flink:StreamGraph转换为JobGraph
1 转换基本流程
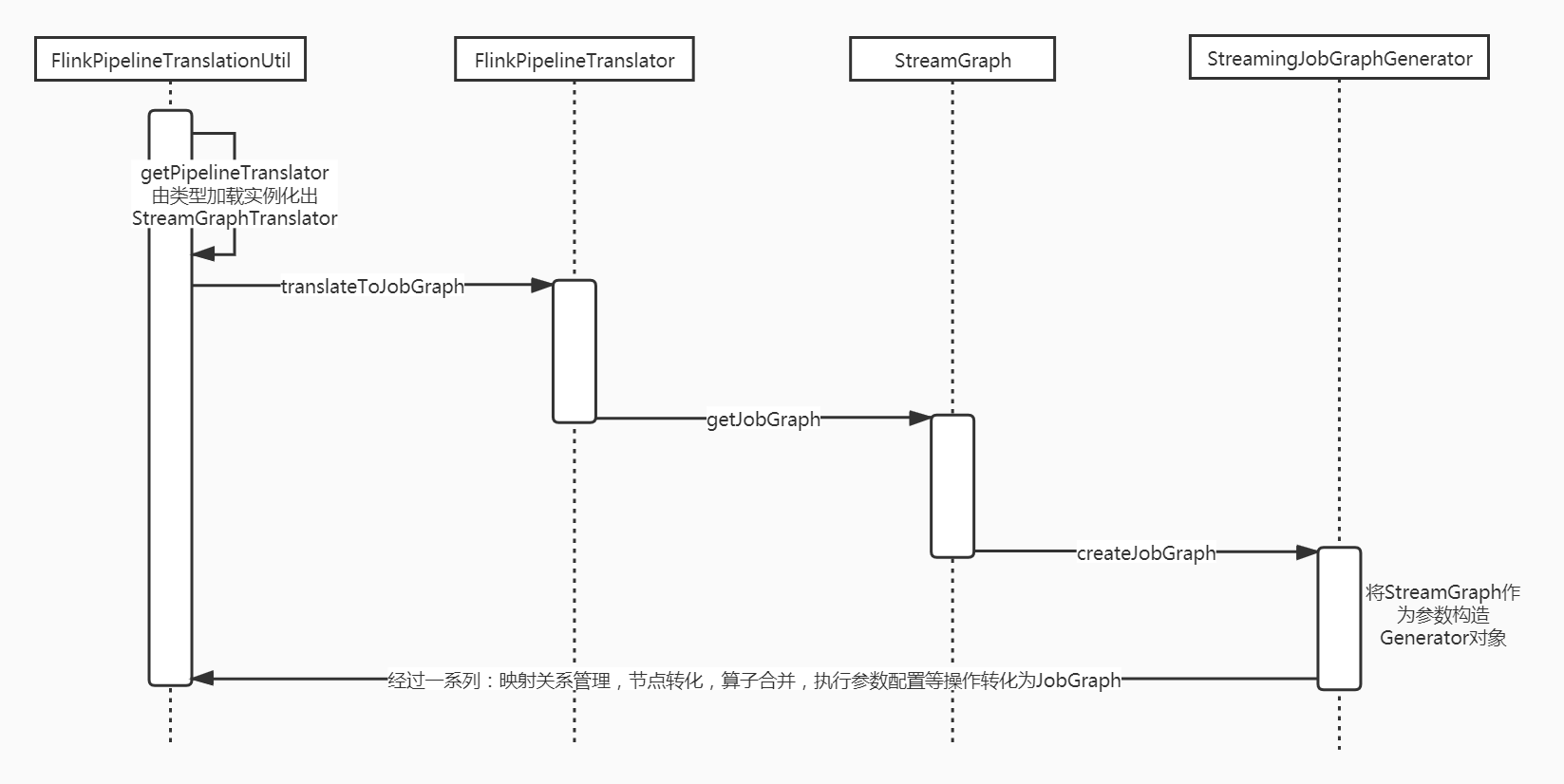
2 简单来看可以分为两部分:
第一部分是通过一些util、translator、generator等类将职责进行解耦、托管和分离,期间涉及FlinkPipelineTranslationUtil、FlinkPipelineTranslator/StreamGraphTranslator、StreamingJobGraphGenerator等。
