【图机器学习】cs224w Lecture 11 & 12 – 网络传播
转自本人://blog.csdn.net/New2World/article/details/106265878
我们研究网络,不仅是为了提取网络结构的特征或对节点进行分类。更多的是为了研究网络上的传播过程,比如消息在社交网络中的传播,以及传染病在人群中的传播。而现实世界中的网络是不会显式地表现出传播过程的,而是通过时间先后的关系展示出传播性的。
Decision Based Model of Diffusion
现在有两种选择 A 和 B,一个人现在要决定要么选 A 要么选 B。如果你的朋友和你做出同样的选择那么能得到一定的奖励,否则没有奖励。就像分系统的手游,你用 IOS 你可以和你周围用 IOS 的朋友一起玩,开心;但这样就失去了 Android 的朋友。那么用数学来描述就是,选 A 能得到 a 的 payoff,B 能得到 b。然后你有 d 个朋友,他们之中选择 A 的占比例 p,那么
b\cdot (1-p)\cdot d\end{cases}\ \ \ \ choose B\]
其实通过 a 和 b 的大小就能判断出为了将利益最大化是应该选 A 还是选 B。先定义一个阈值 \(q = \frac b{a+b}\),如果 p 大于这个阈值就说明选择 A 更有利,而当小于阈值时选择 B 得到的回报更多。那么为了简化问题,我们假设 \(a = b-\epsilon\) 即 a b 基本相等,且 \(q = 1/2\)。这就变成了一个“从众”的问题了,即选哪个的人多我选哪个。
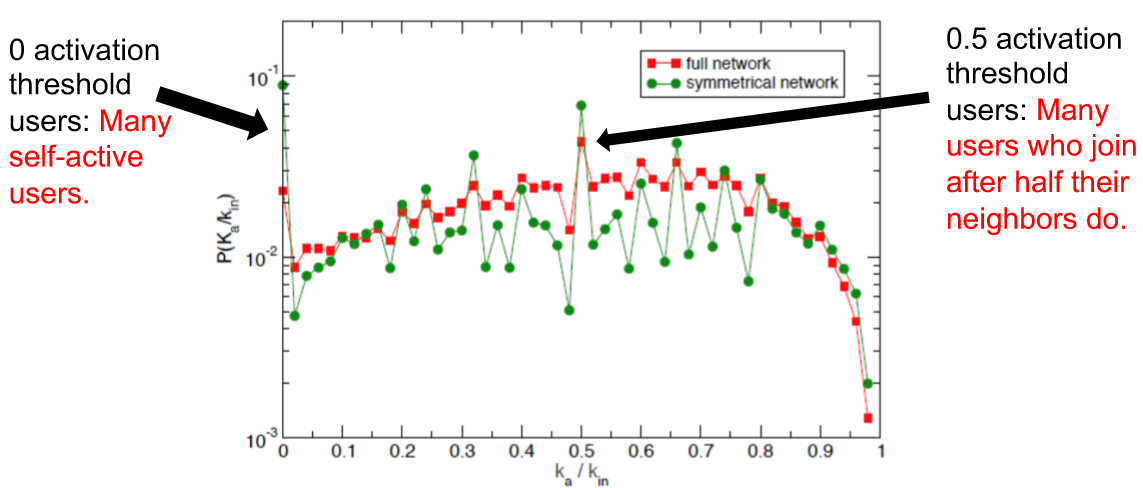
这里选择了 2011 年 Twitter 上西班牙在经济危机期间爆发的大规模抗议的话题为例。对使用了对应话题的 hashtag 的用户及用户间关系进行分析。定义两个符号 \(k_{in}\) 表示当一个用户开始参加抗议活动时他有多少好友,以及 \(k_a\) 此刻他有多少已经参加抗议了的朋友。然后将两个值的比定义为 activation threshold \(k_a/k_{in}\) 表示参加抗议的朋友占多大比例的时候,一个人可能会跟着一起参加。如果这个阈值趋近 \(0\) 说明他可能是发起者之一;而如果趋近 \(1\) 说明他受到了很大的“社会压力”,可能是“被迫”参加的抗议。下面这张图能看出很多人在超过半数的朋友参加后参加的,也有很多人是自发参加的。
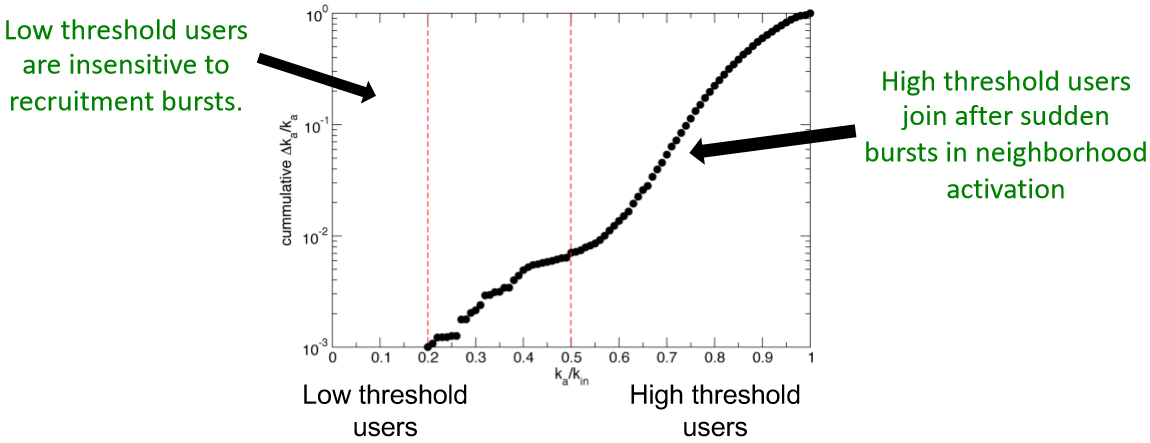
另一个假说是当很多朋友在短时间内都参加了抗议那这个用户大概率也会参加。而下面这个图有印证了这一点。注意纵坐标是累计的 \(\Delta k_a/k_a=(k_a^{t+1}-k_a^t)/k_a^{t+1}\),也就是说图中曲线上升快则表示短时间加入的人多。
