【论文阅读】增量学习近期进展及未来趋势预测
【摘要】 本文通过三篇发表在CVPR 2019上的论文,对增量学习任务进行简单的介绍和总结。在此基础上,以个人的思考为基础,对这一研究领域的未来趋势进行预测。
一、背景介绍
目前,在满足一定条件的情况下,深度学习算法在图像分类任务上的精度已经能够达到人类的水平,甚至有时已经能够超过人类的识别精度。但是要达到这样的性能,通常需要使用大量的数据和计算资源来训练深度学习模型,并且目前主流的图像分类模型对于训练过程中没见过的类别,识别的时候完全无能为力。一种比较简单粗暴的解决方法是:对于当前模型识别不了的类别,收集大量的新数据,并和原来用于训练模型的数据合并到一起,对模型进行重新训练。但是以下的一些因素限制了这种做法在实际中的应用:
-
当存储资源有限,不足以保存全部数据的时候,模型的识别精度无法保证;
-
重新训练模型需要消耗大量的算力,会耗费大量的时间,同时也会付出大量的经济成本(如电费、服务器租用费等)。
为了解决这些问题,使得增加模型可识别的类别数量更容易一些,近年来学术界中出现了一些针对深度学习的“增量式学习”算法。这类算法有三点主要的假设:
-
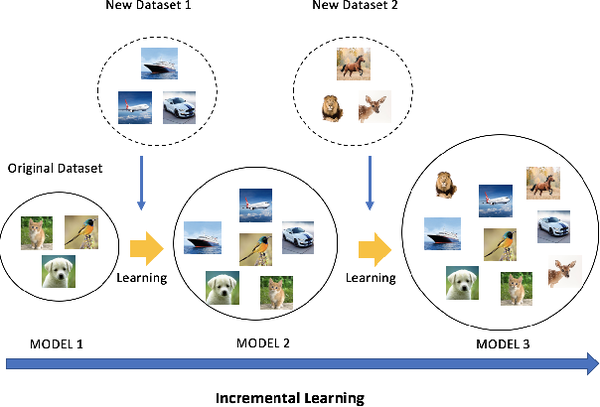
不同类别的数据是分批次提供给算法模型进行学习的,如下图所示;
-
系统的存储空间有限,至多只能保存一部分历史数据,无法保存全部历史数据,这一点比较适用于手机、PC机等应用场景;
-
在每次提供的数据中,新类别的数据量比较充足。
这类任务的难点主要体现在两方面:
-
由于每次对模型的参数进行更新时,只能用大量的新类别的样本和少量的旧类别的样本,因此会出现新旧类别数据量不均衡的问题,导致模型在更新完成后,更倾向于将样本预测为新增加的类别,如下图所示;
-
由于只能保存有限数量的旧类别样本,这些旧类别的样本不一定能够覆盖足够丰富的变化模式,因此随着模型的更新,一些罕见的变化模式可能会被遗忘,导致新的模型在遇到一些旧类别的样本的时候,不能正确地识别,这个现象被称作“灾难性遗忘”。
目前主流地增量学习算法可以分为两类:
-
基于GAN的方法。这类方法不保存旧类别的样本,但是会使用生成对抗网络(GAN),学习生成每类的样本。因此,在对模型进行更新的时候,只要使用GAN随机生成一些图像即可,无需保存大量的样本;
-
