实际应用效果不佳?来看看提升深度神经网络泛化能力的核心技术(附代码)

💡 作者:韩信子@ShowMeAI
📘 深度学习实战系列://www.showmeai.tech/tutorials/42
📘 本文地址://www.showmeai.tech/article-detail/317
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

神经网络是一种由神经元、层、权重和偏差组合而成的特殊机器学习模型,随着近些年深度学习的高速发展,神经网络已被广泛用于进行预测和商业决策并大放异彩。
神经网络之所以广受追捧,是因为它们能够在学习能力和性能方面远远超过任何传统的机器学习算法。 现代包含大量层和数十亿参数的网络可以轻松学习掌握互联网海量数据下的模式和规律,并精准预测。

随着AI生态和各种神经网络工具库(Keras、Tensorflow 和 Pytorch 等)的发展,搭建神经网络拟合数据变得非常容易。但很多时候,在用于学习的训练数据上表现良好的模型,在新的数据上却效果不佳,这是模型陷入了‘过拟合’的问题中了,在本篇内容中,ShowMeAI将给大家梳理帮助深度神经网络缓解过拟合提高泛化能力的方法。

💡 数据增强
📌 技术介绍
缓解过拟合最直接的方法是增加数据量,在数据量有限的情况下可以采用数据增强技术。 数据增强是从现有训练样本中构建新样本的过程,例如在计算机视觉中,我们会为卷积神经网络扩增训练图像。
具体体现在计算机视觉中,我们可以对图像进行变换处理得到新突破,例如位置和颜色调整是常见的转换技术,常见的图像处理还包括——缩放、裁剪、翻转、填充、旋转和平移。
📌 手动数据处理&增强
我们可以基于PIL库手动对图像处理得到新图像以扩增样本量
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open("/content/drive/MyDrive/cat.jpg")
flipped_img = img.transpose(Image.FLIP_LEFT_RIGHT) ### 翻转
roated_img = img.transpose(Image.ROTATE_90) ## 旋转
scaled_img = img.resize((400, 400)) ### 图像缩放
cropped_img = img.crop((100,50,400,200)) # 裁剪
# 颜色变换
width, height = img.size
pad_pixel = 20
canvas = Image.new(img.mode, (width+pad_pixel, height+pad_pixel), 'blue')