第二部分最终转换的操作落在StreamingJobGraphGenerator中,涉及StreamGraph、StreamEdge、StreamConfig、JobGraph、JobVertex等,下面主要关注点在第二步:
3 StreamingJobGraphGenerator的构造方法和成员变量
唯一构造方法:
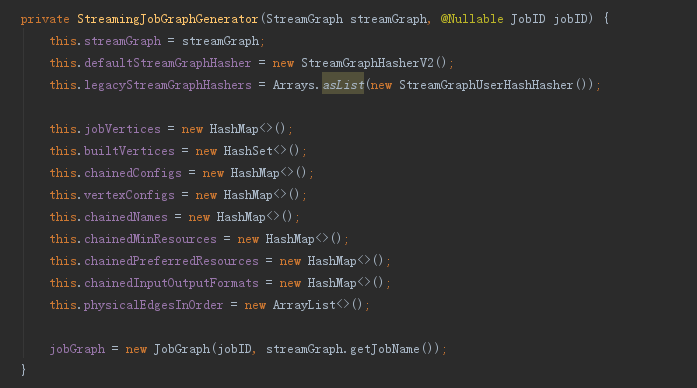
将StreamGraph对象作为参数传递进来,并初始化一个JobGraph空壳和一系列的成员变量(主要是map,需要保持各种对应关系),用于存储转换的中间态