基于代表性样本的方法。这类方法对于每个旧类别,保存一定数量的代表性样本,在训练的时候,使用旧类别的代表性样本和新类别的样本来更新模型,从而保证模型既能准确地识别旧类别,也能准确地识别新类别。下面针对这两类方法,分别简单介绍一些发表在CVPR 2019上的论文,并简单总结一下这两类方法各自的优势和不足。
二、基于GAN的方法
论文:Learning to Remember: A Synaptic Plasticity Driven Framework for Continual Learning
作者:Oleksiy Ostapenko, Mihai Puscas, Tassilo Klein, Patrick Jaehnichen, Moin Nabi
出处:CVPR 2019
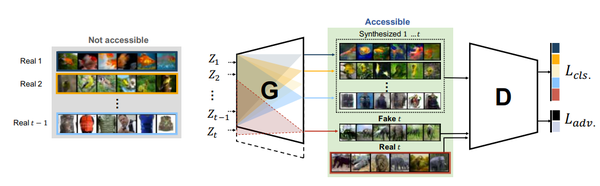
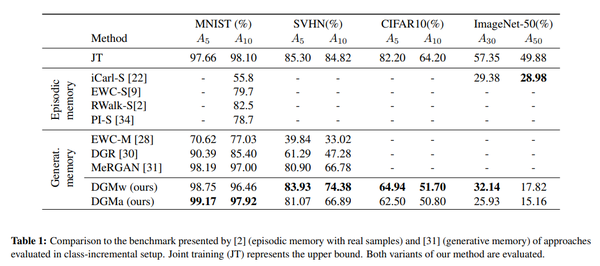
这篇文章提出了一种基于GAN的增量式学习方法,如上图所示。其中判别器(D)部分的设计与ACGAN基本相同,包括对抗损失和分类损失两部分;生成器的结构则比较特殊。具体来说,本文提出的生成器除了需要学习生成器的权重之外,还要对每一层的权重学习一个mask。这个mask的作用是限制每次允许更新的权重,从而防止模型忘记之前学习到的东西。由于mask的存在,模型越往后可以更新的权重值也会越少,因此可能会导致生成器的生成能力不足。为了解决这个问题,作者提出在每次学习完新数据之后,增加生成器的参数量,从而保证生成器的生成能力不会明显下降。实验结果显示,在小规模的数据集上,该方法有比较明显的性能优势,如下表所示。
三、基于代表性样本的方法
论文:Large Scale Incremental Learning
作者:Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, Yun Fu
出处:CVPR 2019
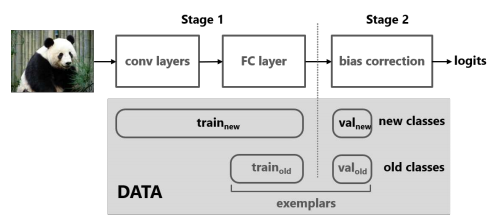
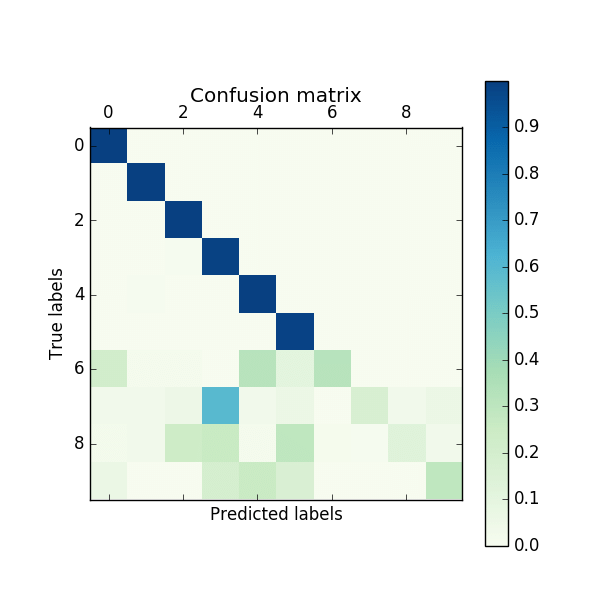
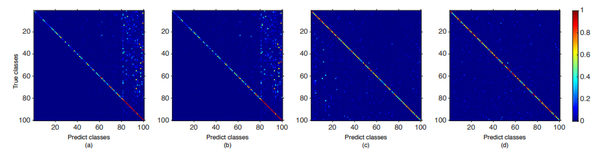
这篇文章首先假设增量学习的方法,相比于直接使用所有数据进行训练的方法,性能下降大的原因,是因为CNN模型最后用于输出类别预测概率的全连接层向新增加的类别偏移了(即更倾向于将类别预测为新加入的类别),并通过实验(固定网络前边的层并重新训练全连接层、混淆矩阵)验证了这个假设。为了解决这个问题,作者提出对新加入类别的概率进行修正,如上图所示。
