【机器学习基础】集成学习回顾及总结
之前有将集成学习中的随机森林、GBDT、XGBoost等算法进行一一介绍,明白了每个算法的大概原理,最近复习了一下李宏毅老师的集成学习的课程,忽然对集成有了更清晰的认识,这里做一个回顾和总结。
集成学习回顾及总结
集成学习从直观的意思来说,就是合众人之力来解决一个问题,而每个人所起的作用又不相同,最终把大家的力量进行“集成”,从而得到更优的方案。
在前面线性回归的误差分析中说到,误差来源于偏差bias和方差variance,而简单的模型通常具有较大的偏差,从而出现欠拟合,复杂的模型具有较大的方差,出现过拟合的情况。
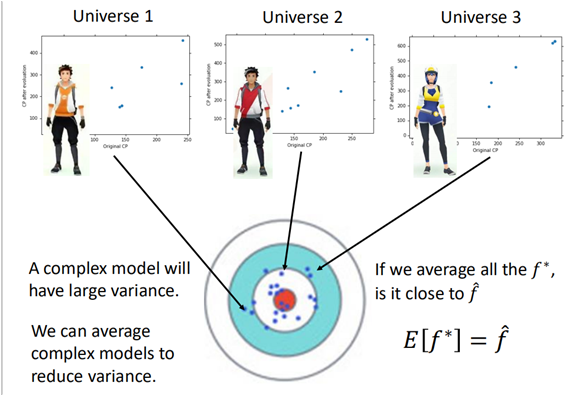
在线性回归中,当我们训练一系列的模型的时候(在平行宇宙中,训练出来n多个模型),当采用较为简单的模型的时候,最终形成的是偏差大方差小的结果:

而当模型采用比较复杂的时候,训练的结果是这样的:

而集成学习就根据消除偏差和方差,出现了两个系列的方法bagging和boosting。
1.Bagging
当使用复杂的模型训练出多个模型的时候,出现方差很大的情况,通过将模型进行“平均”,从而降低模型的方差。
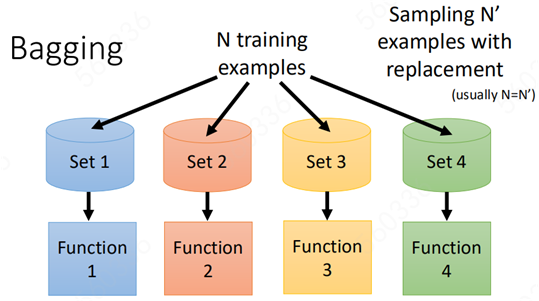
而Bagging就是为了解决方差过大的问题而提出的一种方法,即“集合”多个模型来共同决定结果。
那么Bagging中的多个模型又是从何而来呢?
这就是Bagging的主要思想:将一整个数据集拆分出多个数据集,然后根据数据集的不同来训练出来多个模型。
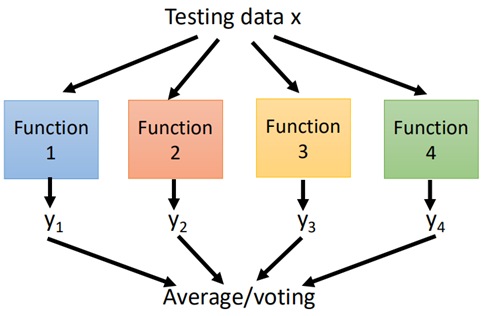
然后根据所训练得到的模型,测试集分别丢进每个模型中,然后通过投票的方式(不局限)得到最终的结果。
上面说到,Bagging能够很好地将多个复杂模型的方差进行平均后,从而得到一个方差较小的模型。也就是说Bagging能够有效的处理方差较大的问题。
再换句话说就是Bagging方法中所选用的模型越复杂越好,也就是强分类器。
Bagging中一个最著名的算法就是随机森林(Random Forest),所谓随机森林就是选用了决策树作为基分类器的Bagging方法。
之所以选用决策树,是因为决策树具有很强的分类能力,甚至每一个样本都可以有一个叶子节点,很容易做到在训练集的误差为0。因此也很容易过拟合。
而随机森林另一个特点是不单单在训练每一颗树时所采用的样本是随机采样的,在每个节点进行分裂时的特征也是随机抽取的,从随机抽取的那一部分特征中再选出最优的特征进行分裂。
之所以这样做是因为如果单单对于训练集进行重采样的话,这样得到的树都相差不大,从而在最终决策时差别可能不会太大。
对于Bagging方法的测试,通常采用OOB(Out of Bag)的方法来进行测试,所谓OOB方法,假设一个数据集只有4笔数据,那么利用Bagging方法训练时:
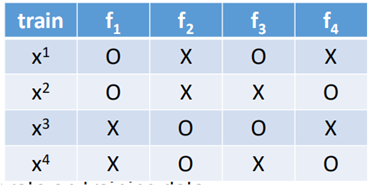
f1使用了x1、x2进行训练得到,f2使用了x3、x4训练得到,f3使用x1、x3训练得到,f4使用x2、x4训练得到,那么在测试时,
使用f2+f4来测试x1,f2+f3来测试x2,f1+f4来测试x3,f1+f3来测试x4。
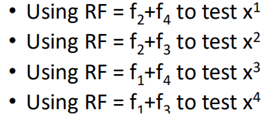
因为对于每一个模型的组合而言,这一个数据对这个组个是从来没有见过的,能够较好的估计出测试误差。
2.Boosting
另一个集成的方法就是Boosting,在前面说过Bagging是为了解决variance的问题,而Boosting就是解决bias的问题,Boosting是为了提升比较弱的分类器而提出的方法。因此Boosting的意思是“提升”。
因此对于Boosting而言,当模型的分类器越弱,所能够得到的提升就越大,因此Boosting通常选择弱分类器作为基分类器。
假设有一个基分类器的分类正确率仅仅比50%(也就是随机乱猜)高一点点,利用Boosting方法最终可以将分类准确率提升至100%。这个稍后会给予证明。
而Boosting也是通过集合多个模型来达到提升的目的,那么多个模型从何而来呢?
Boosting的思想就是:
(1)首先获得一个初始的模型f1(x);
(2)寻找另外一个函数f2(x)来帮助f1(x)进行决策,然而如果f2(x)和f1(x)差不多,那么可能不会有太大的帮助;
(3)继续寻找f3(x),同样提升f2(x).
那么通过相同的数据集,如何获得不同的f1、f2…呢?在Bagging方法里通过重采样的方法使得数据集不同从而得到的模型不同。
2.1 AdaBoost算法原理
AdaBoost是一种比较著名的Boosting的方法,在AdaBoost方法中,则是通过改变样本的权重,使得样本变得“不相同”,从而得到不同的模型。
因此数据集从原先的{(x1,y1),(x2,y2),……}变成了{(x1,y1,u1),(x2,y2,u2),…..},随着每次的训练和迭代,ui(表示第i个样本的权重)会发生改变。
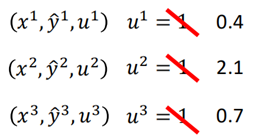
而一旦样本的权重发生改变,也就意味着在每一次迭代训练时,损失函数的改变:
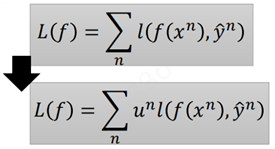
换句话说,就是通过改变样本的权重来训练得到f2(x),而新的权重样本会使得f1(x)“失效”。
那么如何改变样本的权重构造出新的数据集使得f1错误率提升呢?
假设ε1表示样本在f1(x)上的错误率,那么:
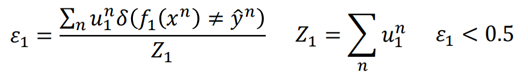
ε1这里是小于0.5的,如果大于0.5就把结果反过来就好了。
然后将样本的权重u1改变为u2,那么:
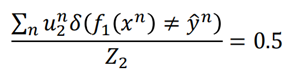
改变权重后的样本,带进f1中,则f1的错误率则变成了0.5。

