探究Spring原理
探究Spring原理
探究IoC原理
首先我们大致了解一下ApplicationContext的加载流程:

我们可以看到,整个过程极为复杂,一句话肯定是无法解释的,所以我们就从ApplicationContext说起吧。
由于Spring的源码极为复杂,因此我们不可能再像了解其他框架那样直接自底向上逐行干源码了(可以自己点开看看,代码量非常之多),我们可以先从一些最基本的接口定义开始讲起,自顶向下逐步瓦解,那么我们来看看ApplicationContext最顶层接口是什么,一直往上,我们会发现有一个AbstractApplicationContext类,我们直接右键生成一个UML类图。

我们发现最顶层实际上是一个BeanFactory接口,那么我们就从这个接口开始研究起。
我们可以看到此接口中定义了很多的行为:
public interface BeanFactory {
String FACTORY_BEAN_PREFIX = "&";
Object getBean(String var1) throws BeansException;
<T> T getBean(String var1, Class<T> var2) throws BeansException;
Object getBean(String var1, Object... var2) throws BeansException;
<T> T getBean(Class<T> var1) throws BeansException;
<T> T getBean(Class<T> var1, Object... var2) throws BeansException;
<T> ObjectProvider<T> getBeanProvider(Class<T> var1);
<T> ObjectProvider<T> getBeanProvider(ResolvableType var1);
boolean containsBean(String var1);
boolean isSingleton(String var1) throws NoSuchBeanDefinitionException;
boolean isPrototype(String var1) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String var1, ResolvableType var2) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String var1, Class<?> var2) throws NoSuchBeanDefinitionException;
@Nullable
Class<?> getType(String var1) throws NoSuchBeanDefinitionException;
@Nullable
Class<?> getType(String var1, boolean var2) throws NoSuchBeanDefinitionException;
String[] getAliases(String var1);
}
我们发现,其中最眼熟的就是getBean()方法了,此方法被重载了很多次,可以接受多种参数。
因此,我们可以断定,一个IoC容器最基本的行为在此接口中已经被定义好了,也就是说,所有的BeanFactory实现类都应该具备容器管理Bean的基本能力,就像它的名字一样,它就是一个Bean工厂,工厂就是用来生产Bean实例对象的。
我们可以直接找到此接口的一个抽象实现AbstractBeanFactory类,它实现了getBean()方法:
public Object getBean(String name) throws BeansException {
return this.doGetBean(name, (Class)null, (Object[])null, false);
}
那么我们doGetBean()接着来看方法里面干了什么:
protected <T> T doGetBean(String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly) throws BeansException {
String beanName = this.transformedBeanName(name);
Object sharedInstance = this.getSingleton(beanName);
Object beanInstance;
if (sharedInstance != null && args == null) {
...
因为所有的Bean默认都是单例模式,对象只会存在一个,因此它会先调用父类的getSingleton()方法来直接获取单例对象,如果有的话,就可以直接拿到Bean的实例。如果没有会进入else代码块,我们接着来看,首先会进行一个判断:
if (this.isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
这是为了解决循环依赖进行的处理,比如A和B都是以原型模式进行创建,而A中需要注入B,B中需要注入A,这时就会出现A还未创建完成,就需要B,而B这时也没创建完成,因为B需要A,而A等着B,这样就只能无限循环下去了,所以就出现了循环依赖的问题(同理,一个对象,多个对象也会出现这种情况)但是在单例模式下,由于每个Bean只会创建一个实例,Spring完全有机会处理好循环依赖的问题,只需要一个正确的赋值操作实现循环即可。那么单例模式下是如何解决循环依赖问题的呢?