Large Cascades
一个规律:规模很大的、“成功的” cascade 其实很少,大部分 cascade 都是中小规模的,那这些“成功的” cascade 是有谁或者哪一些人发起的呢?引入一种研究方法:k-core decomposition。所有节点都有至少 k 个 degree 的最大连通子图。如下图所示,k 越大说明这些节点更挨近“中心位置”。而大规模的 cascade 一般由这些靠近中心的节点发起。这种方法相比于 degree distribution 的优点是它能告诉我们哪些节点很有“影响力”的且相互连接。

Extending the Model
上面的模型只考虑了单选,如果一个个体能同时选择两个呢?比如我既买 IOS 也买 Android,那我既能跟 IOS 的好友玩也能跟 Android 的朋友玩,岂不美哉。然而,这样的话我得付出一定“代价” c,即我得买俩手机,氪两份金…… 还是用符号来表示的话就是
- AB – A / A – A: gets a
- AB – B / B – B: gets b
- AB – AB: gets \(max(a,b)-c\)
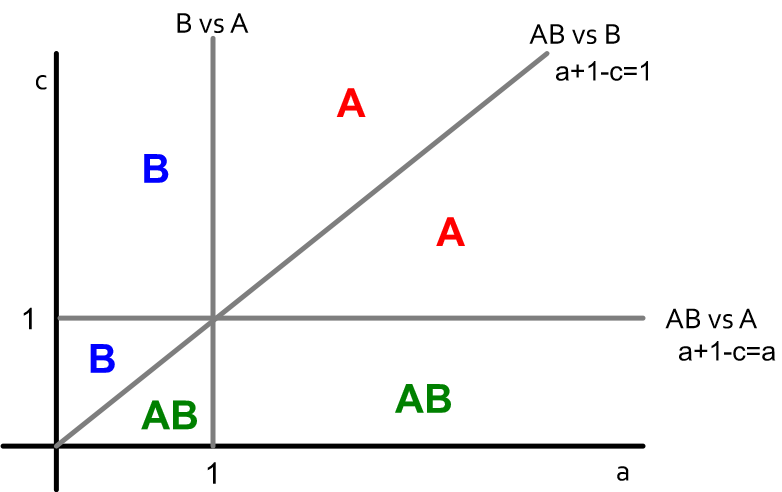
简化我们的网络结构,针对一条链进行分析。假如我们要确定中间节点的决策,那现在就有两种需要讨论的情况:(为了方便,设 \(b=1\))
-
两边的相邻节点为不同的单一选择,那么中间节点的选择对应的回报是:A – a, B – 1, AB – a+1-c
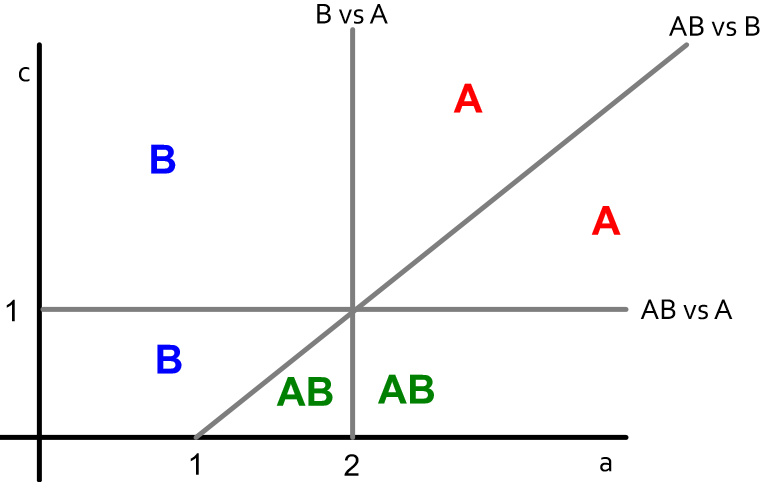
-
其中一边为多选,另一边单选,那中间节点的选择:A – a, B – 1+1, AB – max(a,1)+1-c


Probabilistic Spreading Models
上面讲了基于决策的模型,但现实生活中有些事情并不是人们的意愿能控制的,比如疾病传播。并不是说一个人过半数的朋友没被传染这个人就很安全,也并不是说当你的人际关系中半数以上的朋友感染了你就一定会感染,这只是概率大小的问题。
假设一个病人平均和 \(d\) 个人接触过,并且以概率 \(q>0\) 传染给其他人。那我们要研究的是当 \(d\) 和 \(q\) 取什么值或者满足什么条件的时候,这个病毒会持续传播直到感染所有人。如果将病毒传播看成一棵树,那么从0号病人开始向下展开,树的每一层就是一代感染/传播者,那么上述问题就转换为了在 \(d\) \(q\) 满足什么条件的情况下
\]