假设u1的权重初始都是1,训练得到f1后,ε1=0.25,此时改变样本的权重,改变的规则就是提高错误分类样本的权重,同时降低正确分类样本的权重。
也就是说对于分类错误的样本,都乘上一个权重因子d,而对于分类正确的样本都除以权重因子d,d>1。
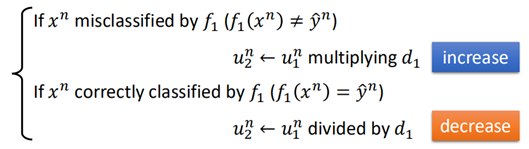
那么这个d是怎样的呢?根据错误率的计算公式来进一步推导:
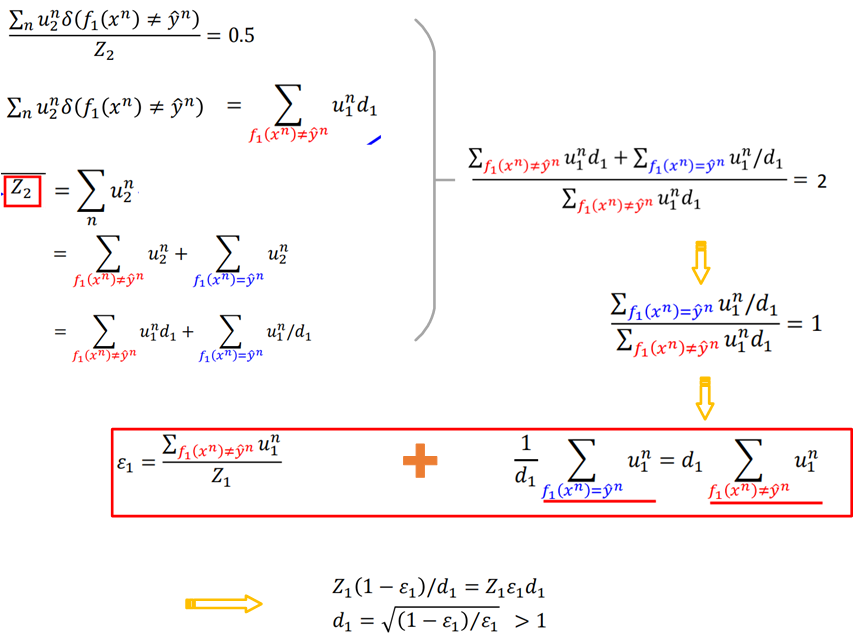
从而得到d,这里对于所有错误的样本提高的权重比例都是一样的,同样正确的样本降低权重的比例也是一样的。
然后用这些修改过权重的样本再次训练得到f2,依次往复….
那么总的AdaBoost的算法如下:
“””
给定样本{(x1,x2,u1),(x2,y2,u2),……(xn,yn,un)},初始化u1,u2,…un=1。y=±1。
对于t=1~T个迭代过程:
训练一个模型ft(x),该模型的错误率为εt,εt是考虑ut(i)的,计算如下:
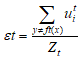
对于样本1~n:
对于分类正确的样本i,其权重变为ut(i)/dt,对于分类错误的样本,其权重变为ut(u)*dt,
得到新的样本{(x1,y1,ut+1(1)),(x2,y2,ut+1(2)),……},重复该过程。
“”””