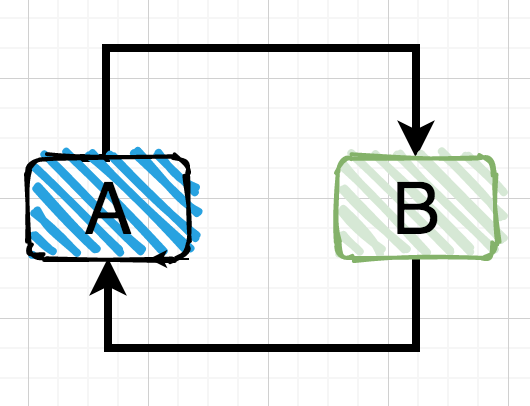
我们回到getSingleton()方法中,单例模式是可以自动解决循环依赖问题的:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
//先从第一层列表中拿Bean实例,拿到直接返回
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
//第一层拿不到,并且已经认定为处于循环状态,看看第二层有没有
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized(this.singletonObjects) {
//加锁再执行一次上述流程
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
//仍然没有获取到实例,只能从singletonFactory中获取了
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//丢进earlySingletonObjects中,下次就可以直接在第二层拿到了
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
看起来很复杂,实际上它使用了三层列表的方式来处理循环依赖的问题。包括:
- singletonObjects
- earlySingletonObjects
- singletonFactories
当第一层拿不到时,会接着判断这个Bean是否处于创建状态isSingletonCurrentlyInCreation(),它会从一个Set集合中查询,这个集合中存储了已经创建但还未注入属性的实例对象,也就是说处于正在创建状态,如果说发现此Bean处于正在创建状态(一定是因为某个Bean需要注入这个Bean的实例),就可以断定它应该是出现了循环依赖的情况。
earlySingletonObjects相当于是专门处理循环依赖的表,一般包含singletonObjects中的全部实例,如果这个里面还是没有,接着往下走,这时会从singletonFactories中获取(所有的Bean初始化完成之后都会被丢进singletonFactories,也就是只创建了,但是还没进行依赖注入的时候)在获取到后,向earlySingletonObjects中丢入此Bean的实例,并将实例从singletonFactories中移除。
我们最后再来梳理一下流程,还是用我们刚才的例子,A依赖于B,B依赖于A:
- 假如A先载入,那么A首先进入了singletonFactories中,注意这时还没进行依赖注入,A中的B还是null
- singletonFactories:A
- earlySingletonObjects:
- singletonObjects:
- 接着肯定是注入A的依赖B了,但是B还没初始化,因此现在先把B给载入了,B构造完成后也进了singletonFactories
- singletonFactories:A,B
- earlySingletonObjects:
- singletonObjects:
- 开始为B注入依赖,发现B依赖于A,这时又得去获取A的实例,根据上面的分析,这时候A还在singletonFactories中,那么它会被丢进earlySingletonObjects,然后从singletonFactories中移除,然后返回A的实例(注意此时A中的B依赖还是null)
- singletonFactories:B
- earlySingletonObjects:A
- singletonObjects:
- 这时B已经完成依赖注入了,因此可以直接丢进singletonObjects中
- singletonFactories:
- earlySingletonObjects:A
- singletonObjects:B
- 然后再将B注入到A中,完成A的依赖注入,A也被丢进singletonObjects中,至此循环依赖完成,A和B完成实例创建
- singletonFactories:
- earlySingletonObjects:
- singletonObjects:A,B
经过整体过程梳理,关于Spring如何解决单例模式的循环依赖理解起来就非常简单了。
现在让我们回到之前的地方,原型模式下如果出现循环依赖会直接抛出异常,如果不存在会接着向下:
//BeanFactory存在父子关系
BeanFactory parentBeanFactory = this.getParentBeanFactory();
//如果存在父BeanFactory,同时当前BeanFactory没有这个Bean的定义
if (parentBeanFactory != null && !this.containsBeanDefinition(beanName)) {
//这里是因为Bean可能有别名,找最原始的那个名称
String nameToLookup = this.originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
//向父BeanFactory递归查找
return ((AbstractBeanFactory)parentBeanFactory).doGetBean(nameToLookup, requiredType, args, typeCheckOnly);
}
if (args != null) {
//根据参数查找
return parentBeanFactory.getBean(nameToLookup, args);
}
if (requiredType != null) {