具体来说,本文方法需要保存一定数量的旧类别的代表性样本,在得到新类别数据的时候,包含三步操作:
-
将旧类别的代表性样本和新类别的样本划分为训练集和校验集,其中在校验集里,各类的样本数量是均衡的;
-
使用训练样本训练一个新模型,其中包含两部分损失,一个是标准的分类损失,另一个是知识蒸馏损失,目标是保证新模型在旧类别上的概率预测值和旧模型尽可能相同,从而保留旧模型学到的信息(新类别和旧类别的样本都参与计算两个损失);
-
使用校验集的数据学习一个线性模型,对新模型预测的logits进行修正,其中保留旧类别上的logits,只对新类别上的logits进行修正,如下边的公式所示。

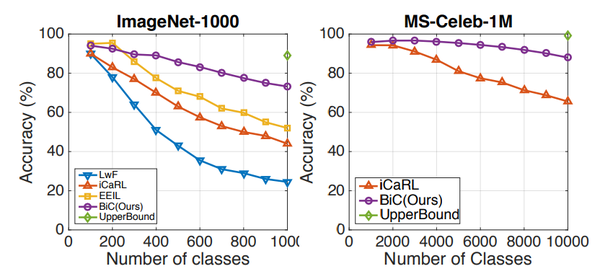
实验结果显示,相比于经典的LwF方法、iCaRL方法,本文方法在大规模、大增幅(一次加入的类别多)的数据库和设置下提升较明显,在小数据库上与已有方法性能相当,如下边的图表所示。

论文:Learning a Unified Classifier Incrementally via Rebalancing
作者:Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, Dahua Lin
出处:CVPR 2019
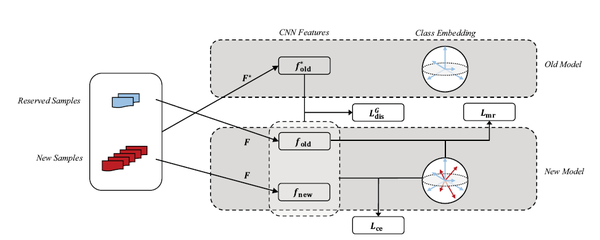
这篇文章根据现有增量学习算法的问题,提出了三点改进,如上图所示:
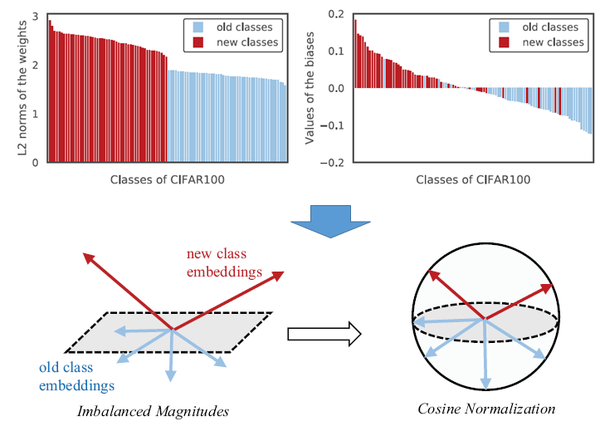
第一,作者发现,由于新类的特征向量幅值和旧类的不一样,因此模型会偏向于新类。为了解决这个问题,提出对特征向量、分类器的权重向量进行归一化,保证幅值等于1。相应的,分类损失和蒸馏损失也都在归一化之后的特征向量上使用,如下图所示;
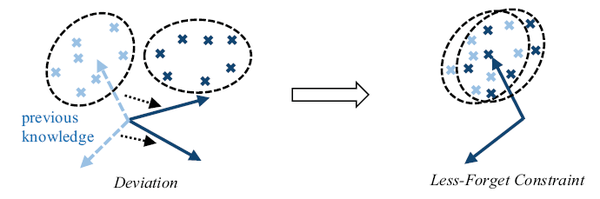
第二,为了减少模型遗忘,要求新模型的归一化特征和旧模型尽量相同,因此提出了一种新的蒸馏损失。这个损失的思想是,旧模型学到的不同类别的特征分布一定程度上反映了类别之间的关系,因此保持这种关系对于防止遗忘也有意义,如下图所示;