这里为了便于统一描述,对dt进行一个变形:
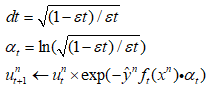
这样我们就通过上面的方法获得了n个分类器,接下来就要将他们aggregate起来,如何集成到一起呢?通常有两种做法:
第一就是uniform的继承方式,即直接进行相加投票:

另一种就是考虑权重的集成方式:
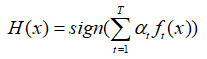
这种考虑权重的集成跟每个分类器的错误率有关,对于错误率高的分类器,α就小,在集成时的“话语权”就小,相反,错误率低的分类器在集成时的“话语权”就高。
下面举一个有关AdaBoost的例子:
初始有10个样本点,初始样本权重均为1,然后构造一个分类器,这里分类器选择决策树桩作为基分类器,决策树桩是一个比较弱分类器。

经过第一轮训练得到一个分类器f1,左边蓝色区域的为正类,右边红色区域为负类。
根据第一轮训练结果可知,有三个样本被错误分类(红色圆圈),根据错误率调整各个样本的权重,如右图所示。
接下来根据这些被调整后的样本再次训练一个分类器f2,:
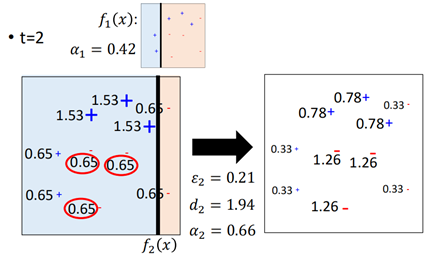
f2认为左边区域为正类,右边区域的负类,那么经f2分类的样本有三个被错误分类(红色圈住的样本),再次计算错误率,然后调整样本权重。
然后继续按照调整后的样本来训练f3:

得到的f3认为上半部分为正类,下半部分为负类,此时计算得到错误率为0.13。
假设设定经过3轮迭代停止,那么接下来将三个基分类器进行集成:
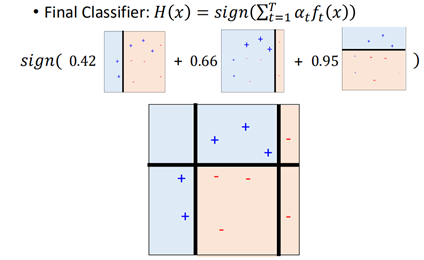
比如对于左边两个样本,f1、f2认为其为正类,f3认为其为负类,但由于权重0.42+0.66>0.95,因此左边两个样本为正类。
2.2 关于AdaBoost收敛证明
前面说到很多个基分类器通过集成的方式,使得即使很弱的分类器,最终随着基分类器数量的增多也会使得在训练集上的准确率趋近于1。
在前面是根据霍夫丁不等式给出了随着基分类器数量的增多,错误率不断下降。这里以AdaBoost为例,来进行证明。
AdaBoost最终所集成的分类器为H(x),

那么其最终的分类错误率表示为:

绿色的线是在SVM那一节中说到的ideal loss,而exp(·)则是ideal loss的一个upper bound。因此接下来我们能够证明这个upper bound随着基分类器数量T的增大会收敛即可。
而实际上:
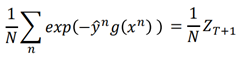
下面首先证明ZT+1和exp(·)相等这一件事。
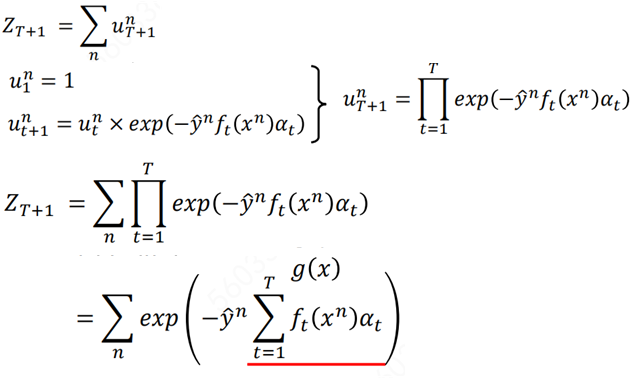
由此得出ZT+1和exp(·)相等。