//根据类型查找
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
//各种找
return parentBeanFactory.getBean(nameToLookup);
}
也就是说,BeanFactory会先看当前是否存在Bean的定义,如果没有会直接用父BeanFactory各种找。这里出现了一个新的接口BeanDefinition,既然工厂需要生产商品,那么肯定需要拿到商品的原材料以及制作配方,我们的Bean也是这样,Bean工厂需要拿到Bean的信息才可以去生成这个Bean的实例对象,而BeanDefinition就是用于存放Bean的信息的,所有的Bean信息正是从XML配置文件读取或是注解扫描后得到的。
我们接着来看,如果此BeanFactory不存在父BeanFactory或是包含了Bean的定义,那么会接着往下走,这时只能自己创建Bean了,首先会拿到一个RootBeanDefinition对象:
try {
if (requiredType != null) {
beanCreation.tag("beanType", requiredType::toString);
}
RootBeanDefinition mbd = this.getMergedLocalBeanDefinition(beanName);
下面的内容就非常复杂了,但是我们可以知道,它一定是根据对应的类型(单例、原型)进行了对应的处理,最后自行创建一个新的对象返回。一个Bean的加载流程为:
首先拿到BeanDefinition定义,选择对应的构造方法,通过反射进行实例化,然后进行属性填充(依赖注入),完成之后再调用初始化方法(init-method),最后如果存在AOP,则会生成一个代理对象,最后返回的才是我们真正得到的Bean对象。
最后让我们回到ApplicationContext中,实际上,它就是一个强化版的BeanFactory,在最基本的Bean管理基础上,还添加了:
- 国际化(MessageSource)
- 访问资源,如URL和文件(ResourceLoader)
- 载入多个(有继承关系)上下文
- 消息发送、响应机制(ApplicationEventPublisher)
- AOP机制
我们发现,无论是还是的构造方法中都会调用refresh()方法来刷新应用程序上下文:
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();
this.register(componentClasses);
this.refresh();
}
此方法在讲解完AOP原理之后,再进行讲解。综上,有关IoC容器的大部分原理就讲解完毕了。
探究AOP原理
前面我们提到了PostProcessor,它其实是Spring提供的一种后置处理机制,它可以让我们能够插手Bean、BeanFactory、BeanDefinition的创建过程,相当于进行一个最终的处理,而最后得到的结果(比如Bean实例、Bean定义等)就是经过后置处理器返回的结果,它是整个加载过程的最后一步。
而AOP机制正是通过它来实现的,我们首先来认识一下第一个接口BeanPostProcessor,它相当于Bean初始化的一个后置动作,我们可以直接实现此接口:
//注意它后置处理器也要进行注册
@Component
public class TestBeanProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println(beanName); //打印bean的名称
return bean;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return BeanPostProcessor.super.postProcessBeforeInitialization(bean, beanName);
}
}
我们发现,此接口中包括两个方法,一个是postProcessAfterInitialization用于在Bean初始化之后进行处理,还有一个postProcessBeforeInitialization用于在Bean初始化之前进行处理,注意这里的初始化不是创建对象,而是调用类的初始化方法,比如:
@Component
public class TestBeanProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("我是之后:"+beanName);
return bean; //这里返回的Bean相当于最终的结果了,我们依然能够插手修改,这里返回之后是什么就是什么了
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("我是之前:"+beanName);
return bean; //这里返回的Bean会交给下一个阶段,也就是初始化方法
}
}
@Component
public class TestServiceImpl implements TestService{
public TestServiceImpl(){
System.out.println("我是构造方法");
}
@PostConstruct
public void init(){
System.out.println("我是初始化方法");
}
TestMapper mapper;
@Autowired
public void setMapper(TestMapper mapper) {
System.out.println("我是依赖注入");
this.mapper = mapper;
}
...
