JAVA系列之JVM内存调优
一、前提
JVM性能调优牵扯到各方面的取舍与平衡,往往是牵一发而动全身,需要全盘考虑各方面的影响。在优化时候,切勿凭感觉或经验主义进行调整,而是需要通过系统运行的客观数据指标,不断找到最优解。同时,在进行性能调优前,您需要理解并掌握以下的相关基础理论知识:
1、JVM垃圾收集器和垃圾回收算法
2、JVM性能监控常用工具和命令
3、JVM运行时数据区域
4、能够读懂gc日志
5、内存分配与回收策略
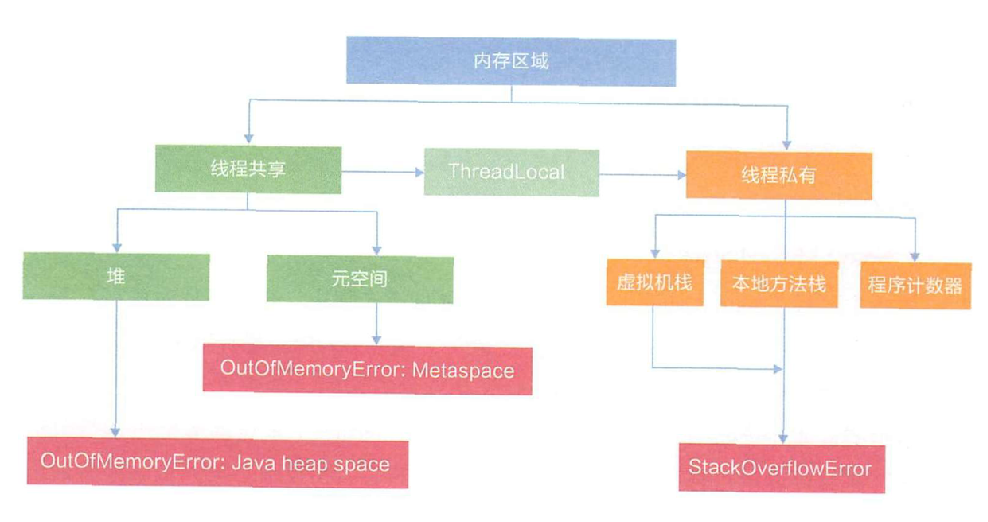
二、JVM内存结构
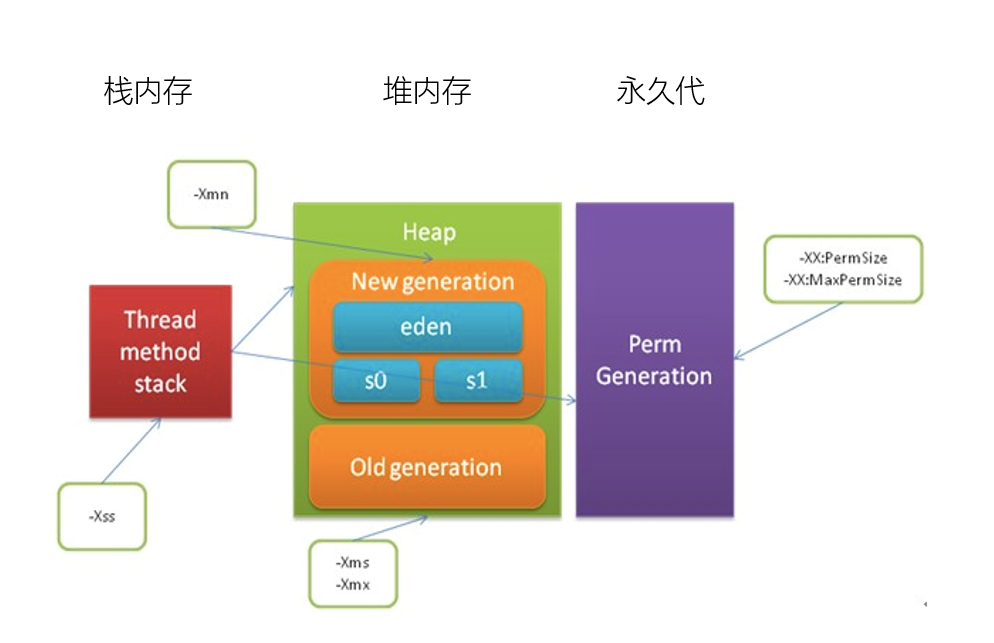
从上图可以看出,整个JVM内存是由栈内存、堆内存和永久代构成。
年轻代(New generation) = eden + s0 + s1
堆内存 = 年轻代 + 老年代(Old generation)
JDK1.8以前: JVM内存 = 栈内存 + 堆内存 + 永久代
JDK1.8以后: 由元空间取代了永久代,元空间并不在JVM中,而是使用本地内存。因此JVM内存 = 栈内存 + 堆内存
1、栈内存
栈内存归属于单个线程,也就是每创建一个线程都会分配一块栈内存,而栈中存储的东西只有本线程可见,属于线程私有。
栈的生命周期与线程一致,一旦线程结束,栈内存也就被回收。
栈中存放的内容主要包括:8大基本类型 + 对象的引用 + 实例的方法
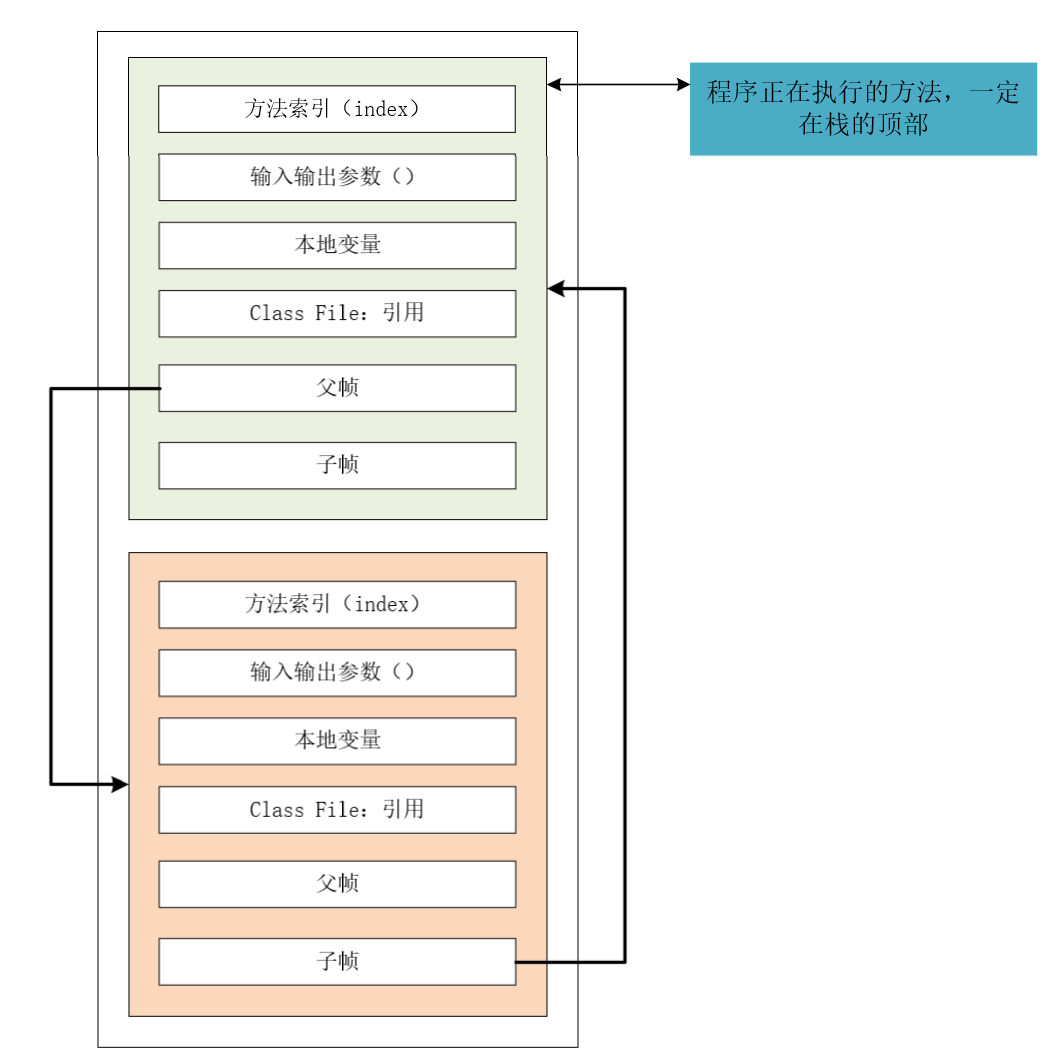
2、堆内存
堆内存是由年轻代和老年代构成,JDK1.8以后,永久代被元空间取代,使用直接内存,不占用堆内存。堆内存是Jvm中空间最大的区域,所有线程共享堆,所有的数组以及内存对象的实例都在此区域分配。我们常说的垃圾回收就是作用于堆内存。
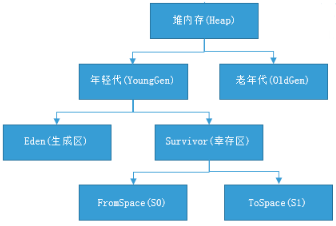
Eden区占大容量,Survivor两个区占小容量,默认比例是8:1:1
3、永久代(元空间)
这个区域是常驻内存的。用来存放JDK自身携带的Class对象。Interface元数据,存储的是Java运行时的一些环境。这个区域不存在垃圾回收!关闭虚拟机就会释放这个区域的内存。
当发现系统中元空间占用内存比较大时,排查方向是否加载了大量的第三方jar包,Tomcat部署了太多应用,大量动态生成的反射类等。
三、JVM常用参数
