深入理解Kafka核心设计及原理(四):主题管理
转载请注明出处://www.cnblogs.com/zjdxr-up/p/16124354.html
目录:
4.1创建主题
4.1创建主题
如果 broker 端配置参数 auto .create.topics .enable 设置为 true (默认值就是 true) ,那么当生产者向一个尚未创建的主题发送消息时,会自动创建一个分区数为 num . partitions(默认值为1 )、副本因子为 default.repl 工 cation.factor (默认值为1 )的主题。除此之外,当一个消费者开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会按照配置参数 num.partitions 和 default.replicatio口 .factor 的值来创建一个相应的主题。很多时候,这种自动创建主题的行为都是非预期的。除非有特殊应用需求,否则不建议将 auto.create.topics. enable 参数设置为 true,这个参数会增加主题的管理与维护的难度。
通过命令创建主题
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --create --topic topic-create --partitions 4 --replication-factor 2
创建了一个分区数为 4 、 副本因子为 2 的主题;在执行完脚本之后,Kafka 会在 log.dir 或 log.dirs 参数所配置的目录下创建相应的主题分区,默认情况下这个目录为/tmp/kafka-logs/
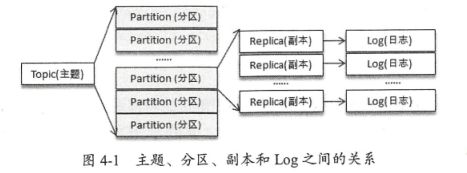
生产者的分区分配是指为每条消息指定其所要发往的分区,消费者中的分区分配是指为消费者指定其可以消费消息的分区
#查看指定主题
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic topic-create-zk
#查看当前所有可用主题
bin/kafka-topics.sh --zookeeper localhost:2181/kafka -list
#删除主题
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --delete --topic topic-delete
#增加主题分区
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic topic-config --partitions 3
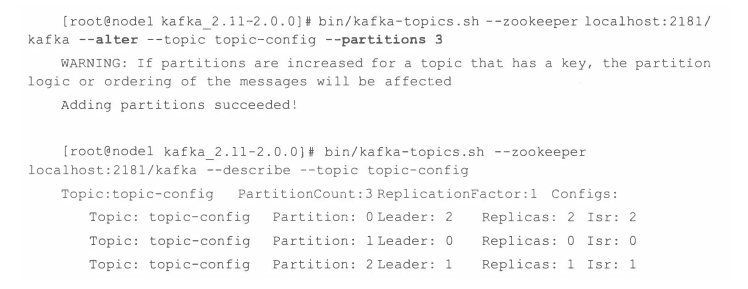
4.2 优先副本的选举
随着时间的更替, Kafka集群的broker节点不可避免地会遇到宕机或崩溃的问题, 当 分区的leader节点发生故障时, 其中 一个follower节点就会成为新的leader节点, 这样就会导致集群的负载不均衡, 从而影响整体的健壮性和稳定性。
为了能够有效地治理负载失衡的情况,Kafka引入了优先副本(preferred replica)的概念。所谓的优先副本 是指在 AR 集合列表中的第 一个副本 。 比如上面 主题 topic-partitions中 分区 0的AR集合列表(Replicas)为[1,2,0], 那么分区0 的优先副本即为1。 理想情况下,优先副本就是该分区的leader副本, 所以也可以称之为 preferred leader。Kafka要确保所有主题的优先副本在Kafka集群中均匀分布, 这样就保证了所有分区的leader均衡 分布。 如果leader 分布过于集中, 就会造成集群 负载不均衡。 所谓的优先副本的选举 是指通过一定的方式促使优先副本 选举为 leader副本, 以此来促进集群的负载均衡, 这 一行为也可以称为“ 分区平衡” 。
在Kafka中可以提供分区自动平衡的功能, 与此对应的broker端参数是auto.leader.rebalance.enable,此参数的默认值为true, 即默认情况下此 功能是开启的。如果开启分区自动平衡的功能,则Kafka的控制器会启动一个定时任务, 这个定时任务会轮询所有的broker节点, 计算每个broker节点的分区不平衡率(broker中的不平衡率=非优先副本的leader个数/分区总数)是否超过leader.imbalance.per.broker.percentage参数配置的比值,默认值为10%,如果超过设定的比值则会自动执行优先副本的选举动作以求分区平衡。执行周期由参数leader.imbalance.check.interval.seconds控制,默认值为300秒,即5分钟。
不过在生产环境中不建议将auto.leader.rebalance.enable 设置为默认的true,因为这 可能引起负面的性能问题, 也有可能引起客户端 一 定时间的阻塞。 因为执行的时间无法自主掌控,如果在关键时期(比如电商大促波峰期)执行关键任务的关卡上执行优先副本的自动选举操作, 势必会有业务阻塞、 频繁超时之类的风险。 前面也分析过, 分区及副本的均衡也不能完全确保集群整体的均衡,并且集群中一 定程度上的不均衡也是可以忍受的, 为防止出现关键时期“ 掉链子”的行为.