而TestServiceImpl的加载顺序为:
我是构造方法
我是依赖注入
我是之前:testServiceImpl
我是初始化方法
我是之后:testServiceImpl
现在我们再来总结一下一个Bean的加载流程:
[Bean定义]首先扫描Bean,加载Bean定义 -> [依赖注入]根据Bean定义通过反射创建Bean实例 -> [依赖注入]进行依赖注入(顺便解决循环依赖问题)-> [初始化Bean]BeanPostProcessor的初始化之前方法 -> [初始化Bean]Bean初始化方法 -> [初始化Bean]BeanPostProcessor的初始化之前后方法 -> [完成]最终得到的Bean加载完成的实例
利用这种机制,理解Aop的实现过程就非常简单了,AOP实际上也是通过这种机制实现的,它的实现类是AnnotationAwareAspectJAutoProxyCreator,而它就是在最后对Bean进行了代理,因此最后我们得到的结果实际上就是一个动态代理的对象(有关详细实现过程,这里就不进行列举了,感兴趣的可以继续深入)
那么肯定有人有疑问了,这个类没有被注册啊,那按理说它不应该参与到Bean的初始化流程中的,为什么它直接就被加载了呢?
还记得@EnableAspectJAutoProxy吗?我们来看看它是如何定义就知道了:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import({AspectJAutoProxyRegistrar.class})
public @interface EnableAspectJAutoProxy {
boolean proxyTargetClass() default false;
boolean exposeProxy() default false;
}
我们发现它使用了@Import来注册AspectJAutoProxyRegistrar,那么这个类又是什么呢,我们接着来看:
class AspectJAutoProxyRegistrar implements ImportBeanDefinitionRegistrar {
AspectJAutoProxyRegistrar() {
}
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
//注册AnnotationAwareAspectJAutoProxyCreator到容器中
AopConfigUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(registry);
AnnotationAttributes enableAspectJAutoProxy = AnnotationConfigUtils.attributesFor(importingClassMetadata, EnableAspectJAutoProxy.class);
if (enableAspectJAutoProxy != null) {
if (enableAspectJAutoProxy.getBoolean("proxyTargetClass")) {
AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry);
}
if (enableAspectJAutoProxy.getBoolean("exposeProxy")) {
AopConfigUtils.forceAutoProxyCreatorToExposeProxy(registry);
}
}
}
}
它实现了接口,这个接口也是Spring提供的一种Bean加载机制,它支持直接向容器中添加Bean定义,容器也会加载这个Bean:
- ImportBeanDefinitionRegistrar类只能通过其他类@Import的方式来加载,通常是启动类或配置类。
- 使用@Import,如果括号中的类是ImportBeanDefinitionRegistrar的实现类,则会调用接口中方法(一般用于注册Bean)
- 实现该接口的类拥有注册bean的能力。
我们可以看到此接口提供了一个BeanDefinitionRegistry正是用于注册Bean的定义的。
因此,当我们打上了@EnableAspectJAutoProxy注解之后,首先会通过@Import加载AspectJAutoProxyRegistrar,然后调用其registerBeanDefinitions方法,然后使用工具类注册AnnotationAwareAspectJAutoProxyCreator到容器中,这样在每个Bean创建之后,如果需要使用AOP,那么就会通过AOP的后置处理器进行处理,最后返回一个代理对象。
我们也可以尝试编写一个自己的ImportBeanDefinitionRegistrar实现,首先编写一个测试Bean:
public class TestBean {
@PostConstruct
void init(){
System.out.println("我被初始化了!");
}
}
public class TestBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
BeanDefinition definition = BeanDefinitionBuilder.rootBeanDefinition(Student.class).getBeanDefinition();
registry.registerBeanDefinition("lbwnb", definition);
}
}
