图
图(Graph)和树比起来,是一种更为复杂的非线性表结构
一 顶点&边
在树中的元素称为节点,而在图中的元素叫作顶点(vertex)。
图中一个顶点可以与任意其他顶点建立连接关系,这种建立的关系叫边(edge)。

跟顶点相连接的边的条数, 叫作顶点的度(degree)。
二、有向图&无向图
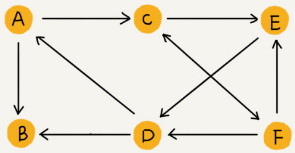
这种边有方向的图叫作“有向图”。边没有方向的图就叫作“无向图”。
在有向图中度分为入度(In-degree)和出度(Out-degree)。
-
顶点的入度,表示有多少条边指向这个顶点
-
顶点的出度,表示有多少条边是以这个顶点为起点指向其他顶点。
对应到微博的例子,入度就表示有多少粉丝,出度就表示关注了多少人。
三、带权图
在带权图(weighted graph)中,每条边都有一个权重(weight),可以通过这个权重来表示 QQ 好友间的亲密度。
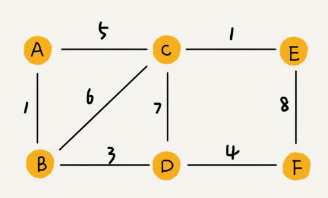
一、邻接表存储方法
邻接表的每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。
无向图可以看作每条边都是双方向的有向图。

邻接矩阵存储起来比较浪费空间,但是使用起来比较节省时间。相反,邻接表存储起来比较节省空间,但是使用起来就比较耗时间。这是时间、空间复杂度互换的设计思想,前者是空间换时间,后者是时间换空间。
上图邻接表的例子中,如果要确定是否存在一条从顶点 2 到顶点 4 的边,就要遍历顶点 2 对应的那条链表,看链表中是否存在顶点 4。当然如果链过长,可以将链表换成红黑树、散列表等来提高查找效率,还可以将链表改成有序动态数组,通过二分查找的方法来快速定位两个顶点之间否存在边。
二、如何存储微博、微信等社交网络中的好友关系?
基本实现思想
用两个邻接表来存储
- 一个邻接表存储某个用户关注了哪些用户,即用户的关注关系
- 另一个邻接表称为逆邻接表存储某个用户被哪些用户关注,即用户的粉丝列表
如果要查找某个用户关注了哪些用户,在邻接表中查找即可;如果要查找某个用户被哪些用户关注了,从逆邻接表中查找即可。

