SparkStreaming推测机制:面试被问遇到什么问题,说这个显水平!

背景
老刘最近晚上会刷刷牛客网的大数据开发面经,总是会看到一个高频的面试题,那就是你在学习过程中遇到过什么问题吗?
这个问题其实有点难回答,如果我说的太简单了,会不会让面试官觉得水平太低,那我应该讲什么东西呢?我一个自学的不可能遇到什么高级问题呀!
对于这个问题的答案网上也是众说纷纭,老刘也讲讲对这个问题的看法,分享一下自己的见解,欢迎各位伙伴前来battle!

过程
在寻找这个问题答案的过程中,老刘正好在学习spark框架的实时计算模块SparkStreaming,它里面就有一个非常经典的问题,关于推测机制的!
什么是推测机制?
如果有很多个task都在运行,很多task一下就完成了自己的任务,但是有一个task运行的很慢。在实时计算任务中,如果对实时性要求比较高,就算是两三秒也要在乎这些。
所以在sparkstreaming中有一个推测机制专门来解决这个运行的很慢的task。
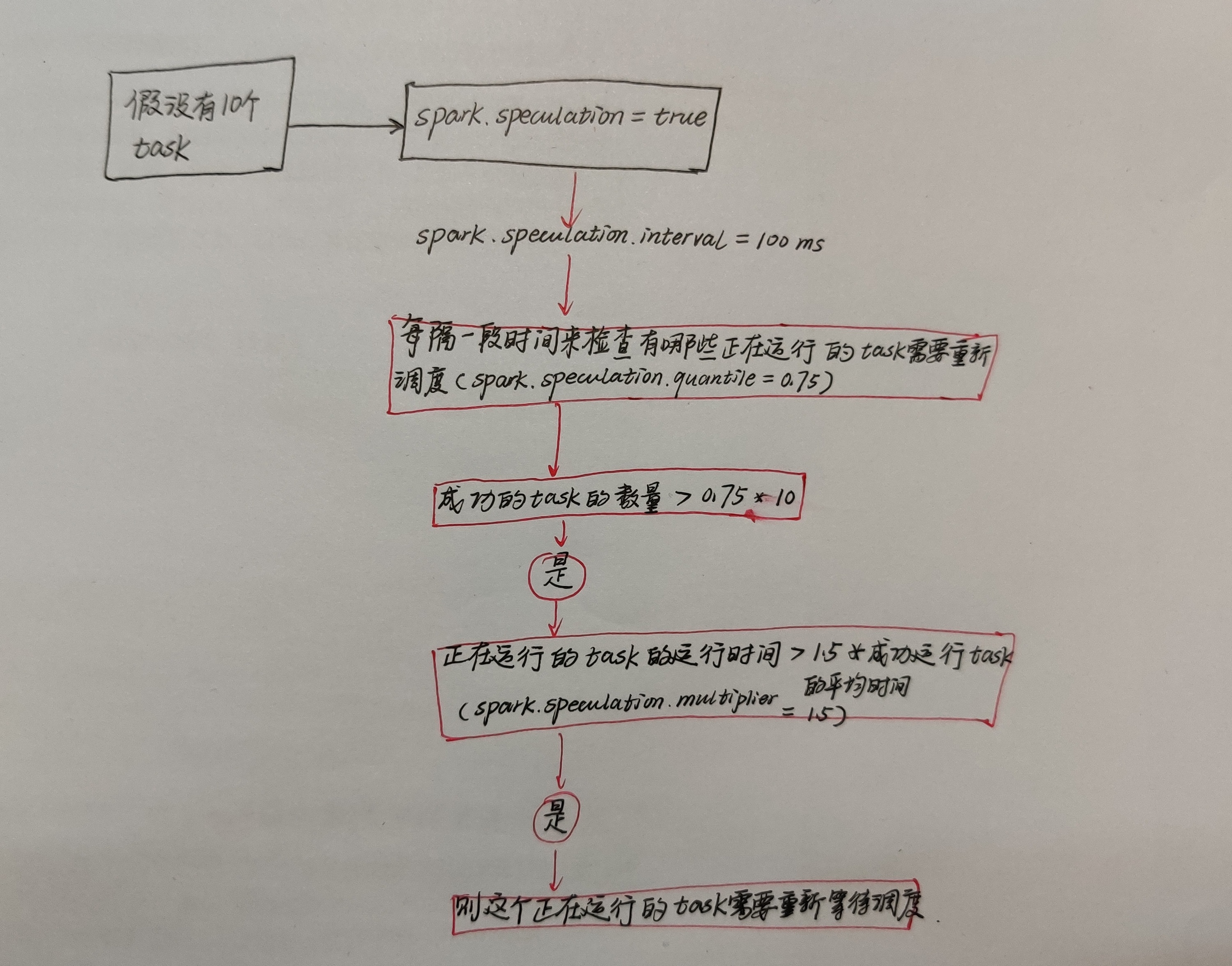
每隔一段时间来检查有哪些正在运行的task需要重新调度,假设总的task有10个,成功运行的task数量>0.75×10,正在运行的task的运行时间>1.5x成功运行task的平均时间,则这个正在运行的task需要重新等待调度。
但是这里有一个很严重的问题,最开始自学的时候发现了,接着在看一些机构视频里面也有讲到这个问题,说明老刘在自学过程中觉悟也在慢慢提高。

这个问题就是如果这个正在运行的task遇到数据倾斜怎么办?
假如有5个task,有一个task遇到了数据倾斜,但就算遇到数据倾斜(稍微有点数据倾斜,也没事),它也会完成任务,它需要6s,其他4个任务只需要1s。那开启推测机制后,这个任务好不容易运行到了2s,快要成功了,但遇到了推测机制,它就需要重新调度重新运行,下一次运行了3s,遇到推测机制就会重新运行,整个过程一直在循环,这就是老刘要说的问题!
某个培训机构视频里面的老师说这个问题还行,老刘自己也想到了看出了推测机制的这个缺点,所以就分享给大家!
解决
那开启推测机制遇到数据倾斜,怎么办?
我们可以采用一些解决数据倾斜的办法,老刘大致讲一下关于数据倾斜的几个解决方案:
1、如果发现导致数据倾斜的key就几个,而且对计算本身的影响并不大的话,就可以采用过滤少数导致倾斜的key
2、两阶段聚合,将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。但是这个方法只适用于聚合类的shuffle操作,不适合join类的shuffle操作。
3、对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。适用于两个数据量比较大的表进行join。
4、如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义,此时就只能使用这一种方案来解决问题了。将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。

好啦,SparkStreaming推测机制讲完了,大家以后可以拿这块的内容回答面试官。如果有什么问题,可以联系公众号:努力的老刘,欢迎大家来和老刘battle!


