scrapy post payload的坑及相关知识的补充【POST传参方式的说明及scrapy和requests实现】
- 2020 年 3 月 3 日
- 笔记
一、问题及解决:
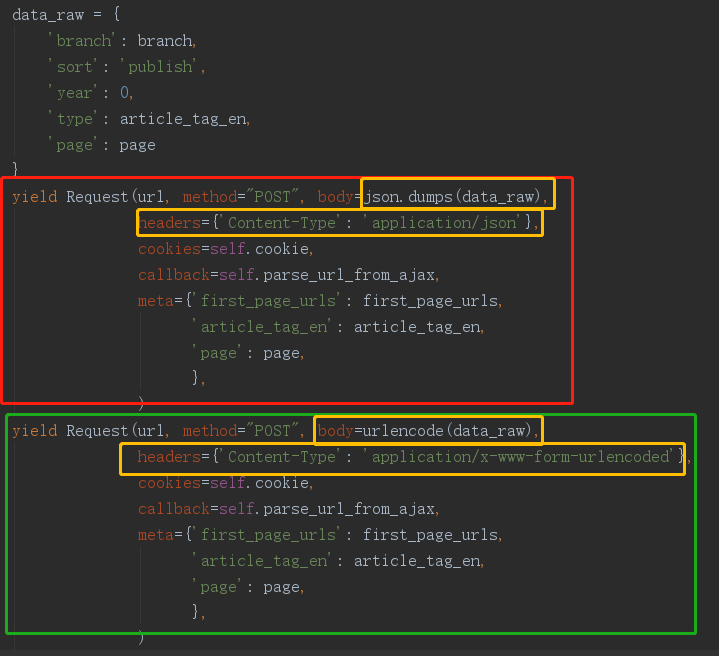
在用scrapy发送post请求时,把发送方式弄错了。
本来应该是 application/x-www-form-urlencoded 弄成了application/json。
但需要改两部分:body传入字典的构造方式和header的Content-Type内容
请求截图:
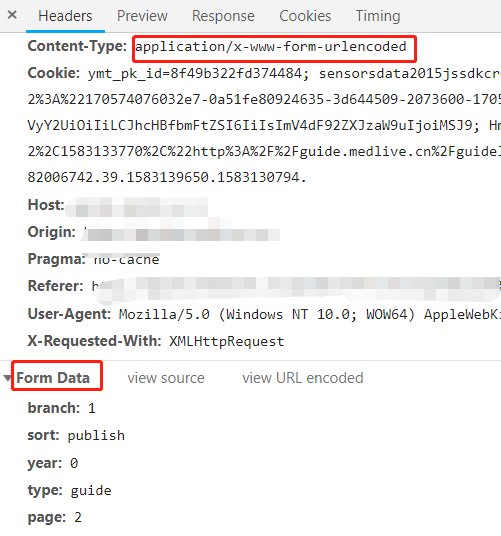
代码部分:(红色部分是原来错误的代码,绿色的是修改正确的,黄色是修改的地方)
二、POST传参方式的说明及scrapy和requests实现:
1、application/x-www-form-urlencoded
如果不设置Content-type,默认为该方式,提交的数据按照 key1=val1&key2=val2 的方式进行编码。
- requests :
# -*- encoding:UTF-8 -*- import requests import sys # 根据python版本,引入包 if sys.version_info[0] > 2: from urllib.parse import urlencode else: from urllib import urlencode url = "http://xxxx.com" payload_dict = {'aaa': '111'} data = urlencode(payload_dict) headers = {'Content-Type': "application/x-www-form-urlencoded"} response = requests.request("POST", url, data=payload_dict, headers=headers) print(response.text)
- scrapy:
#!/usr/bin/env python # -*- coding: utf-8 -*- import sysif sys.version_info[0] > 2: from urllib.parse import urlencode else: from urllib import urlencode payload_dict = {'page': 1} # 使用普通request方法,需要将数据的字典进行url编码,传入body yield scrapy.Request(url=url, method='POST', body=urlencode(payload_dict), headers={'Content-Type': 'application/x-www-form-urlencoded'}, callback=self.parse, dont_filter=True) # 使用scrapy自带的post请求方法,将字典直接传入formdata,默认会对其进行编码 yield scrapy.FormRequest(url=i, method='POST', formdata=payload_dict, headers={'Content-Type': 'application/x-www-form-urlencoded'}, callback=self.parse)
2、application/json:
请求所需参数以json的数据格式写入body中,后台也以json格式进行解析。
- requests
# -*- encoding:UTF-8 -*- import requests import json url = "https://xxxx.com" # 需要发送的参数 payload = {'page': 1, 'branch': 'guide'} headers = {'Content-Type': "application/json"} # 将参数转为json格式传入 response = requests.request("POST", url, data=json.dumps(payload_dict), headers=headers) print(response.json())
- scrapy
# -*- coding: utf-8 -*- import json import scrapy data_raw = { "query": "coronavirus ", "queryExpression": "", "filters": [ "Y>=1978", "Y<=1978" ], "orderBy": 0, "skip": 0, "sortAscending": 'true', "take": 10, "includeCitationContexts": 'true', "profileId": "" } url = 'https://academic.microsoft.com/api/search' # body传入json格式参数 yield Request(url, method="POST", body=json.dumps(data_raw), headers={'Content-Type': 'application/json'}, callback=self.parse)
3、multipart/form-data:用于上传表单位文件。
4、text/xml:现在基本不用( 因为XML 结构过于臃肿,一般场景用 JSON 会更灵活方便)。