从命名不难看出各个map的作用,核心套路大多是用节点id或者节点的hash值映射节点
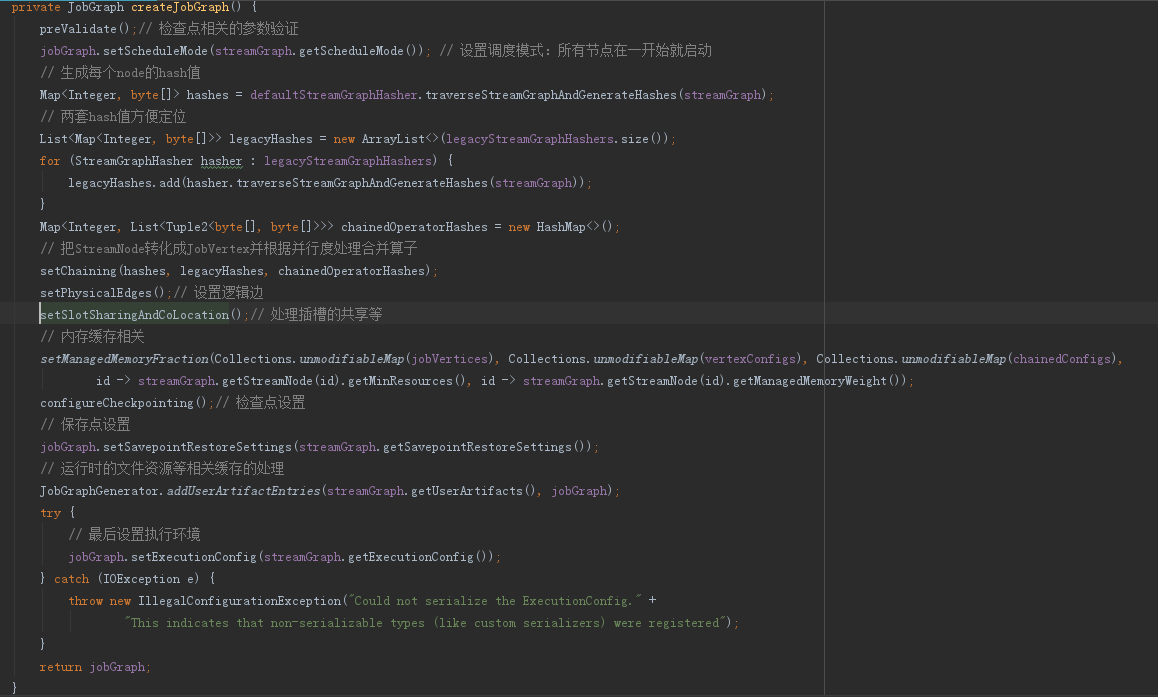
4 StreamingJobGraphGenerator.createJobGraph方法
主要要弄清楚StreamNode转化成JobVertex、算子合并、边上下游关系转换的核心逻辑
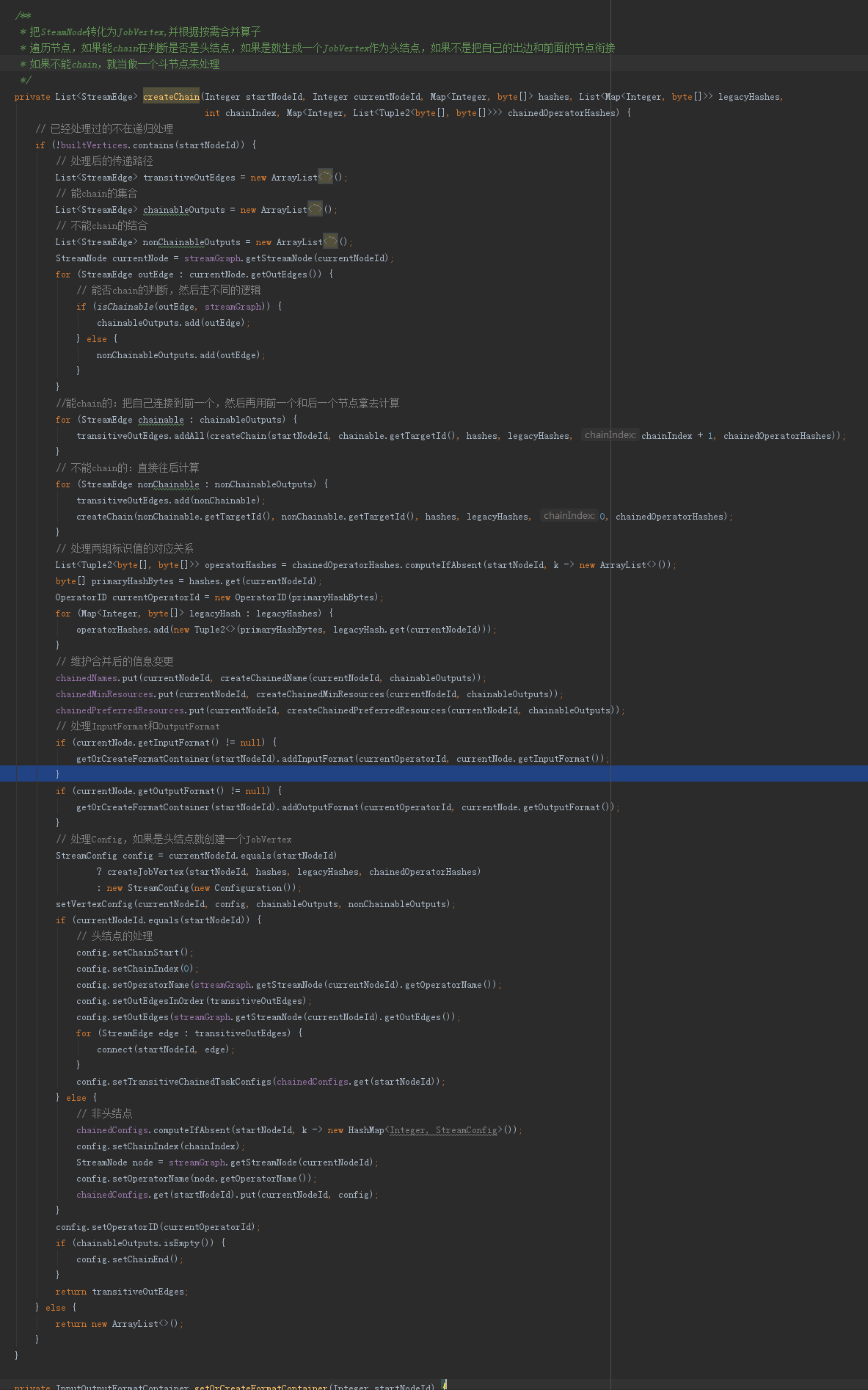
4.1 StreamingJobGraphGenerator.createChain方法