较大数据量实现方案
如果对于小规模的数据,可以将整个社交关系存储在内存中。
如果对于大规模的数据,可以通过哈希算法等数据分片方式,将邻接表存储在不同的机器上。
例如:
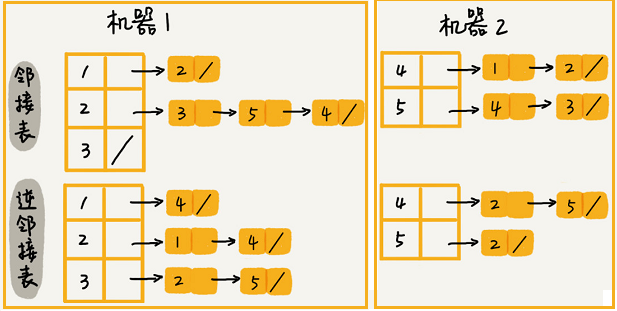
当要查询顶点与顶点关系的时候,就利用同样的哈希算法,先定位顶点所在的机器再在相应的机器上查找。
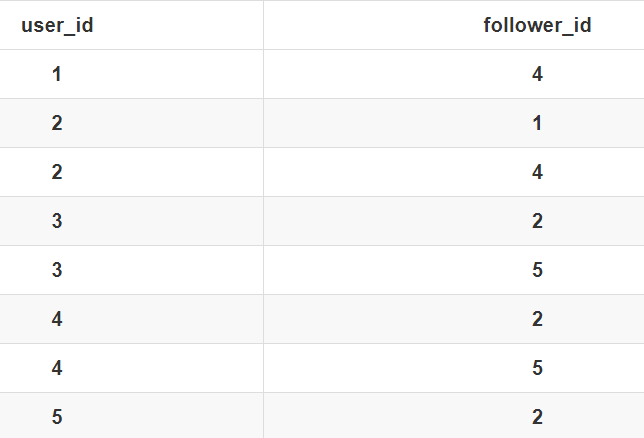
另外一种解决思路,就是利用外部存储(比如硬盘),数据库是经常用来持久化存储关系数据的
用下面这张表来存储这样一个图。为了高效地支持前面定义的操作,可以在表上建立这两列都建立索引。
BFS&DFS
图的遍历:依次把图中所有的顶点都访问一次。
图上的搜索算法有
- 深度优先搜索算法
- 广度优先搜索算法
广度优先搜索和深度优先搜索是图上的两种最常用、最基本的搜索算法,仅适用于状态空间不大的搜索。
广度优先搜索,采用地毯式层层推进,从起始顶点开始,依次往外遍历。广度优先搜索需要借助队列来实现,遍历得到的路径就是起始顶点到终止顶点的最短路径。
深度优先搜索,采用回溯思想,适合用递归或栈来实现。遍历得到的路径并不是最短路径。
一、深度优先搜索(DFS)
深度优先搜索(Depth-First-Search),简称 DFS。
最直观的例子就是“走迷宫”。假设你站在迷宫的某个岔路口,然后想找到出口。你随意选择一个岔路口来走,走着走着发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。这种走法就是一种深度优先搜索策略。
下图中,搜索的起始顶点是 s,终止顶点是 t,希望在图中寻找一条从顶点 s 到顶点 t 的路径。如果映射到迷宫那个例子,s 就是你起始所在的位置,t 就是出口。
下图标记了递归算法的搜索的过程,里面实线箭头表示遍历,虚线箭头表示回退。但深度优先搜索最先找出来的路径,并不是顶点 s 到顶点 t 的最短路径。
深度优先搜索的过程类似于树的先序遍历,首先从例子中体会深度优先搜索。
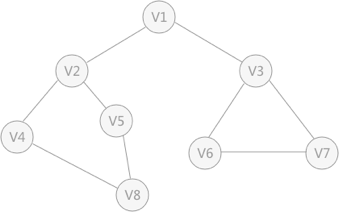
例如图 1 是一个无向图,采用深度优先算法遍历这个图的过程为:
- 首先任意找一个未被遍历过的顶点,例如从 V1 开始,由于 V1 率先访问过了,所以,需要标记 V1 的状态为访问过;
- 然后遍历 V1 的邻接点,例如访问 V2 ,并做标记,然后访问 V2 的邻接点,例如 V4 (做标记),然后 V8 ,然后 V5 ;
- 当继续遍历 V5 的邻接点时,根据之前做的标记显示,所有邻接点都被访问过了。此时,从 V5 回退到 V8 ,看 V8 是否有未被访问过的邻接点,如果没有,继续回退到 V4 , V2 , V1 ;
- 通过查看 V1 ,找到一个未被访问过的顶点 V3 ,继续遍历,然后访问 V3 邻接点 V6 ,然后 V7 ;
- 由于 V7 没有未被访问的邻接点,所有回退到 V6 ,继续回退至 V3 ,最后到达 V1 ,发现没有未被访问的;
- 最后一步需要判断是否所有顶点都被访问,如果还有没被访问的,以未被访问的顶点为第一个顶点,继续依照上边的方式进行遍历。
根据上边的过程,可以得到图 1 通过深度优先搜索获得的顶点的遍历次序为:
V1 -> V2 -> V4 -> V8 -> V5 -> V3 -> V6 -> V7
所谓深度优先搜索,是从图中的一个顶点出发,每次遍历当前访问顶点的临界点,一直到访问的顶点没有未被访问过的临界点为止。然后采用依次回退的方式,查看来的路上每一个顶点是否有其它未被访问的临界点。访问完成后,判断图中的顶点是否已经全部遍历完成,如果没有,以未访问的顶点为起始点,重复上述过程。
深度优先搜索是一个不断回溯的过程。
二、广度优先搜索(BFS)
广度优先搜索(Breadth-First-Search),简称 BFS。它是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索
广度优先搜索类似于树的层次遍历。从图中的某一顶点出发,遍历每一个顶点时,依次遍历其所有的邻接点,然后再从这些邻接点出发,同样依次访问它们的邻接点。按照此过程,直到图中所有被访问过的顶点的邻接点都被访问到。
最后还需要做的操作就是查看图中是否存在尚未被访问的顶点,若有,则以该顶点为起始点,重复上述遍历的过程。

以上面的无向图为例,假设 V1 作为起始点,遍历其所有的邻接点 V2 和 V3 ,以 V2 为起始点,访问邻接点 V4 和 V5 ,以 V3 为起始点,访问邻接点 V6 、 V7 ,以 V4 为起始点访问 V8 ,以 V5 为起始点,由于 V5 所有的起始点已经全部被访问,所有直接略过, V6 和 V7 也是如此。 以 V1 为起始点的遍历过程结束后,判断图中是否还有未被访问的点,由于图 1 中没有了,所以整个图遍历结束。遍历顶点的顺序为:
V1 -> V2 -> v3 -> V4 -> V5 -> V6 -> V7 -> V8