观察控制台输出,成功加载Bean实例。
与BeanPostProcessor差不多的还有BeanFactoryPostProcessor,它和前者一样,也是用于我们自己处理后置动作的,不过这里是用于处理BeanFactory加载的后置动作,BeanDefinitionRegistryPostProcessor直接继承自BeanFactoryPostProcessor,并且还添加了新的动作postProcessBeanDefinitionRegistry,你可以在这里动态添加Bean定义或是修改已经存在的Bean定义,这里我们就直接演示BeanDefinitionRegistryPostProcessor的实现:
@Component
public class TestDefinitionProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("我是Bean定义后置处理!");
BeanDefinition definition = BeanDefinitionBuilder.rootBeanDefinition(TestBean.class).getBeanDefinition();
registry.registerBeanDefinition("lbwnb", definition);
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
System.out.println("我是Bean工厂后置处理!");
}
}
在这里注册Bean定义其实和之前那种方法效果一样。
最后,我们再完善一下Bean加载流程(加粗部分是新增的):
[Bean定义]首先扫描Bean,加载Bean定义 -> [Bean定义]Bean定义和Bean工厂后置处理 -> [依赖注入]根据Bean定义通过反射创建Bean实例 -> [依赖注入]进行依赖注入(顺便解决循环依赖问题)-> [初始化Bean]BeanPostProcessor的初始化之前方法 -> [初始化Bean]Bean初始化方法 -> [初始化Bean]BeanPostProcessor的初始化之前后方法 -> [完成]最终得到的Bean加载完成的实例
最后我们再来研究一下ApplicationContext中的refresh()方法:
public void refresh() throws BeansException, IllegalStateException {
synchronized(this.startupShutdownMonitor) {
StartupStep contextRefresh = this.applicationStartup.start("spring.context.refresh");
this.prepareRefresh();
ConfigurableListableBeanFactory beanFactory = this.obtainFreshBeanFactory();
//初始化Bean工厂
this.prepareBeanFactory(beanFactory);
try {
this.postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
//调用所有的Bean工厂、Bean注册后置处理器
this.invokeBeanFactoryPostProcessors(beanFactory);
//注册Bean后置处理器(包括Spring内部的)
this.registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
//国际化支持
this.initMessageSource();
//监听和事件广播
this.initApplicationEventMulticaster();
this.onRefresh();
this.registerListeners();
//实例化所有的Bean
this.finishBeanFactoryInitialization(beanFactory);
this.finishRefresh();
} catch (BeansException var10) {
if (this.logger.isWarnEnabled()) {
this.logger.warn("Exception encountered during context initialization - cancelling refresh attempt: " + var10);
}
this.destroyBeans();
this.cancelRefresh(var10);
throw var10;
} finally {
this.resetCommonCaches();
contextRefresh.end();
}
}
}
我们可以给这些部分分别打上断点来观察一下此方法的整体加载流程。
Mybatis整合原理
通过之前的了解,我们再来看Mybatis的@MapperScan是如何实现的,现在理解起来就非常简单了。
我们可以直接打开查看:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
@Documented
@Import({MapperScannerRegistrar.class})
@Repeatable(MapperScans.class)
public @interface MapperScan {
String[] value() default {};
String[] basePackages() default {};
...