首先JVM内存限制于实际的最大物理内存,假设物理内存无限大的话,JVM内存的最大值跟操作系统有很大的关系。简单的说就32位处理器虽然可控内存空间有4GB,但是具体的操作系统会给一个限制,这个限制一般是2GB-3GB(一般来说Windows系统下为1.5G-2G,Linux系统下为2G-3G),而64bit以上的处理器就不会有限制。
1、堆大小设置
java -server -Xmx4g -Xms4g -Xmn2g –Xss128k
-Xmx4g:设置JVM最大可用内存为4g。
-Xms4g:设置JVM最小可用内存为4g。一般配置为与-Xmx相同,避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小 + 年老代大小,所以增大年轻代后,将会减小年老代大小。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程默认大小为1M,以前每个线程大小为256K。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。
java -server -Xmx4g -Xms4g -Xmn2g –Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxMetaspaceSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4: 设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4: 设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxMetaspaceSize=16m: 设置元空间最大可分配大小为16m。
-XX:MaxTenuringThreshold=0: 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概率。
2、垃圾回收器选择
JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
2.1 吞吐量优先的并行收集器
java -server -Xmx4g -Xms4g -Xmn2g –Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC -XX:+UseAdaptiveSizePolicy
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
2.2 响应时间优先的并发收集器
java -server -Xmx4g -Xms4g -Xmn2g –Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:+UseConcMarkSweepGC: 设置年老代为并发收集
-XX:+UseParNewGC: 设置年轻代为并行收集。可与CMS收集同时使用
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
3、其他辅助配置
GC日志打印
-XX:+PrintGC:输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails:输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
OOM生成dump文件
-XX:+HeapDumpOnOutOfMemoryError 表示jvm发生oom异常时,自动生成dump文件
-XX:HeapDumpPath= 表示生成dump文件的存放目录
四、内存溢出排查
一般来说内存溢出主要分为以下几类:
堆溢出(java.lang.OutOfMemoryError: Java heap space)
栈深度不够( java.lang.StackOverflowError)
栈线程数不够(java.lang.OutOfMemoryError: unable to create new native thread)
元空间溢出(java.lang.OutOfMemoryError: Metaspace)
1、元空间溢出(java.lang.OutOfMemoryError: Metaspace)
Metaspace元空间主要是存储类的元数据信息,各种类描述信息,比如类名、属性、方法、访问限制等,按照一定的结构存储在Metaspace里。
一般来说,元空间大小是固定不变的。在出现溢出后,首先通过命令或监控工具(如下图)查看元空间大小,再检查是否-XX:MaxMetaspaceSize配置太小导致。
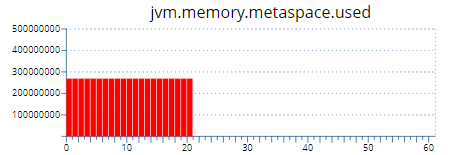

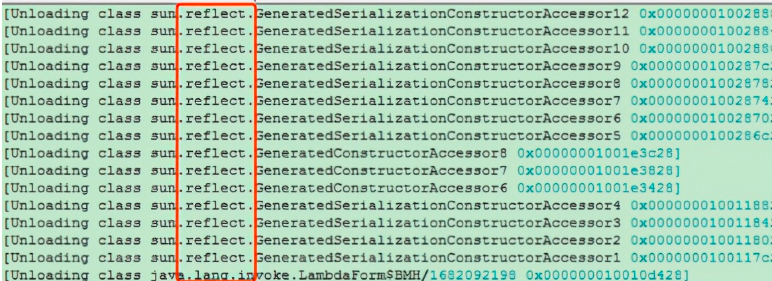