Kafka中kafka-perferred-replica-election.sh脚本提供了对分区leader副本进行重新平衡的功能。
bin/kafka-preferred-replica-election. sh --zookeeper localhost:2181/kafka
4.3 分区重分配
当要对集群中的一个节点进行有计划的下线操作时, 为了保证分区及副本的合理分配, 我们也希望通过某种方式能够将该节点上的分区副本迁移到其他的可用节点上。当集群中新增broker节点时, 只有新创建的主题分区才有可能被分配到这个节点上, 而之前的主题分区并不会自动分配到新加入的节点中, 因为在它们被创建时还没有这个新节点, 这样新节点的负载和原先节点的负载之间严重不均衡。 为了解决上述问题,需要让分区副本再次进行合理的分配,也就是所谓的分区重分配。Kafka提供了kafka-reassign-partitions.sh脚本来执行分区重分配的工作, 它可以在集群扩容、broker节点失效的场景下对分区进行迁移。
kafka-reassign-partitions.sh脚本的使用分为3 个步骤:首先创建需要 一 个包含主题清单的JSON文件, 其次根据主题清单和broker节点清单生成 一 份重分配方案,最后根据这份方案执行具体的重分配动作。
分区重分配的基本原理是先通过控制器为每个分区添加新副本(增加副本因子 ) ,新的副本将从分区的leader副本那里复制所有的数据。 根据分区的大小不同, 复制过程可能需要花一些时间, 因为数据是通过网络复制到新副本上的。在复制完成之后, 控制器将旧副本从副本清单里移除(恢复为原先的副本因子数)。 注意在重分配的过程中要确保有足够的空间。
分区重分配本质在于数据复制,先增加新的副本,然后进行数据同步,最后删除旧的副本来达到最终的目的。 数据复制会占用额外的资源, 如果重分配的量太大必然会严重影响整体的性能, 尤其是处于业务高峰期的时候。 减小重分配的粒度, 以小批次的方式来操作是一种可行的解决思路。
如果集群中某个主题或某个分区的流量在某段时间内特别大, 那么只靠减小粒度是不足以应对的, 这时就需要有一个限流的机制, 可以对副本间的复制流量加以限制来保证重分配期间整体服务不会受太大的影响 。副本间的复制限流有两种实现方式:kafka- config.sh脚本和kafka-reassign- partitions.sh脚本 。
4.4 如何选择合适的分区
在 Kafka 中 ,性能与分区数有着必然的关系,在设定分区数时一般也需要考虑性能的因素。对不同的硬件而言,其对应的性能也会不太一样。
在实际生产环境中,我们需要了解一套硬件所对应的性能指标之后才能分配其合适的应用和负荷,所以性能测试工具必不可少。Kafka 本身提供的用于生产者性能测试的kafka-producer-perftest.sh 和用于消费者性能测试的 kafka-consumer-perf-test. sh 。
向一个只有1个分区和1个副本的主题 topic-1 中发送 100 万条消息,并且每条消息大小为 1024B ,生产者对应的 acks 参数为 l;
bin/kafka-producer-perf-test.sh --topic topic-1 --num-records 1000000 --record-size 1024 --throughput 一1 --producer-props bootstrap.servers=localhost:9092 acks=l
简单地消费主题topic-I中的100万条消息
bin/kafka-consumer-perf-test. sh --topic topic-1 --messages 1000000 --broker-list localhost:9092
4.5分区数越多吞吐量也越高?
针对分区数越多吞吐量越高这个命题进行反证, 其实要证明一个观点是错误的, 只需要举个反例即可, 本节的内容亦是如此 。不过本节并没有指明分区数越多吞吐量就越低这个观点, 并且具体吞吐量的数值和走势还会和磁盘、 文件系统、1/0调度策略相关。分区数越多吞吐量 也就越高?网络上很多资料都认可这 一观点 , 但实际上很多事情都会有一个临界值, 当超过这个临界值之后, 很多原本符合既定逻辑的走向又会变得不同。读者需要对此有清晰的认知,懂得去伪求真, 实地测试验证不失为一座通向真知的桥梁。
一味地增加分区数并不能使吞吐量 一直得到提升, 并且分区数也并不能一直增加, 如果超过默认的配置值, 还会引起 Kafka进程的崩溃。
当然分区数也不能一味地增加, 分区数会占用文件描述符(即一个文件下可建立的子文件数量默认为1024,超过默认值则会报 open too many files), 而一个进程所能支配的文件描述符是有限的, 这也是通常所说的文件句柄的开销。 虽然我们可以通过修改配置来增加可用文件描述符的个数, 但凡事总有一个上限, 在选择合适的分区数之前, 最好再考量一下当前Kaf ka进程中已经使用的文件描述符的个数。