canvas.paste(img, (pad_pixel//2,pad_pixel//2))
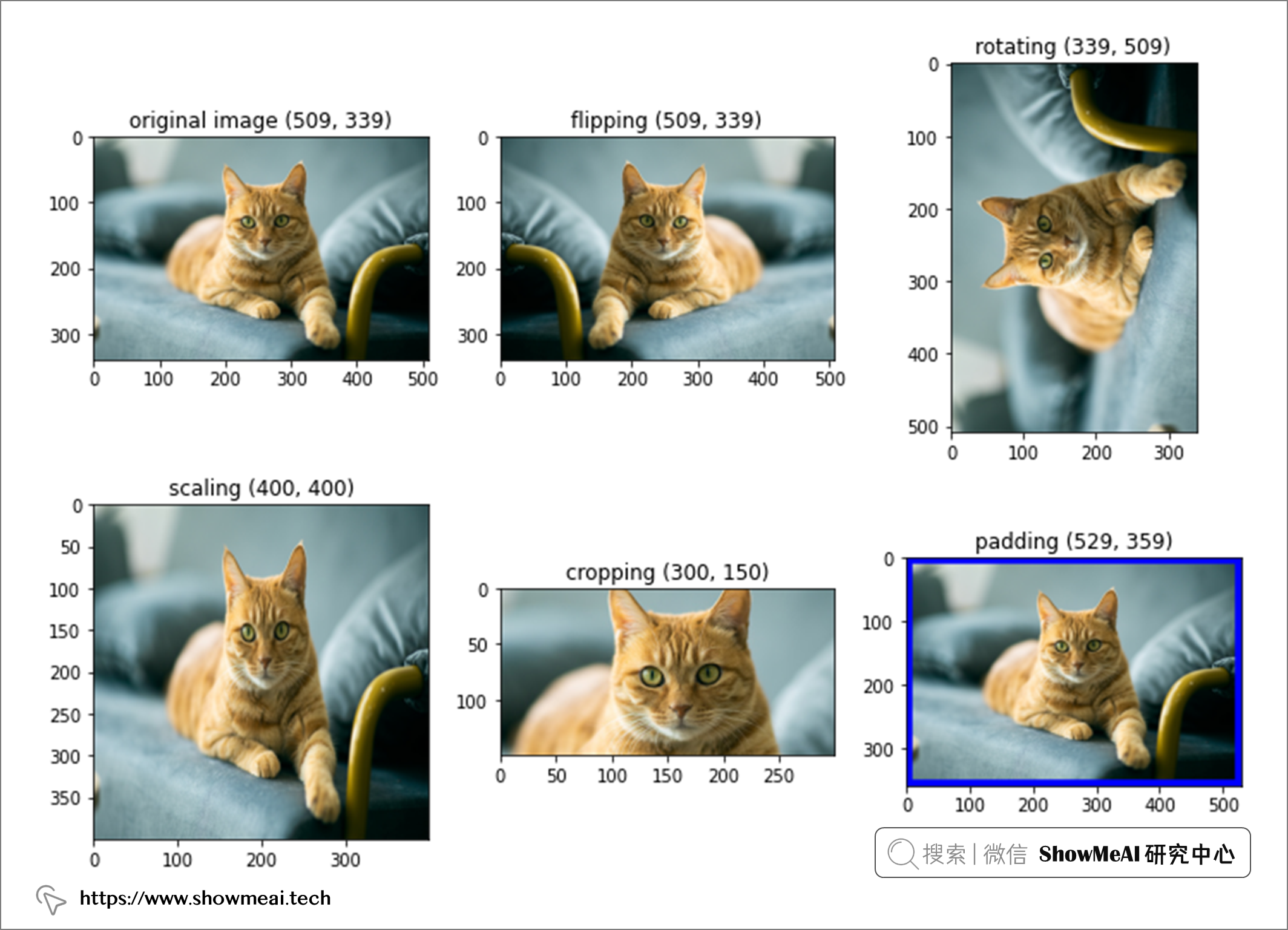
颜色增强处理通过改变图像的像素值来改变图像的颜色属性。更细一点讲,可以通过改变亮度、对比度、饱和度、色调、灰度、膨胀等来处理。
from PIL import Image, ImageEnhance
import matplotlib.pyplot as plt
img = Image.open("/content/drive/MyDrive/cat.jpg")
enhancer = ImageEnhance.Brightness(img)
img2 = enhancer.enhance(1.5) ## 更亮
img3 = enhancer.enhance(0.5) ## 更暗
imageenhancer = ImageEnhance.Contrast(img)
img4 = enhancer.enhance(1.5) ## 提升对比度
img5 = enhancer.enhance(0.5) ## 降低对比度
enhancer = ImageEnhance.Sharpness(img)
img6 = enhancer.enhance(5) ## 锐化

虽然可以通过使用像 pillow 和 OpenCV 这样的图像处理库来手动执行图像增强,但更简单且耗时更少的方法是使用 📘Keras API 来完成。
关于keras的核心知识,ShowMeAI为其制作了速查手册,欢迎大家通过如下文章快查快用:
Keras 是一个用 Python 编写的深度学习 API,可以运行在机器学习平台 Tensorflow 之上。 Keras 有许多可提高实验速度的内置方法和类。 在 Keras 中,我们有一个 📘ImageDataGenerator类,它为图像增强提供了多个选项。
keras.preprocessing.image.ImageDataGenerator()
📘参数:
- featurewise_center: 布尔值。将输入数据的均值设置为 0,逐特征进行。
- samplewise_center: 布尔值。将每个样本的均值设置为 0。
- featurewise_std_normalization: Boolean. 布尔值。将输入除以数据标准差,逐特征进行。
- samplewise_std_normalization: 布尔值。将每个输入除以其标准差。
- zca_epsilon: ZCA 白化的 epsilon 值,默认为 1e-6。