这里主要是把SteamNode转化为JobVertex,并根据按需合并算子
步骤:
a、在调用时遍历节点,并通过builtVertices保存已经处理过的节点
b,判断outEdge能不能chain,分门别类放到不同的List集合中待处理
c、对于能chain的节点,就把自己衔接到前一个上面去,把衔接的路径存储下来,然后再把衔接的前一个和自己的后一个再递归调用拿去计算
d、对于不能chain的节点,就作为一个头节点来单独处理掉
e、然后维护单个/合并后的关系,包括合并后的命名、资源、格式化方式等
f、处理转换逻辑,如果是头就创建个JobVertex返回StreamConfig,如果不是就创建个StreamConfig
4.2 StreamingJobGraphGenerator.isChainable方法
决定StreamEdge两边能否chian的逻辑:

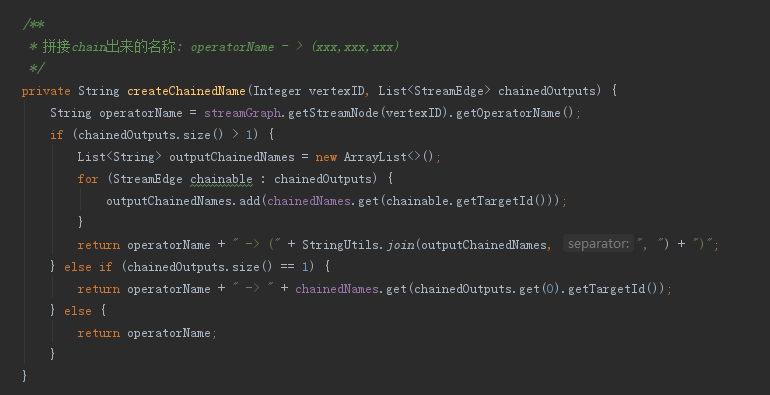
4.3 StreamingJobGraphGenerator.createChainedName方法
这个是处理合并后的命名,在日志中或者生成的图中可以看到
