並將其臨時隱藏(丟棄),然後再進行本次訓練和優化。在下一次迭代中,繼續隨機隱藏一些神經元,如此直至訓練結束。由於是隨機丟棄,故而每一個mini-batch都在訓練不同的網絡。
在訓練時,每個神經單元以概率$p$被保留(Dropout丟棄率為$1-p$);在預測階段(測試階段),每個神經單元都是存在的,權重參數$w$要乘以$p$,輸出是:$pw$。示意圖如下:
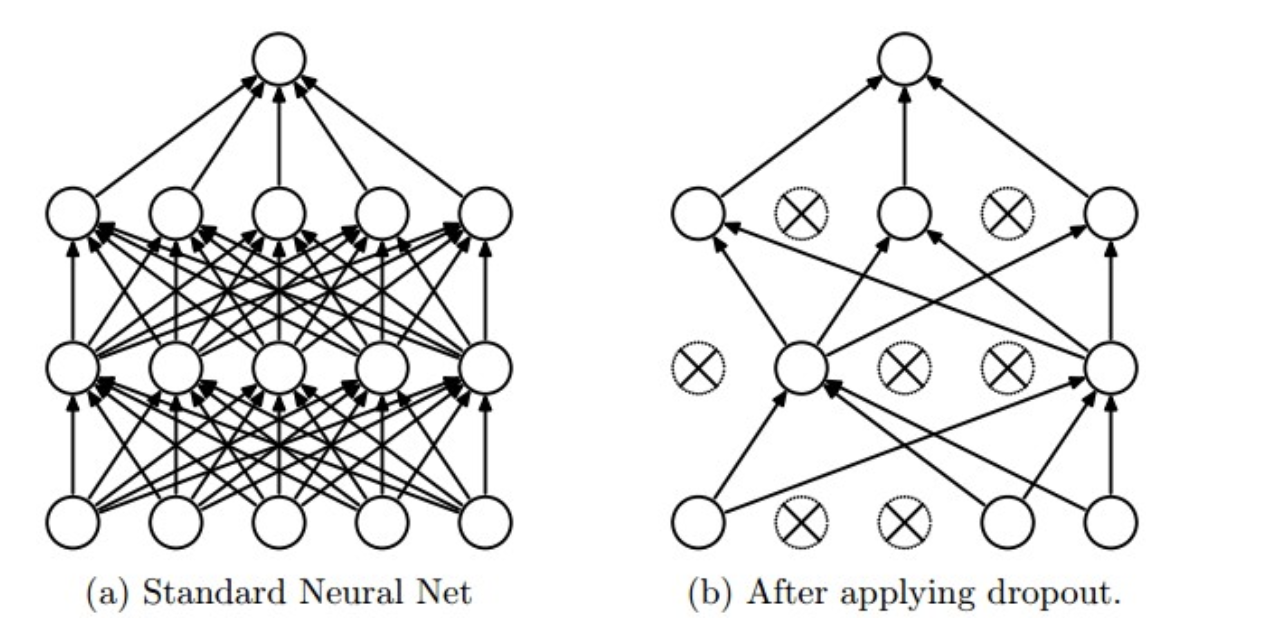
預測階段需要乘上$p$的原因:
前一層隱藏層的一個神經元在$dropout$之前的輸出是$x$,訓練時$dropout$之後的期望值是$E=px+(1−p) dot 0$; 在預測階段該層神經元總是激活,為了保持同樣的輸出期望值並使下一層也得到同樣的結果,需要調整$x->px$. 其中$p$是Bernoulli分佈(0-1分佈)中值為1的概率。
2 Dropout 實現
如前文所述,在訓練時隨機隱藏部分神經元,在預測時必須要乘上p。代碼如下:
1 import numpy as np 2 3 p = 0.5 # 神經元激活概率 4 5 def train_step(X): 6 """ X contains the data """ 7 8 # 三層神經網絡前向傳播為例 9 H1 = np.maximum(0, np.dot(W1, X) + b1) 10 U1 = np.random.rand(*H1.shape) < p # first dropout mask 11 H1 *= U1 # drop! 12 H2 = np.maximum(0, np.dot(W2, H1) + b2) 13 U2 = np.random.rand(*H2.shape) < p # second dropout mask 14 H2 *= U2 # drop! 15 out = np.dot(W3, H2) + b3 16 17 18 def predict(X): 19 # ensembled forward pass 20 H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations 21 H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations 22 out = np.dot(W3, H2) + b3
3 反向Dropout
一個略有不同的方法是使用反向Dropout(Inverted Dropout)。該方法包括在訓練階段縮放激活函數,從而使得其測試階段保持不變。比例因子是保持概率的倒數即$1/p$。所以我們換一個思路,在訓練時候對數據進行1/p縮放,在訓練時,就不需要做什麼了。
反向Dropout只定義一次模型並且只改變了一個參數(保持/丟棄概率)以使用同一模型進行訓練和測試。相反,直接Dropout,必須要在測試階段修改網絡。因為如果你不乘以比例因子p,神經網絡的輸出將產生更高的相對於連續神經元所期望的值(因此神經元可能飽和):因此反向Dropout是更加常見的實現方式。代碼如下:
1 p = 0.5 # probability of keeping a unit active. higher = less dropout 2 3 def train_step(X): 4 # forward pass for example 3-layer neural network 5 H1 = np.maximum(0, np.dot(W1, X) + b1) 6 U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p! 7 H1 *= U1 # drop! 8 H2 = np.maximum(0, np.dot(W2, H1) + b2) 9 U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p! 10 H2 *= U2 # drop! 11 out = np.dot(W3, H2) + b3 12 13 # backward pass: compute gradients... (not shown) 14 # perform parameter update... (not shown) 15 16 def predict(X): 17 # ensembled forward pass 18 H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary 19 H2 = np.maximum(0, np.dot(W2, H1) + b2) 20 out = np.dot(W3, H2) + b3
3. Dropout為什麼可以防止過擬合?
(1)取平均的作用
先回到標準的模型即沒有dropout,我們用相同的訓練數據去訓練5個不同的神經網絡,一般會得到5個不同的結果,此時我們可以採用 “5個結果取均值”或者“多數取勝的投票策略”去決定最終結果。例如3個網絡判斷結果為數字9,那麼很有可能真正的結果就是數字9,其它兩個網絡給出了錯誤結果。這種“綜合起來取平均”的策略通常可以有效防止過擬合問題。因為不同的網絡可能產生不同的過擬合,取平均則有可能讓一些“相反的”擬合互相抵消。dropout掉不同的隱藏神經元就類似在訓練不同的網絡,隨機刪掉一半隱藏神經元導致網絡結構已經不同,整個dropout過程就相當於對很多個不同的神經網絡取平均。而不同的網絡產生不同的過擬合,一些互為“反向”的擬合相互抵消就可以達到整體上減少過擬合。
(2)減少神經元之間複雜的共適應關係
用作者原話是“在標準神經網絡中,每個參數接收的導數表明其應該如何變化才能使最終損失函數降低,並給定所有其它神經網絡單元的狀態。因此神經單元可能以一種可以修正其它神經網絡單元的錯誤的方式進行改變。而這就可能導致複雜的共適應(co-adaptations)。由於這些共適應現象沒有推廣到未見的數據,將導致過擬合。我們假設對每個隱藏層的神經網絡單元,Dropout通過使其它隱藏層神經網絡單元不可靠從而阻止了共適應的發生。因此,一個隱藏層神經元不能依賴其它特定神經元去糾正其錯誤。”
因為dropout程序導致兩個神經元不一定每次都在一個dropout網絡中出現。這樣權值的更新不再依賴於有固定關係的隱含節點的共同作用,阻止了某些特徵僅僅在其它特定特徵下才有效果的情況 。迫使網絡去學習更加魯棒的特徵 ,這些特徵在其它的神經元的隨機子集中也存在。換句話說假如我們的神經網絡是在做出某種預測,它不應該對一些特定的線索片段太過敏感,即使丟失特定的線索,它也應該可以從眾多其它線索中學習一些共同的特徵。從這個角度看dropout就有點像L1,L2正則,減少權重使得網絡對丟失特定神經元連接的魯棒性提高。
(3)Dropout類似於性別在生物進化中的角色
物種為了生存往往會傾向於適應這種環境,環境突變則會導致物種難以做出及時反應,性別的出現可以繁衍出適應新環境的變種,有效的阻止過擬合,即避免環境改變時物種可能面臨的滅絕。
4 參考
1 http://cs231n.github.io/neural-networks-2/#reg
2 http://jmlr.org/papers/volume15/srivastava14a.old/srivastava14a.pdf