对于深度为 \(h\) 的节点,不被感染的概率为 \((1-q\cdot p_{h-1})^d\),即 \(h-1\) 的节点不传染给他接触的 \(d\) 个人中的任意一个。那么反过来 \(1-(1-q\cdot p_{h-1})^d\) 就是深度为 \(h\) 的节点存在被感染的概率。写成迭代的形式就是 \(f(x) = 1-(1-q\cdot x)^d\)。
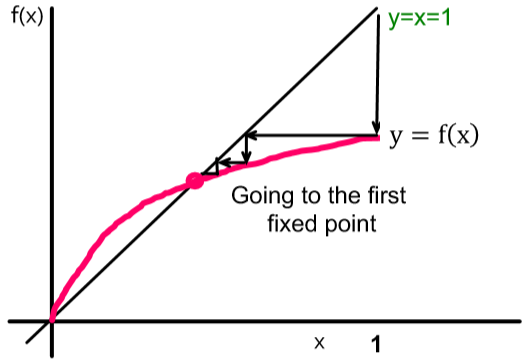
因为 x 的初始值为 1,即0号病人,那么接下来函数 \(f(x)\) 的一系列变化可以从上图中直观看出来是个向左递减的过程。而这条曲线和 \(f(x) = x\) 这条线的交点代表从某一深度开始节点被感染的概率都相等且为一个固定值了。
这张图如果视为函数图像的话是没有问题的;但作为这里的传播概率的话,从 \(x=1\) 到 \(f(x)=x\) 的 fixed point 之后就不会再往左画了,即曲线只存在于 \(f(x)=x\) 下面。
那么我们想让这个传播在一定深度后 die out,就是让这个 fixed point 落在原点上。通过分析梯度不难发现整个函数是单增的,但其梯度是单调非递增的,即函数增加趋势渐弱。于是考虑 \(f(\cdot)\) 在原点的梯度为 \(f'(0)=q\cdot d\),因此只要 \(f'(0) < 1\) 就能保证这个 fixed point 在原点上。这就是传染病学中判断病毒传播能力的 \(R_0\) 值,它的物理意义也很直观:\(q\cdot d\) 表示一个人平均能传染多少人。如果 \(R_0 \geq 1\) 则说明每个患者至少能传染一个人,那到最后全世界的人都可能被传染;但如果 \(R_0 < 1\) 则表示病毒可能不会传染任何一个人,这样一来可能到最后病毒就消失了。
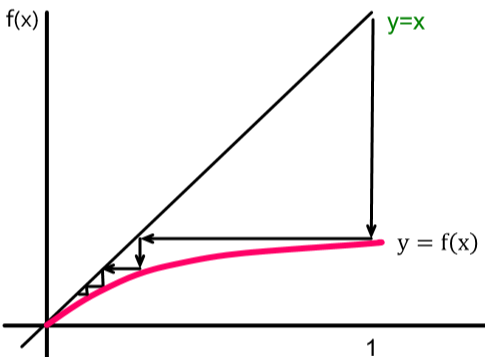
因此控制传染病的有效手段主要有
- 降低 \(d\):采取隔离措施,减少人与人之间的接触
- 降低 \(q\):勤洗手,戴口罩
这里给出了一些传染病的 \(R_0\) 值
- HIV:2~5
- 麻疹:12~18
- 埃博拉:1.5~2
传染病的传播能力还受很多因素影响,比如埃博拉的 \(R_0\) 看似不高,实则是因为其高死亡率导致病毒传播效率低。因此 \(R_0\) 只是一个作为参考的数值。
然后就有研究者通过对 Flickr 上图片的点赞来验证 \(R_0\) 值对社交网络的有效性。他们通过 \(q\cdot d\cdot \frac{avg(d_i^2)}{(avg d_i)^2}\) (后面的分式是为了矫正度分布的偏度而加入的) 作为 \(R_0\) 的估计值,然后根据时间先后关系对每个用户点赞图片的情况直接数他影响到的用户个数来作为参照。这样得到的结果的相关系数为 \(0.9765\),说明符合度较高。而 \(R_0\) 在 1 到 190 间,说明社交网络上的媒体传播效率相当之高。