如果发现元空间大小是持续上涨的,则需要检查代码是否存在大量的反射类加载、动态代理生成的类加载等导致。可以通过-XX:+TraceClassLoading -XX:+TraceClassUnloading记录下类的加载和卸载情况,反推具体问题代码。
2、栈深度不够(java.lang.StackOverflowError)
引发StackOverFlowError的常见原因有:
- 无限循环递归调用
- 同一时间执行大量方法,资源耗尽
- 方法中声明大量局部变量
- 其它消耗栈资源的方法
- xss配置太小导致
/**
* VM Args: -Xss128k
*/
public class JavaStackSOF {
private int stackLength = 1;
public void stackLeak() {
stackLength++;
stackLeak();
}
public static void main(String[] args) {
JavaStackSOF oom = new JavaStackSOF();
try{
oom.stackLeak();
}catch(Throwable e) {
System.out.println("stack length:" + oom.stackLength);
throw e;
}
}
}
stack length:2101
Exception in thread "main" java.lang.StackOverflowError
at com.sandy.jvm.chapter02.JavaStackSOF.stackLeak(JavaStackSOF.java:13)
at com.sandy.jvm.chapter02.JavaStackSOF.stackLeak(JavaStackSOF.java:14)
at com.sandy.jvm.chapter02.JavaStackSOF.stackLeak(JavaStackSOF.java:14)
3、栈线程数不够(java.lang.OutOfMemoryError: unable to create new native thread)
这类错误目前在生成系统只遇到过一次,原因是:linux系统中非root用户默认创建线程数最多是1024。解决办法是修改文件:/etc/security/limits.d/90-nproc.conf