Zt等于第t个基分类器分类后的错误分类的权重和加上正确分类的权重和,那么根据上面的Zt和Zt-1的关系,可以得到:

于是有:
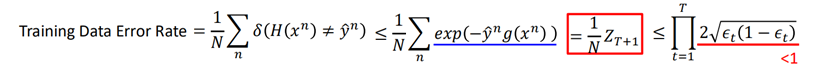
因此,随着T的增大,训练集上的误差会越来越小。
2.3 Boosting的一般算法流程
总结下来,Boosting算法的一般流程如下:

Boosting的求解每一轮过程ft(x)就是通过minimizeL来进行求解,对于不同的算法,所使用的损失函数不同。而AdaBoost则是使用的指数损失函数exp(·)。
而GBDT中对于分类问题使用的对数损失,回归问题常使用均方误差损失函数等。
下面来简单证明一下为什么Boosting中算是函数是指数损失时就变成了AdaBoost了。
在Gradient Boosting中,通过minimizeL(g)来更新g(x):

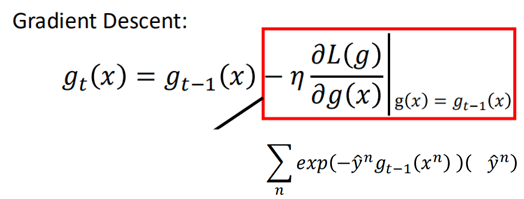
而在AdaBoost中:

那么红色框中的两项应该具有相同的方向:
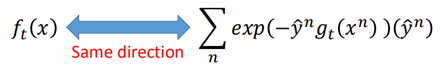
两个同向,则希望二者做内积时的值越大越好:
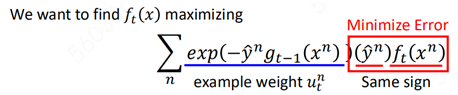
要想使二者最大,y和ft则必须同号,也就是要尽可能ft保证样本正确分类。
而前一项exp刚好是样本的权重:
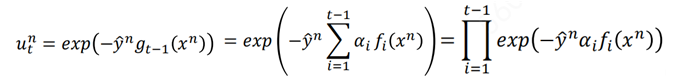
到这里可以看出,要找的ft(x)刚好就是AdaBoost中的那个ft(x)。
而对于α,其类似与learning rate:
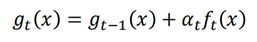
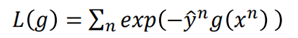
我们希望找到一个α,使得L最小化:
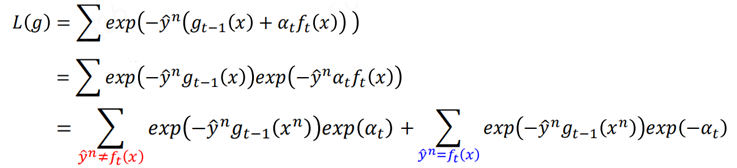
然后求导令其为0,求得α:

可以看出当使用梯度提升时,采用指数损失时,就变成了AdaBoost了。
3.总结
上面主要对Bagging和Boosting进行了介绍和回顾,最主要AdaBoost在前面内容并不多,这里做一个补充。总结一下Bagging和Boosting模型:
1、Bagging主要是为了降低模型的Variance,突出了“平均”的概念,而Boosting是为了降低模型的bias,提升弱分类器的能力;
2、正因为Bagging是降低Variance,因此Bagging通常采用较强的分类器作为基分类器;而Boosting是一步步提升分类器的能力,因此通常采用弱分类器作为基分类器;
3、因为Bagging突出的“平均”的能力,因此Bagging是并行训练的,各个分类器互不影响,而Boosting一步一步提升,因此Boosting通常只能串行训练;


