
分布式机器学习:模型平均MA与弹性平均EASGD(PySpark)
- 2022 年 6 月 30 日
- 笔记
计算机科学一大定律:许多看似过时的东西可能过一段时间又会以新的形式再次回归。 1 模型平均方法(MA) 1.1 算法描述 …
Continue Reading计算机科学一大定律:许多看似过时的东西可能过一段时间又会以新的形式再次回归。 1 模型平均方法(MA) 1.1 算法描述 …
Continue Reading
1 分布式机器学习概述 大规模机器学习训练常面临计算量大、训练数据大(单机存不下)、模型规模大的问题,对此分布式机器学习 …
Continue Reading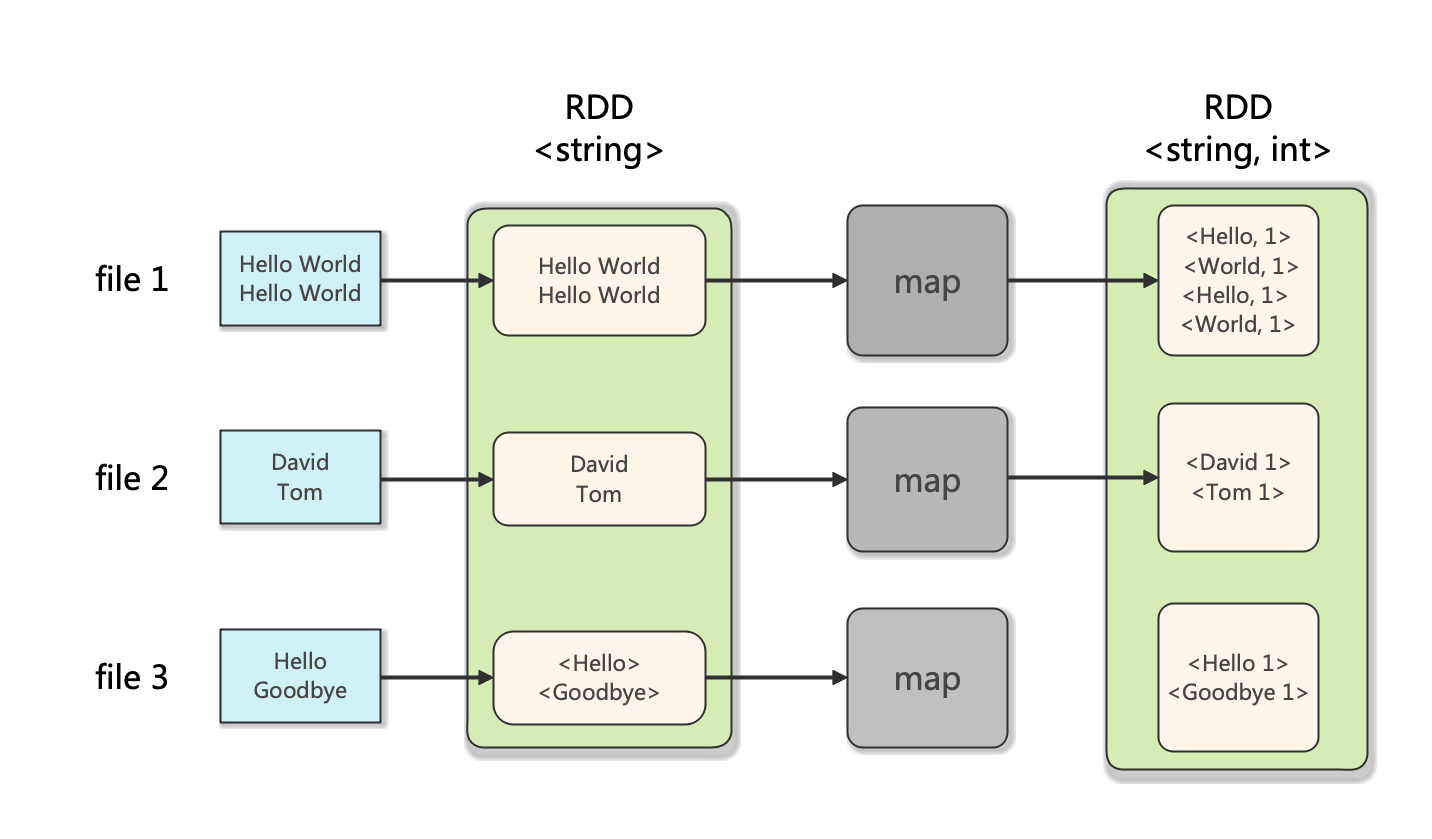
1 导引 我们在博客《Hadoop: 单词计数(Word Count)的MapReduce实现 》中学习了如何用Hado …
Continue Reading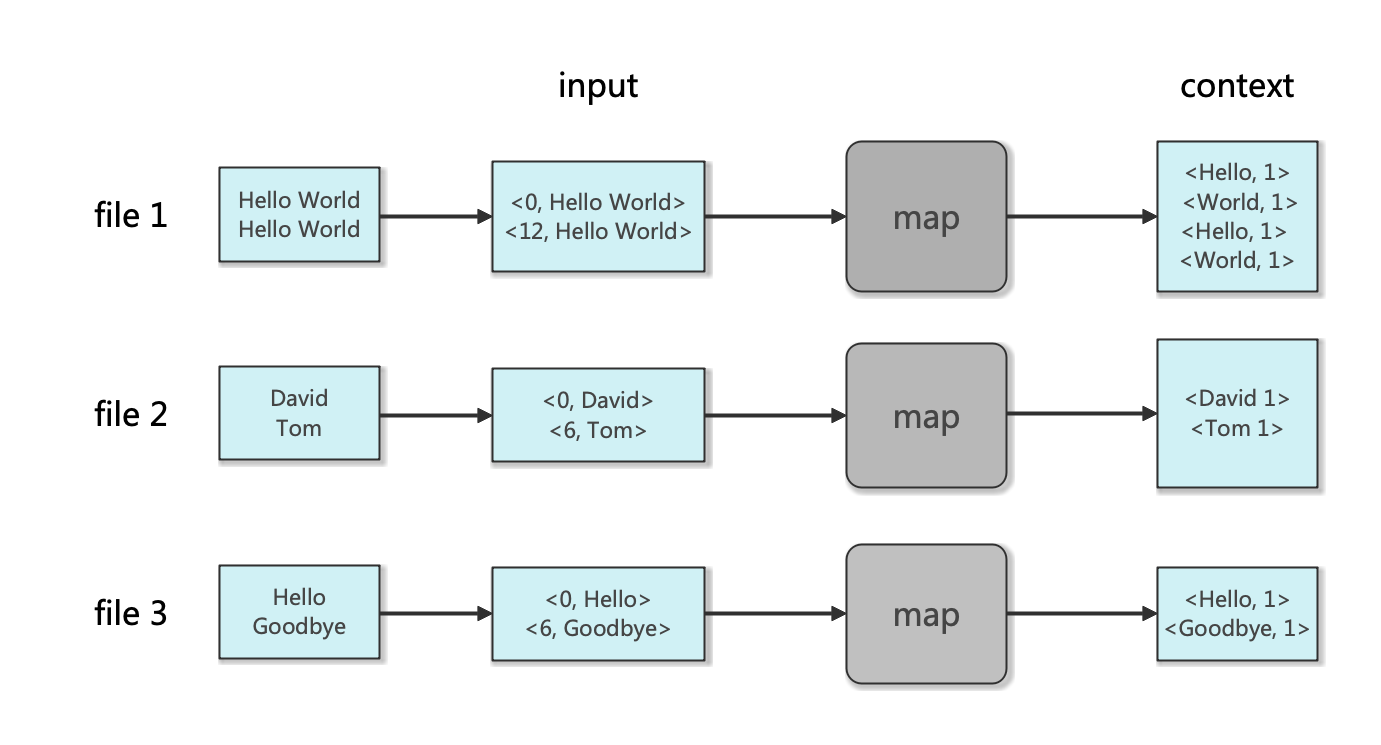
1.Map与Reduce过程 1.1 Map过程 首先,Hadoop会把输入数据划分成等长的输入分片(input spl …
Continue Reading摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序。 …
Continue Reading
因为在我最近的科研中需要用到分布式的社区检测(也称为图聚类(graph clustering))算法,专门去查找了相关文 …
Continue Reading
在上一篇博文《分布式机器学习中的模型聚合》(链接://www.cnblogs.com/orion-orion/p/156 …
Continue Reading
论文1在联邦(分布式)学习的情景下引入了多任务学习,其采用的手段是使每个client/task节点的训练数据分布不同 …
Continue Reading今天开始跑分布式机器学习论文实验了,这里介绍一下论文的常用数据集(因为我的研究领域是分布式机器学习,所以下面列出的数据集 …
Continue Reading
前言 Catalyst是Spark SQL核心优化器,早期主要基于规则的优化器RBO,后期又引入基于代价进行优化的CBO …
Continue Reading