- zca_whitening: 布尔值。是否应用 ZCA 白化。
- rotation_range: 整数。随机旋转的度数范围。
- width_shift_range: 浮点数、一维数组或整数
- float: 如果 <1,则是除以总宽度的值,或者如果 >=1,则为像素值。
- 1-D 数组: 数组中的随机元素。
- int: 来自间隔
(-width_shift_range, +width_shift_range)之间的整数个像素。 width_shift_range=2时,可能值是整数[-1, 0, +1],与width_shift_range=[-1, 0, +1]相同;而width_shift_range=1.0时,可能值是[-1.0, +1.0)之间的浮点数。
- height_shift_range: 浮点数、一维数组或整数
- float: 如果 <1,则是除以总宽度的值,或者如果 >=1,则为像素值。
- 1-D array-like: 数组中的随机元素。
- int: 来自间隔
(-height_shift_range, +height_shift_range)之间的整数个像素。 height_shift_range=2时,可能值是整数[-1, 0, +1],与height_shift_range=[-1, 0, +1]相同;而height_shift_range=1.0时,可能值是[-1.0, +1.0)之间的浮点数。
- shear_range: 浮点数。剪切强度(以弧度逆时针方向剪切角度)。
- zoom_range: 浮点数 或
[lower, upper]。随机缩放范围。如果是浮点数,[lower, upper] = [1-zoom_range, 1+zoom_range]。 - channel_shift_range: 浮点数。随机通道转换的范围。
- fill_mode: {“constant”, “nearest”, “reflect” or “wrap”} 之一。默认为 ‘nearest’。输入边界以外的点根据给定的模式填充。
- cval: 浮点数或整数。用于边界之外的点的值,当
fill_mode = "constant"时。 - horizontal_flip: 布尔值。随机水平翻转。
- vertical_flip: 布尔值。随机垂直翻转。
- rescale: 重缩放因子。默认为 None。如果是 None 或 0,不进行缩放,否则将数据乘以所提供的值(在应用任何其他转换之前)。
- preprocessing_function: 应用于每个输入的函数。这个函数会在任何其他改变之前运行。这个函数需要一个参数:一张图像(秩为 3 的 Numpy 张量),并且应该输出一个同尺寸的 Numpy 张量。
- data_format: 图像数据格式,{“channels_first”, “channels_last”} 之一。”channels_last” 模式表示图像输入尺寸应该为
(samples, height, width, channels),”channels_first” 模式表示输入尺寸应该为(samples, channels, height, width)。默认为 在 Keras 配置文件~/.keras/keras.json中的image_data_format值。如果你从未设置它,那它就是 “channels_last”。 - validation_split: 浮点数。Float. 保留用于验证的图像的比例(严格在0和1之间)。
- dtype: 生成数组使用的数据类型。
📌 基于 TensorFlow 的数据增强
如果要基于 TensorFlow 实现数据增强,示例代码如下:
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
brightness_range= [0.5, 1.5],
rescale=1./255,
shear_range=0.2,
zoom_range=0.4,
horizontal_flip=True,
fill_mode='nearest',
zca_epsilon=True)
path = '/content/drive/MyDrive/cat.jpg' ## Image Path
img = load_img(f"{path}")
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
### 基于数据增强构建25张图片并存入aug_img文件夹
for batch in datagen.flow(x, batch_size=1, save_to_dir="/content/drive/MyDrive/aug_imgs", save_prefix='img', save_format='jpeg'):
i += 1
if i > 25:
break

💡 Dropout 随机失活
关于随机失活的详细原理知识,大家可以查看ShowMeAI制作的深度学习系列教程和对应文章
📌 技术介绍
Dropout 层是解决深度神经网络中过度拟合的最常用方法。 它通过动态调整网络来减少过拟合的概率。
Dropout 层 随机 在训练阶段以概率rate随机将输入单元丢弃(可以认为是对输入置0),未置0的输入按 1/(1 – rate) 放大,以使所有输入的总和保持不变。