我们发现,和Aop一样,它也是通过Registrar机制,通过@Import来进行Bean的注册,我们来看看MapperScannerRegistrar是个什么东西,关键代码如下:
void registerBeanDefinitions(AnnotationMetadata annoMeta, AnnotationAttributes annoAttrs, BeanDefinitionRegistry registry, String beanName) {
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(MapperScannerConfigurer.class);
builder.addPropertyValue("processPropertyPlaceHolders", true);
Class<? extends Annotation> annotationClass = annoAttrs.getClass("annotationClass");
if (!Annotation.class.equals(annotationClass)) {
builder.addPropertyValue("annotationClass", annotationClass);
}
Class<?> markerInterface = annoAttrs.getClass("markerInterface");
if (!Class.class.equals(markerInterface)) {
builder.addPropertyValue("markerInterface", markerInterface);
}
Class<? extends BeanNameGenerator> generatorClass = annoAttrs.getClass("nameGenerator");
if (!BeanNameGenerator.class.equals(generatorClass)) {
builder.addPropertyValue("nameGenerator", BeanUtils.instantiateClass(generatorClass));
}
Class<? extends MapperFactoryBean> mapperFactoryBeanClass = annoAttrs.getClass("factoryBean");
if (!MapperFactoryBean.class.equals(mapperFactoryBeanClass)) {
builder.addPropertyValue("mapperFactoryBeanClass", mapperFactoryBeanClass);
}
String sqlSessionTemplateRef = annoAttrs.getString("sqlSessionTemplateRef");
if (StringUtils.hasText(sqlSessionTemplateRef)) {
builder.addPropertyValue("sqlSessionTemplateBeanName", annoAttrs.getString("sqlSessionTemplateRef"));
}
String sqlSessionFactoryRef = annoAttrs.getString("sqlSessionFactoryRef");
if (StringUtils.hasText(sqlSessionFactoryRef)) {
builder.addPropertyValue("sqlSessionFactoryBeanName", annoAttrs.getString("sqlSessionFactoryRef"));
}
List<String> basePackages = new ArrayList();
basePackages.addAll((Collection)Arrays.stream(annoAttrs.getStringArray("value")).filter(StringUtils::hasText).collect(Collectors.toList()));
basePackages.addAll((Collection)Arrays.stream(annoAttrs.getStringArray("basePackages")).filter(StringUtils::hasText).collect(Collectors.toList()));
basePackages.addAll((Collection)Arrays.stream(annoAttrs.getClassArray("basePackageClasses")).map(ClassUtils::getPackageName).collect(Collectors.toList()));
if (basePackages.isEmpty()) {
basePackages.add(getDefaultBasePackage(annoMeta));
}
String lazyInitialization = annoAttrs.getString("lazyInitialization");
if (StringUtils.hasText(lazyInitialization)) {
builder.addPropertyValue("lazyInitialization", lazyInitialization);
}
String defaultScope = annoAttrs.getString("defaultScope");
if (!"".equals(defaultScope)) {
builder.addPropertyValue("defaultScope", defaultScope);
}
builder.addPropertyValue("basePackage", StringUtils.collectionToCommaDelimitedString(basePackages));
registry.registerBeanDefinition(beanName, builder.getBeanDefinition());
}
虽然很长很多,但是这些代码都是在添加一些Bean定义的属性,而最关键的则是最上方的MapperScannerConfigurer,Mybatis将其Bean信息注册到了容器中,那么这个类又是干嘛的呢?