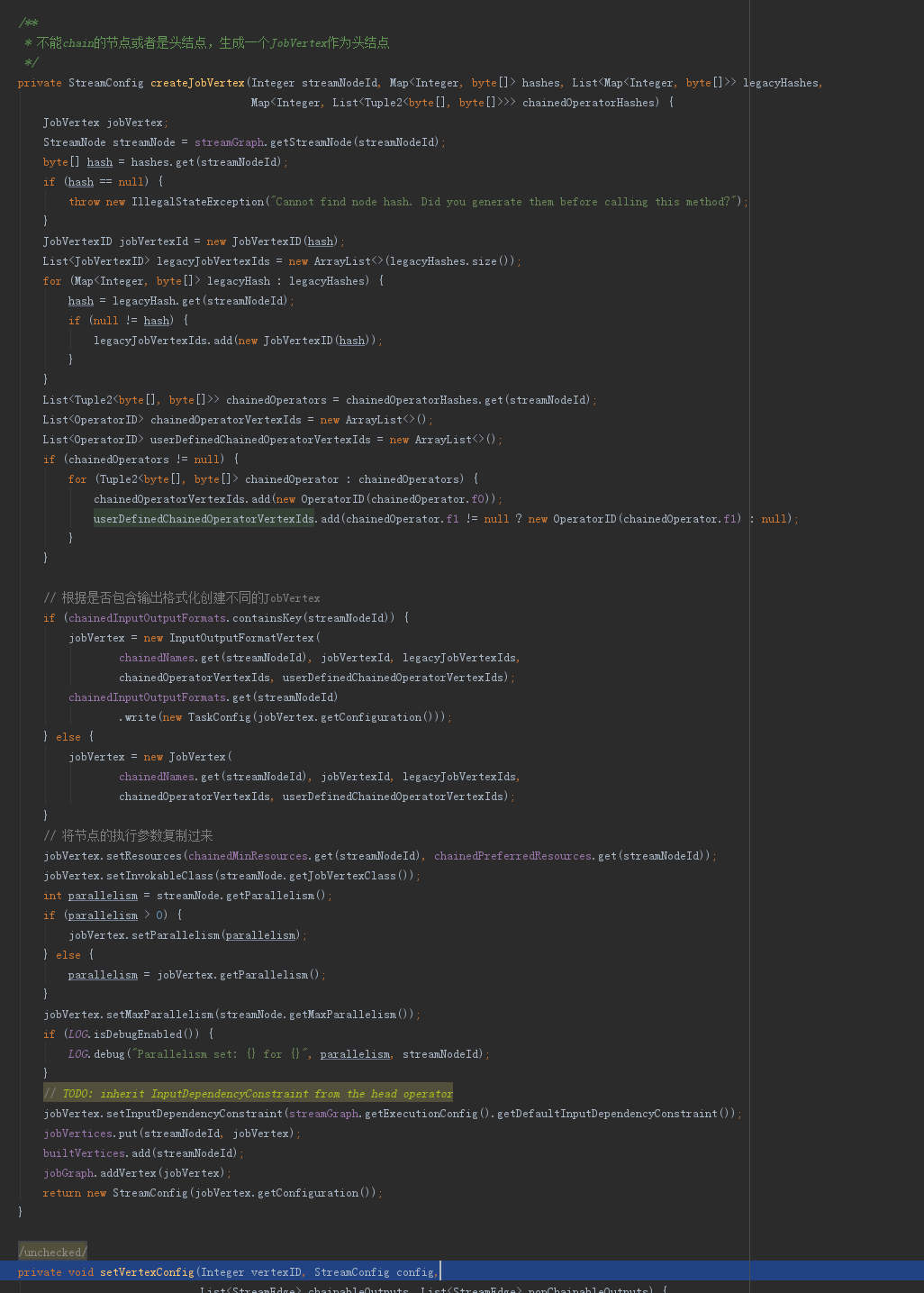
4.4 StreamingJobGraphGenerator.createJobVertex方法
这里是StreamNode转变为JobVertex的真正实现,其实也很简单,第一步根据节点的输出new出不同类型的JobVertex,第二步把StreamNode的执行参数复制过来,第三步把自己和相关的映射关系填充到jobGraph和相应的map中去
4.5 StreamingJobGraphGenerator.connect方法