还有一种情况是-xss配置太大,那么操作系统可创建的最大线程数太小导致,一般除非误操作是不会出现此问题的。
4、堆溢出(java.lang.OutOfMemoryError: Java heap space)
堆溢出是常见也是最复杂的一种情况。导致堆溢出可能的情况有:
- 堆内存配置太小
- 超出预期的访问量:访问量飙升
- 超出预期的数据量:系统中是否存在一次性提取大量数据到内存的代码
- 内存泄漏
解决思路一般是:
一、堆dump文件获取
1、通过参数配置自动获取dump文件(推荐)
2、jmap -dump:format=b,file=filename.hprof pid
二、MAT工具分析
1、分析大对象、堆中存储信息、可能存在的内存泄漏地方,便于定位问题位置
五、JVM监控
常用的监控工具或命令有:jstack、jstat、jConsole、jvisualvm。监控指标主要是各内存区域大小是否合理、fullGC频率及耗时、youngGC耗时、线程数等。
1、jstack
jstack主要用于打印线程堆栈信息,帮助问题的定位。一般配合top -Hp PID使用。
通过top命令发现某个java服务占用1234%的CPU,如图:

通过top -Hp PID命令可以看到占用CPU比较高的线程,如图:

再次通过jstack PID>log.txt,输出堆栈信息即可进行排查定位。
2、jstat
jstat命令是分析JVM运行状况的常用命令。
jstat -options
-class 用于查看类加载情况的统计
-compiler 用于查看HotSpot中即时编译器编译情况的统计
-gc 用于查看JVM中堆的垃圾收集情况的统计
-gccapacity 用于查看新生代、老生代及持久代的存储容量情况
-gcmetacapacity 显示metaspace的大小
-gcnew 用于查看新生代垃圾收集的情况
-gcnewcapacity 用于查看新生代存储容量的情况
-gcold 用于查看老生代及持久代垃圾收集的情况
-gcoldcapacity 用于查看老生代的容量
-gcutil 显示垃圾收集信息
-gccause 显示垃圾回收的相关信息(通-gcutil),同时显示最后一次仅当前正在发生的垃圾收集的原因
-printcompilation 输出JIT编译的方法信息
以jstat -gcutil为例:
[root@hadoop ~]# jstat -gcutil 3346 #显示垃圾收集信息