丢弃率rate 是主要参数,范围从 0 到 1。0.5 的rate取值意味着 50% 的神经元在训练阶段从网络中随机丢弃。
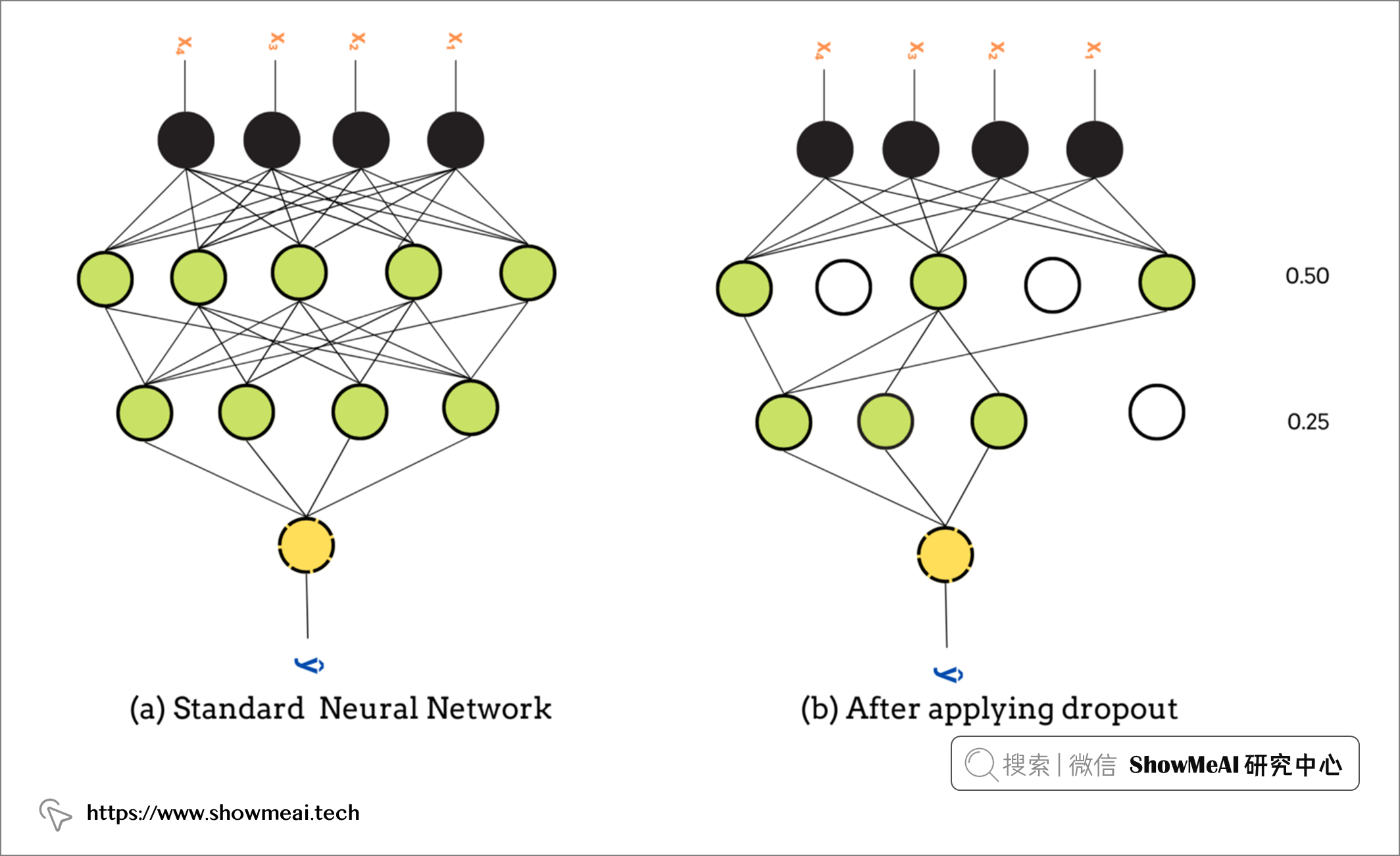
TensorFlow中的dropout使用方式如下
tf.keras.layers.Dropout(rate, noise_shape=None, seed=None)
📘参数
rate: 在 0 和 1 之间浮动,丢弃概率。noise_shape:1D 整数张量,表示将与输入相乘的二进制 dropout 掩码的形状。seed: 随机种子。
📌 基于TensorFlow应用Dropout
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Reshape
from tensorflow.keras.layers import Dropout
def create_model():
model = Sequential()
model.add(Dense(60, input_shape=(60,), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(30, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
return model
adam = tf.keras.optimizers.Adam()
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
model = create_model()
model.summary()
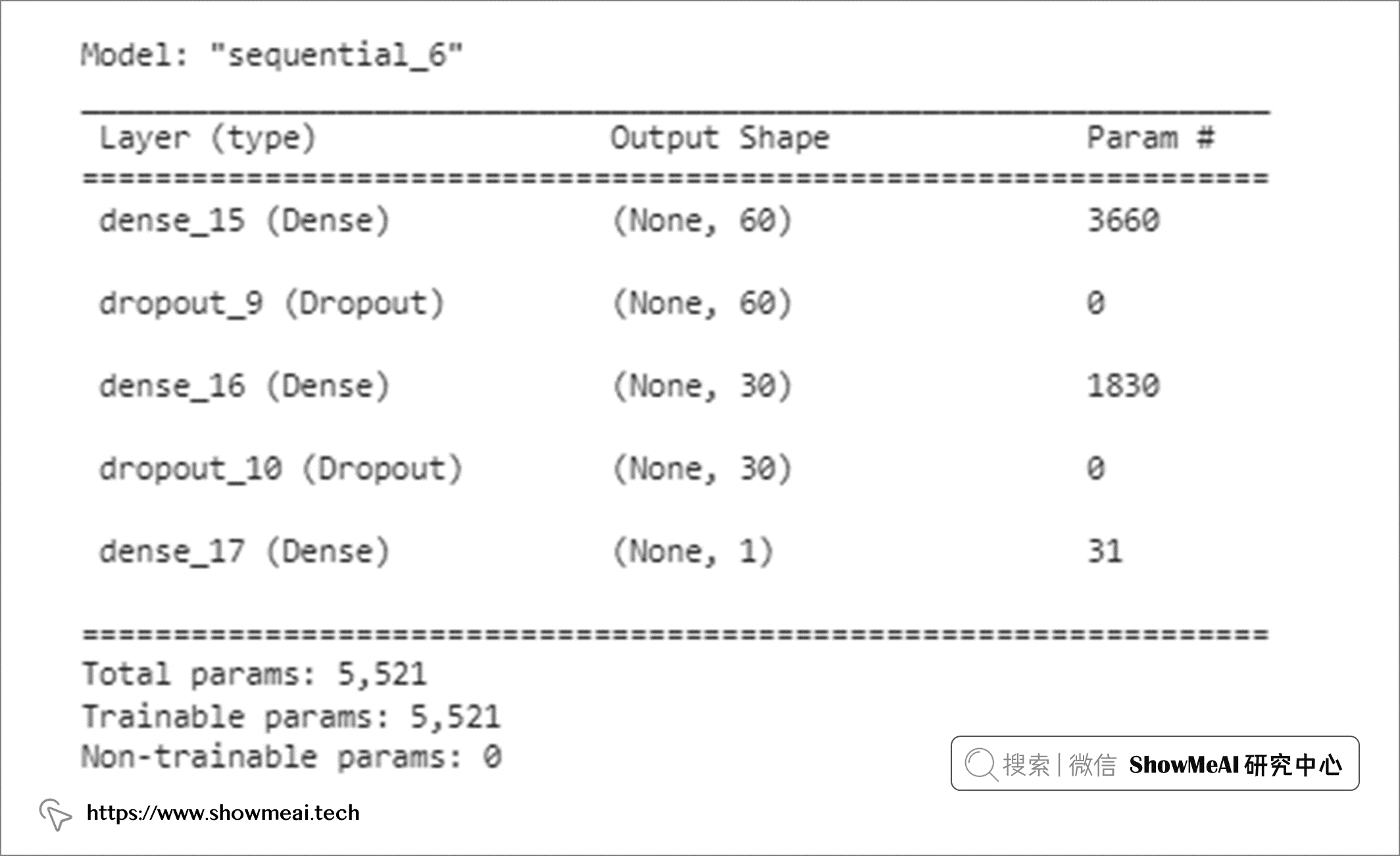
在向神经网络添加 dropout 层时,有一些技巧大家可以了解一下:
- 一般会使用 20%-50% 的小的 dropout 值,太大的 dropout 值可能会降低模型性能,同时选择非常小的值不会对网络产生太大影响。
- 一般在大型网络中会使用dropout层以获得最大性能。
- 输入层和隐层上都可以使用 dropout,表现都良好。
💡 L1 和 L2 正则化
关于正则化的详细原理知识,大家可以查看ShowMeAI制作的深度学习系列教程和对应文章
📌 技术介绍
正则化是一种通过惩罚损失函数来降低网络复杂性的技术。 它为损失函数添加了一个额外的权重约束部分,它在模型过于复杂的时候会进行惩罚(高loss),简单地说,正则化限制权重幅度过大。
L1 正则化的公式如下:

L2 正则化公式如下:

📌 基于TensorFlow应用正则化
在TensorFlow搭建神经网络时,我们可以直接在添加对应的层次时,通过参数设置添加正则化项。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Reshape
from tensorflow.keras.layers import Dropout
def create_model():
# 构建模型
model = Sequential()
# 添加正则化
model.add(Dense(60, input_shape=(60,), activation='relu', kernel_regularizer=keras.regularizers.l1(0.01)))
model.add(Dropout(0.2))
# 添加正则化
model.add(Dense(30, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
return model
adam = tf.keras.optimizers.Adam()
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
model = create_model()
model.summary()
💡 Early Stopping / 早停止
📌 技术介绍
在深度学习中,一个 epoch指的是完整训练数据进行一轮的训练。迭代轮次epoch的多少对于模型的状态影响很大:如果我们的 epoch 设置太大,训练时间越长,也更可能导致模型过拟合;但过少的epoch可能会导致模型欠拟合。
Early stopping早停止是一种判断迭代轮次的技术,它会观察验证集上的模型效果,一旦模型性能在验证集上停止改进,就会停止训练过程,它也经常被使用来缓解模型过拟合。
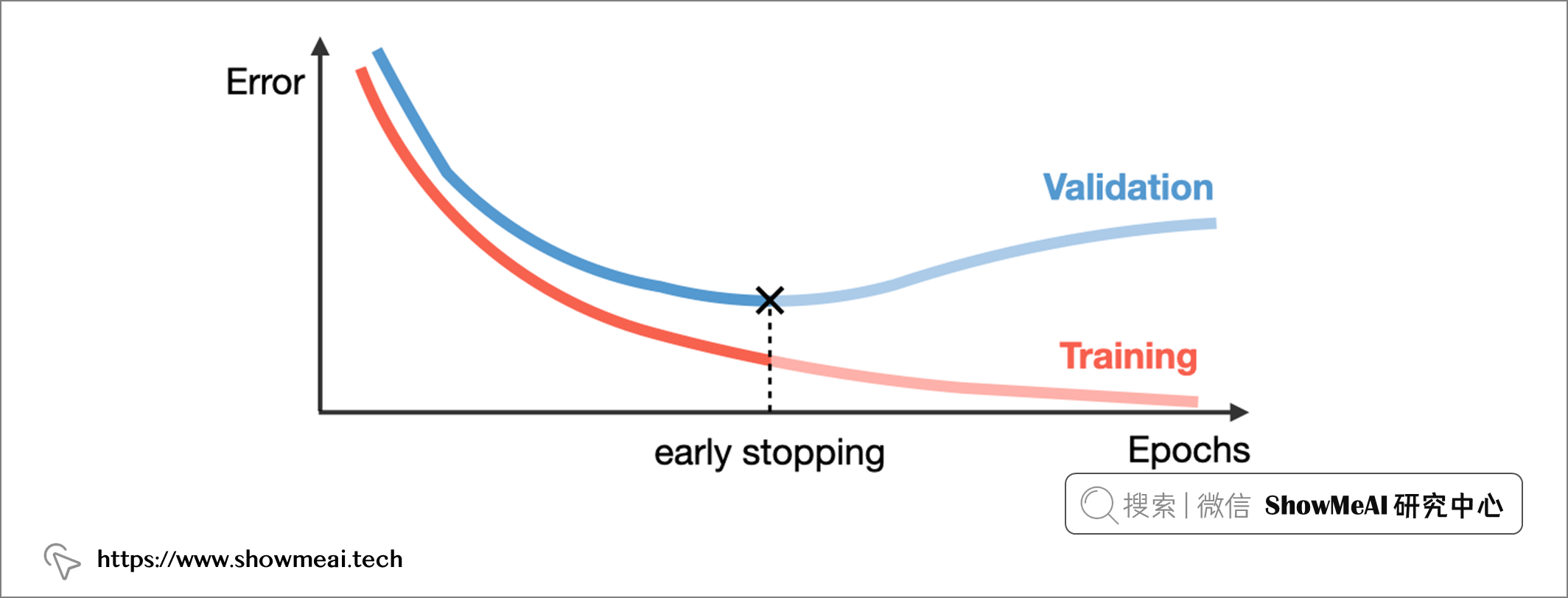
📌 基于TensorFlow应用Early stopping
Keras 有一个回调函数,可以直接完成early stopping。
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=0,
verbose=0,
mode='auto',
baseline=None,
restore_best_weights=False
)
📘参数
- monitor: 被监测的数据。
- min_delta: 在被监测的数据中被认为是提升的最小变化, 例如,小于 min_delta 的绝对变化会被认为没有提升。