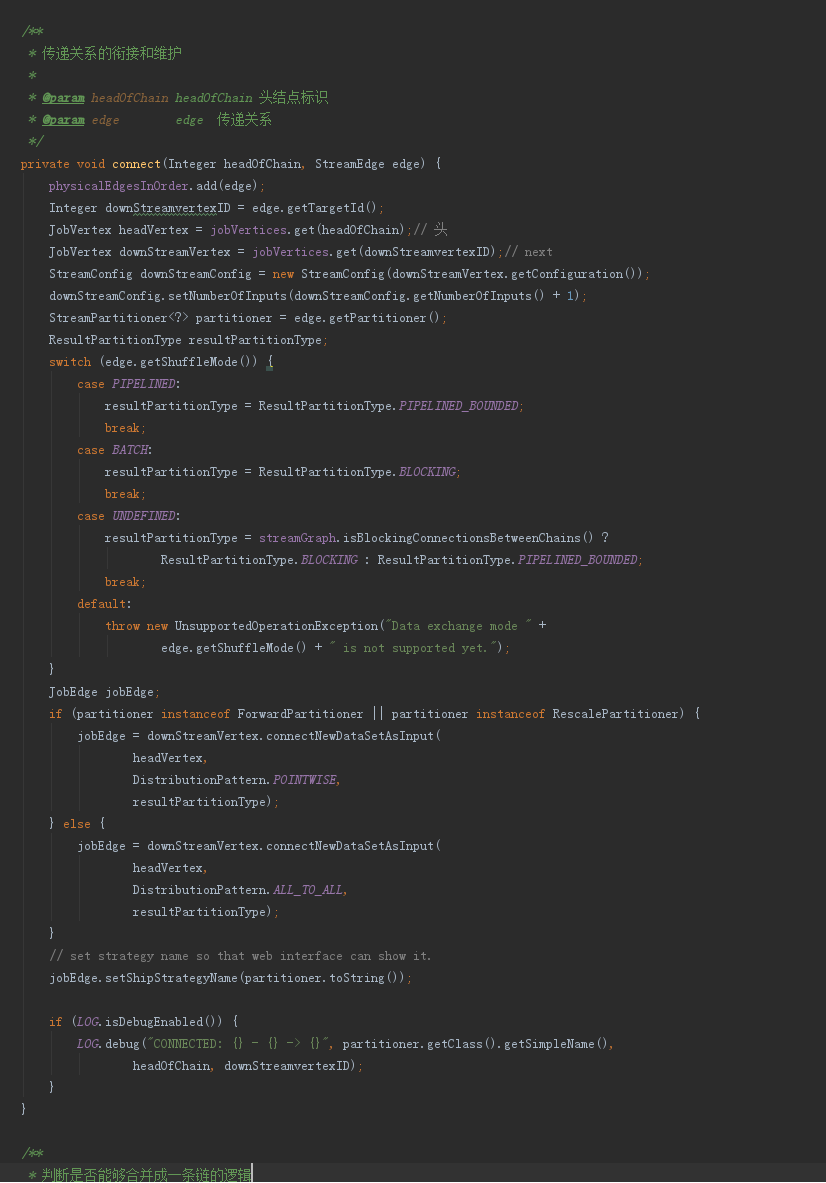
5 总的来看由于在StreamGraph中已经构建好了DAG的关系和映射,此过程中最核心的逻辑就是在createChain合并算子的过程。
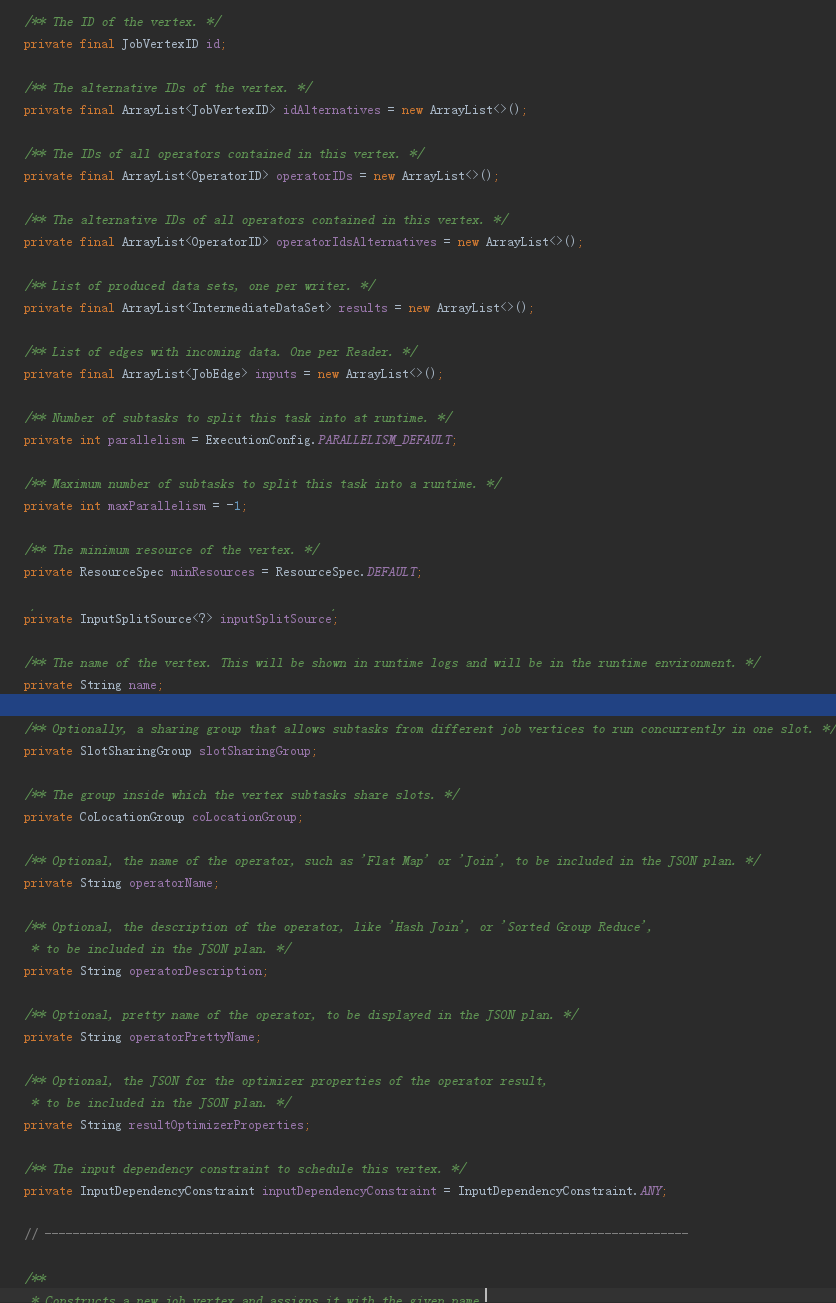
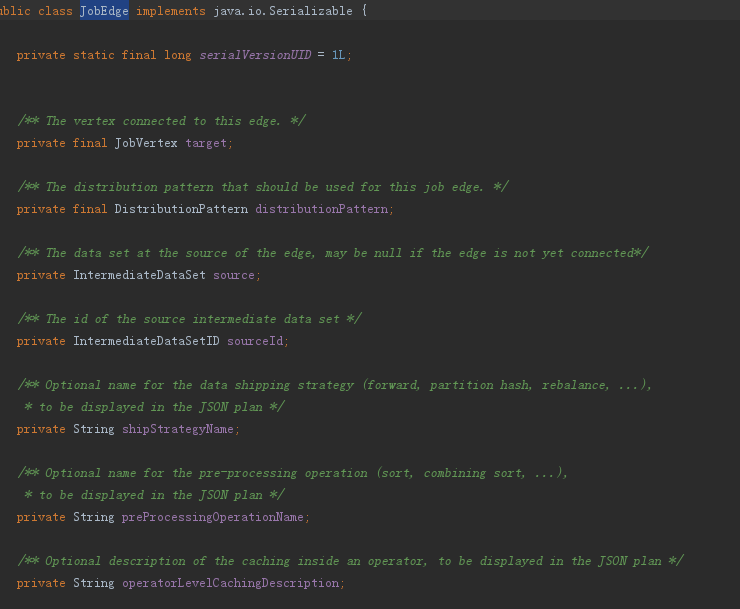
6、下面是JobGraph、JobVertex和JobEdge的主要属性,可以对比StreamGraph、StreamNode和StreamEdge来理解