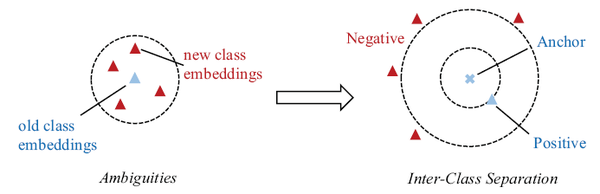
第三,在分类的时候,使用large-margin的分类损失,使用易误分的新类别作为难例,提升训练的效率,如下图所示。
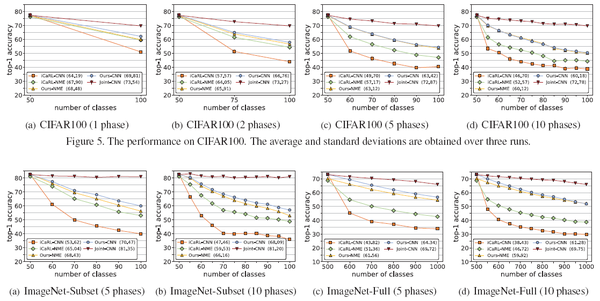
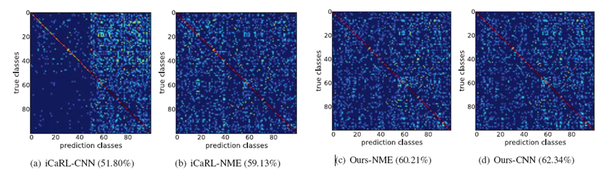
实验结果显示,该方法相比于经典的iCaRL增量学习算法,有十个点以上的提升,如下图所示。
四、总结
增量学习的主流方法分为基于GAN的方法和基于代表性样本的方法两大类。
其中,基于GAN的方法通过GAN“记住”旧类别的数据,在更新模型的时候,可以生成任意多的旧类别样本,但是这类方法的上限受制于GAN的生成能力。此外,基于GAN的方法宣称的一个优势是不需要存储历史数据,但是一般来说,GAN模型本身也要占用一定的存储空间(通常在几十MB这个数量级),如果用这部分空间来直接存储代表性的历史数据,按照一张图片200kB计算,也可以存储几百张图片了。所以一个很有意思的问题是,占用同样存储空间的情况下,基于GAN的方法真的比基于代表性样本的方法更好么?从目前来看,基于GAN的方法识别精度通常不如基于代表性样本的方法。未来基于GAN的增量学习方法如果想真正实用化,既要提升生成图像的质量,还要保证在使用同样的存储空间或者更少的存储空间的情况下,达到更好的性能,任重而道远。
另一方面,基于代表性样本的方法则保存少量的历史样本,在更新模型的时候,使用一个额外的蒸馏损失,保证旧模型的知识可以迁移到新模型中,目前来看,这类方法的识别精度通常更高一些。
不过增量学习的思路不应该局限于这两大类方法,是否有可能既不用GAN,也不保存代表性的历史样本,而只使用旧模型本身来进行增量学习呢?或者是否有其他更高效的方法?这些都是值得未来继续探索的方向。
总的来说,在条件允许的情况下,使用全部数据重新训练模型的效果仍然是毫无争议的最佳,GNN和代表性样本两种增量学习方法仍然达不到使用所有数据完全重新训练的识别精度。因此,当前的增量学习算法仍然有很长的路要走。但是目前看来,增量学习这条路如果能够走通,无疑会大量减少云服务对资源的需求量;另一方面,在一些对数据安全十分敏感的应用中,也可以保证数据不出内网,在有限的计算资源下即可完成模型的更新。所以在我看来,增量学习这个研究方向的前景还是很光明的,只是目前的技术还没有发展到足够使用的地步而已。