- patience: 没有进步的训练轮数,在这之后训练就会被停止。
- verbose: 详细信息模式。
- mode: {auto, min, max} 其中之一。 在
min模式中, 当被监测的数据停止下降,训练就会停止;在max模式中,当被监测的数据停止上升,训练就会停止;在auto模式中,方向会自动从被监测的数据的名字中判断出来。 - baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。
- restore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。
from tensorflow.keras.callbacks import EarlyStoppingearly_stopping = EarlyStopping(monitor='loss', patience=2)history = model.fit(
X_train,
y_train,
epochs= 100,
validation_split= 0.20,
batch_size= 50,
verbose= "auto",
callbacks= [early_stopping]
)
💡 总结
ShowMeAI在本篇内容中,对缓解过拟合的技术做了介绍和应用讲解,大家可以在实践中选择和使用。‘数据增强’技术将通过构建和扩增样本集来缓解模型过拟合,dropout 层通过随机丢弃一些神经元来降低网络复杂性,正则化技术将惩罚网络训练得到的大幅度的权重,early stopping 会防止网络过度训练和学习。
参考资料
- 📘 Keras://keras.io/
- 📘 ImageDataGenerator://keras.io/zh/preprocessing/image/
- 📘 AI垂直领域工具库速查表 | Keras 速查表://www.showmeai.tech/article-detail/110
- 📘 深度学习教程:吴恩达专项课程 · 全套笔记解读://www.showmeai.tech/tutorials/35
- 📘 深度学习教程 | 深度学习的实用层面://www.showmeai.tech/article-detail/216
- 📘 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读://www.showmeai.tech/tutorials/37
- 📘 深度学习与CV教程(7) | 神经网络训练技巧 (下)://www.showmeai.tech/article-detail/266