public class MapperScannerConfigurer implements BeanDefinitionRegistryPostProcessor, InitializingBean, ApplicationContextAware, BeanNameAware {
private String basePackage;
它实现了BeanDefinitionRegistryPostProcessor,也就是说它为Bean信息加载提供了后置处理,我们接着来看看它在Bean信息后置处理中做了什么:
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
if (this.processPropertyPlaceHolders) {
this.processPropertyPlaceHolders();
}
//初始化类路径Mapper扫描器,它相当于是一个工具类,可以快速扫描出整个包下的类定义信息
//ClassPathMapperScanner是Mybatis自己实现的一个扫描器,修改了一些扫描规则
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
scanner.setAddToConfig(this.addToConfig);
scanner.setAnnotationClass(this.annotationClass);
scanner.setMarkerInterface(this.markerInterface);
scanner.setSqlSessionFactory(this.sqlSessionFactory);
scanner.setSqlSessionTemplate(this.sqlSessionTemplate);
scanner.setSqlSessionFactoryBeanName(this.sqlSessionFactoryBeanName);
scanner.setSqlSessionTemplateBeanName(this.sqlSessionTemplateBeanName);
scanner.setResourceLoader(this.applicationContext);
scanner.setBeanNameGenerator(this.nameGenerator);
scanner.setMapperFactoryBeanClass(this.mapperFactoryBeanClass);
if (StringUtils.hasText(this.lazyInitialization)) {
scanner.setLazyInitialization(Boolean.valueOf(this.lazyInitialization));
}
if (StringUtils.hasText(this.defaultScope)) {
scanner.setDefaultScope(this.defaultScope);
}
//添加过滤器,这里会配置为所有的接口都能被扫描(因此即使你不添加@Mapper注解都能够被扫描并加载)
scanner.registerFilters();
//开始扫描
scanner.scan(StringUtils.tokenizeToStringArray(this.basePackage, ",; \t\n"));
}
开始扫描后,会调用doScan()方法,我们接着来看(这是ClassPathMapperScanner中的扫描方法):
public Set<BeanDefinitionHolder> doScan(String... basePackages) {
Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages);
//首先从包中扫描所有的Bean定义
if (beanDefinitions.isEmpty()) {
LOGGER.warn(() -> {
return "No MyBatis mapper was found in '" + Arrays.toString(basePackages) + "' package. Please check your configuration.";
});
} else {
//处理所有的Bean定义,实际上就是生成对应Mapper的代理对象,并注册到容器中
this.processBeanDefinitions(beanDefinitions);
}
//最后返回所有的Bean定义集合
return beanDefinitions;
}
通过断点我们发现,最后处理得到的Bean定义发现此Bean是一个MapperFactoryBean,它不同于普通的Bean,FactoryBean相当于为普通的Bean添加了一层外壳,它并不是依靠Spring直接通过反射创建,而是使用接口中的方法:
public interface FactoryBean<T> {
String OBJECT_TYPE_ATTRIBUTE = "factoryBeanObjectType";
@Nullable
T getObject() throws Exception;
@Nullable
Class<?> getObjectType();
default boolean isSingleton() {
return true;
}
}
通过getObject()方法,就可以获取到Bean的实例了。
注意这里一定要区分FactoryBean和BeanFactory的概念:
- BeanFactory是个Factory,也就是 IOC 容器或对象工厂,所有的 Bean 都是由 BeanFactory( 也就是 IOC 容器 ) 来进行管理。
- FactoryBean是一个能生产或者修饰生成对象的工厂Bean(本质上也是一个Bean),可以在BeanFactory(IOC容器)中被管理,所以它并不是一个简单的Bean。当使用容器中factory bean的时候,该容器不会返回factory bean本身,而是返回其生成的对象。要想获取FactoryBean的实现类本身,得在getBean(String BeanName)中的BeanName之前加上&,写成getBean(String &BeanName)。
我们也可以自己编写一个实现:
@Component("test")
public class TestFb implements FactoryBean<Student> {
@Override
public Student getObject() throws Exception {
System.out.println("获取了学生");
return new Student();
}
@Override
public Class<?> getObjectType() {
return Student.class;
}
}
public static void main(String[] args) {
log.info("项目正在启动...");
ApplicationContext context = new AnnotationConfigApplicationContext(TestConfiguration.class);
System.out.println(context.getBean("&test")); //得到FactoryBean本身(得加个&搞得像C语言指针一样)
System.out.println(context.getBean("test")); //得到FactoryBean调用getObject()之后的结果
}
因此,实际上我们的Mapper最终就以FactoryBean的形式,被注册到容器中进行加载了:
public T getObject() throws Exception {
return this.getSqlSession().getMapper(this.mapperInterface);
}
这样,整个Mybatis的@MapperScan的原理就全部解释完毕了。
在了解完了Spring的底层原理之后,我们其实已经完全可以根据这些实现原理来手写一个Spring框架了。