Epidemic Models
病毒传播的两个重要参数
- birth rate \(\beta\):受感染者传播给未受感染者的概率
- death rate \(\delta\):受感染者治愈的概率
然后一般遵循 SEIRZ 的模式,即
- S: susceptible
- E: exposed
- I: infected
- R: recovered
- Z: immune
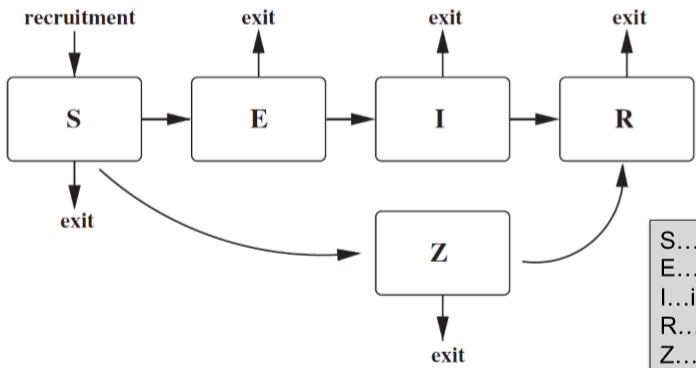
这个模型可以只取一部分,比如水痘的模型就是 SIR,即一旦治愈就不会再长水痘。那么这个模型的动态可以表示为
\frac{dR}{dt}=\delta I \\
\frac{dI}{dt}=\beta SI-\delta I\]
这里的微分表示对应部分个体数变化速率,不过我没搞懂为什么 dS 这里要乘 I ?
另一种模型是 SIS,即被治愈的个体有再一次被感染的风险
\frac{dI}{dt}=\beta SI-\delta I\]
此时病毒的 strength 为 \(\beta / \delta\),且存在一个阈值 \(\tau\),如果病毒的感染能力 \(\beta / \delta < \tau\),表明这个病毒最终会消失。那这个阈值如何确定?\(\tau=1/\lambda_{1,A}\),其中 \(\lambda_{1,A}\) 是图的邻接矩阵的最大特征值[1]。事实表明,这个病毒是否消失与最初有多少人感染无关。
Rumor spread modeling using SEIZ
用 SEIZ 分析 twitter 上的谣言
- S: Twitter 账号
- I: 相信事实 / 谣言,并转发
- E: 还没相信
- Z: 质疑,还没转发
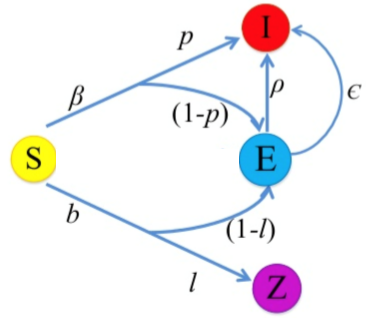
上图详细地描述了各个状态间的转移概率。然后通过网格搜索最小化 \(|I(t)-tweets(t)|\) 来训练模型。具体怎么训练……超纲了没讲,有空我去看看,随缘补充……下图中的 ODE 是常微分方程。
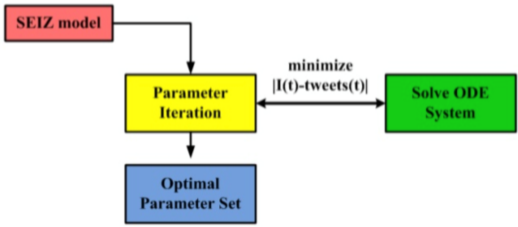
将 SEIZ 用在社交网络上的话,会使用一种新的指标来评估传播效率
\]
这个指标是一种 flux ratio,即通量比。它标明了“进入状态 E 和离开状态 E 的数据量的比值”。也就是说,\(R_{SI}\) 越低说明看到谣言的人多同时转发的人也多,即传播效率很高;反之,谣言不流行。
而实验结果显示,谣言的接受率惊人地高,可见“愚昧”的人不少,也可能是这些谣言的包装真的厉害。
-
为什么邻接矩阵的最大特征值的倒数是阈值?难道它揭示了网络的疏密程度? ↩︎