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
52.97 0.00 42.10 13.92 97.39 98.02 8 0.020 0 0.000 0.020
- S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
- S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
- E:年轻代中Eden(伊甸园)已使用的占当前容量百分比
- O:old代已使用的占当前容量百分比
- M:元数据区已使用的占当前容量百分比
- CCS:压缩类空间已使用的占当前容量百分比
- YGC :从应用程序启动到采样时年轻代中gc次数
- YGCT :从应用程序启动到采样时年轻代中gc所用时间(s)
- FGC :从应用程序启动到采样时old代(全gc)gc次数
- FGCT :从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
3、jConsole
JConsole是基于JMX的可视化监视、管理工具。可以很方便的监视本地及远程服务器的java进程的内存使用情况。
3.1 被监控的程序运行时给虚拟机添加一些运行的参数
无需认证的远程监控配置
-Dcom.sun.management.jmxremote.port=60001 //监控的端口号
-Dcom.sun.management.jmxremote.authenticate=false //关闭认证
-Dcom.sun.management.jmxremote.ssl=false
-Djava.rmi.server.hostname=192.168.1.2
3.2 客户端连接被监控程序
找到 JDK 安装路径,打开bin文件夹,双击jconsole.exe,在已经打开的JConsole界面操作“连接->新建连接->选择远程进程->输入远程主机IP和端口号->点击“连接
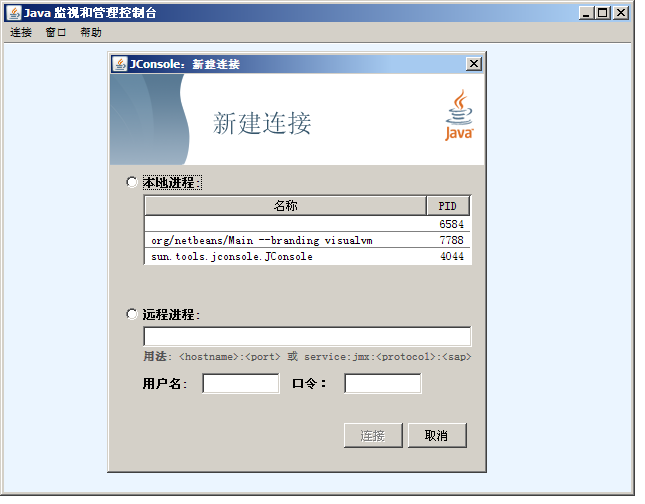
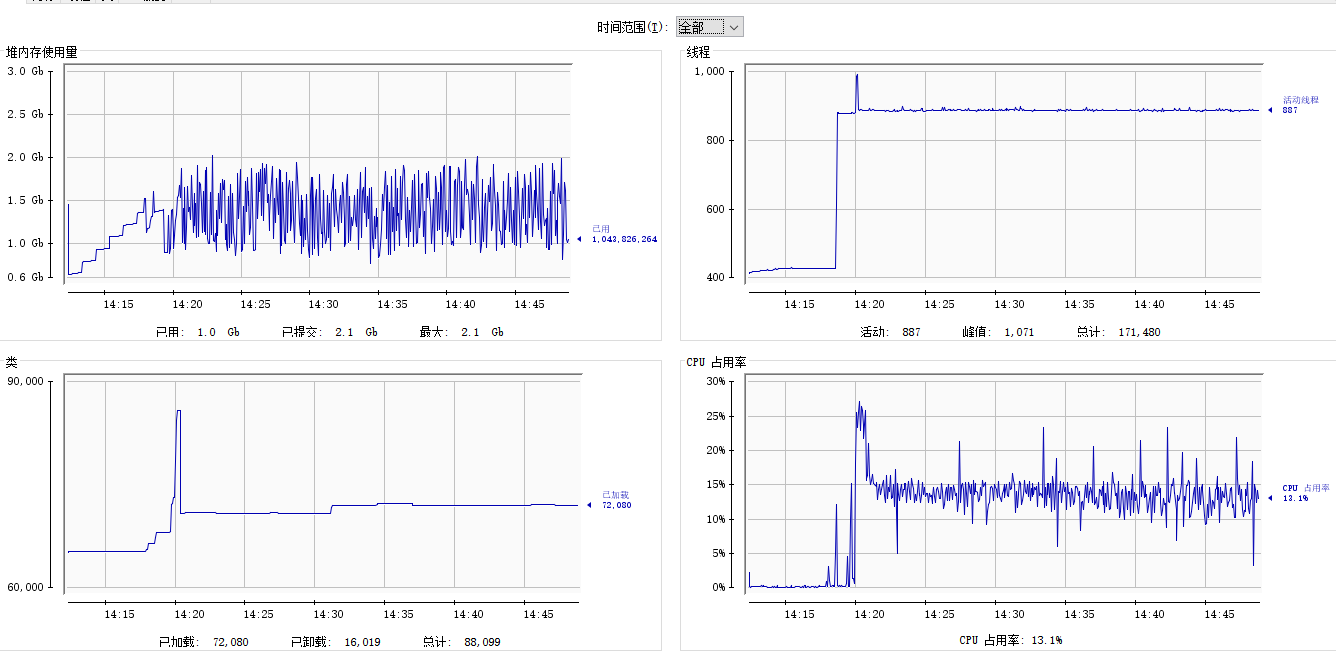
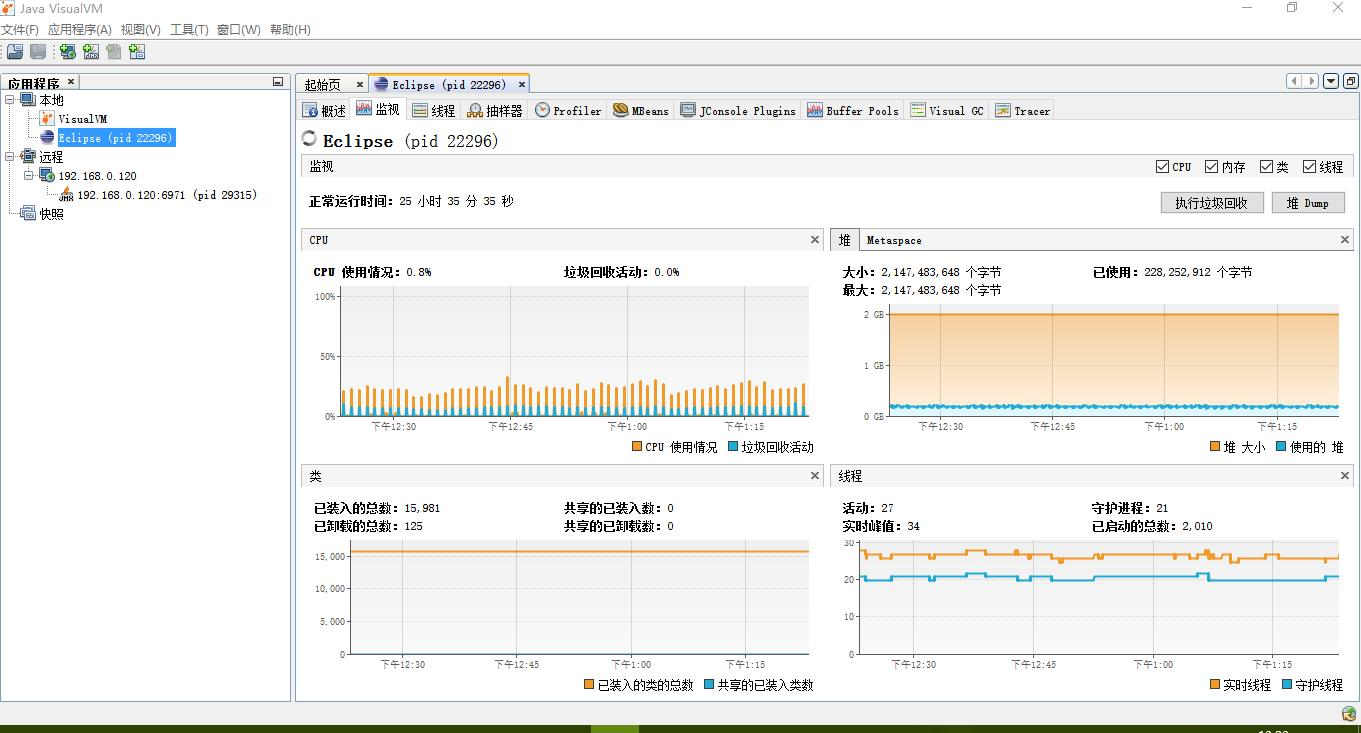
4、jvisualvm
jvisualvm与jConsole连接方式一致,连接后界面如下: