架构设计 | 分布式业务系统中,全局ID生成策略
本文源码:GitHub·点这里 || GitEE·点这里
一、全局ID简介
在实际的开发中,几乎所有的业务场景产生的数据,都需要一个唯一ID作为核心标识,用来流程化管理。比如常见的:
- 订单:order-id,查订单详情,物流状态等;
- 支付:pay-id,支付状态,基于ID事务管理;
如何生成唯一标识,在普通场景下,一般的方法就可以解决,例如:
import java.util.UUID;
public class UuidUtil {
public static String getUUid() {
UUID uuid = UUID.randomUUID();
return String.valueOf(uuid).replace("-","");
}
}
这个方法可以解决绝大部分唯一ID需求的场景业务,但是网上各种UUID重复场景的描述帖,说的好像该API不好用。
絮叨一句:说一个真实使用的业务场景,大概是半年近3000万的数据流水,用的就是UUID的API,暂时未捕捉到ID重复的问题,仅供参考。
二、雪花算法
1、概念简介
Twitter公司开源的分布式ID生成算法策略,生成的ID遵循时间的顺序。
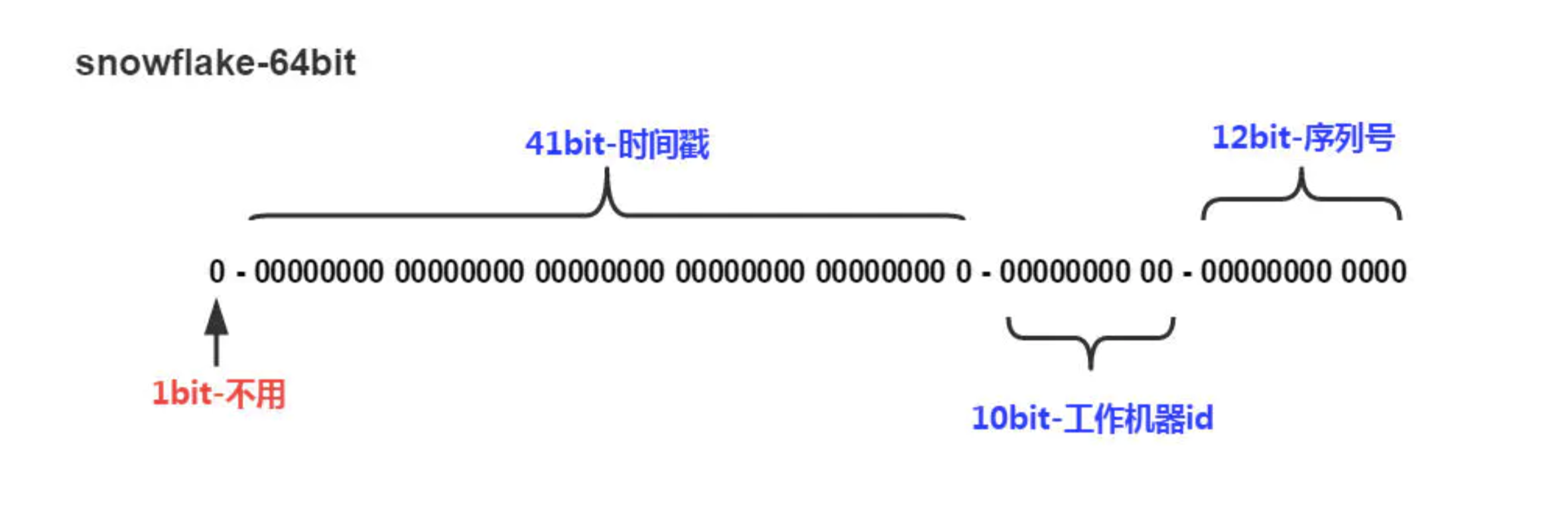
- 1为位标识,始终为0,不可用;
- 41位时间截,存储时间截的差值(当前时间截-开始时间截);
- 10位的机器标识,10位的长度最多支持部署1024个节点;
- 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒产生4096个ID序号;
SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高。
2、编码实现
工具类中很多可以自定义的,比如起始时间,机器ID配置等。
/**
* 雪花算法ID生成
*/
public class SnowIdWorkerUtil {
// 开始时间截 (2020-01-02)
private final long timeToCut = 1577894400000L;
// 机器ID所占的位数
private final long workerIdBits = 2L;
// 数据标识ID所占的位数
private final long dataCenterIdBits = 8L;
// 支持的最大机器ID,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 支持的最大数据标识ID,结果是31
private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
// 序列在ID中占的位数
private final long sequenceBits = 12L;
// 机器ID向左移12位
private final long workerIdShift = sequenceBits;
// 数据标识ID向左移17位(12+5)
private final long dataCenterIdShift = sequenceBits + workerIdBits;
// 时间截向左移22位(5+5+12)
private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
// 生成序列的掩码
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
// 工作机器ID(0~31)
private long workerId;
// 数据中心ID(0~31)
private long dataCenterId;
// 毫秒内序列(0~4095)
private long sequence = 0L;
// 上次生成ID的时间截
private long lastTimestamp = -1L;
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param dataCenterId 数据中心ID (0~31)
*/
public SnowIdWorkerUtil (long workerId, long dataCenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("workerId 不符合条件");
}
if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
throw new IllegalArgumentException("dataCenterId 不符合条件");
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
}
public synchronized String nextIdVar(){
return String.valueOf(nextId());
}
/**
* 线程安全,获得下一个ID
*/
private synchronized long nextId() {
long timestamp = timeGen();
// 如果当前时间小于上一次ID生成的时间戳,抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format(
"时间顺序异常,时间差(上次时间-现在)=%d",
lastTimestamp - timestamp));
}
// 如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 时间戳改变,毫秒内序列重置
sequence = 0L;
}
// 上次生成ID的时间截
lastTimestamp = timestamp;
// 移位并通过或运算拼到一起组成64位的ID
return ((timestamp - timeToCut) << timestampLeftShift)
| (dataCenterId << dataCenterIdShift)
| (workerId << workerIdShift) | sequence;
}
/**
* 阻塞,获得新的时间戳
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回当前时间节点
*/
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
// 参数在实际业务下需要配置管理
SnowIdWorkerUtil idWorker = new SnowIdWorkerUtil(1, 1);
for (int i = 0; i < 100; i++) {
String id = idWorker.nextIdVar();
System.out.println(id+" "+id.length()+"位");
}
}
}
三、自定义实现
还有一种常见的实现思路,基于数据库的自增主键ID,不过基于这个原理,却有各种不同的实现策略。
简单表结构:
CREATE TABLE `du_temp_id` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='主键ID临时表';
1、基于主键
这种模式的原理比较单调,向临时表写入一条记录,借助MySQL生成的唯一主键ID,然后拿出来稍微处理一下,作为各种业务场景的唯一ID使用。
@Service
public class TempIdServiceImpl implements TempIdService {
@Resource
private TempIdMapper tempIdMapper ;
@Override
public List<String> getIdList() {
List<String> idList = new ArrayList<>() ;
TempIdEntity tempIdEntity = new TempIdEntity ();
tempIdEntity.setCreateTime(new Date());
for (int i = 0 ; i < 10 ; i++){
tempIdMapper.insert(tempIdEntity);
idList.add(UuidUtil.getNoId(8,Long.parseLong(tempIdEntity.getId().toString()))) ;
}
return idList ;
}
}
问题点:如果作为ID生成的临时表所在的MySQL服务宕掉,那可能会影响整个业务流程,造成雪崩效应。
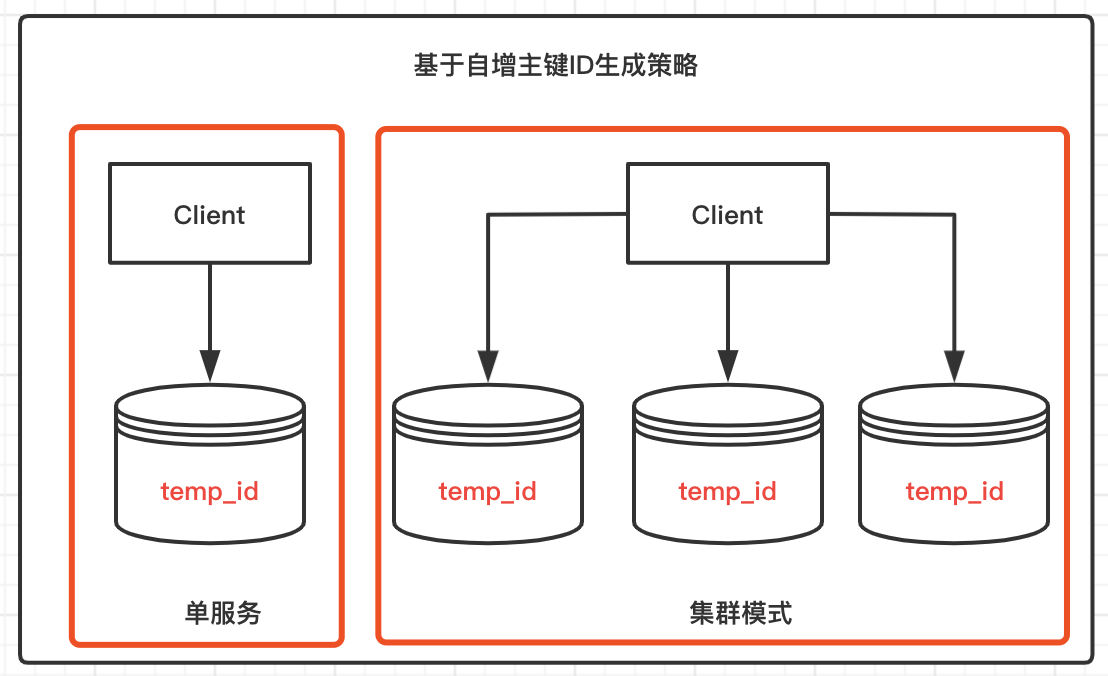
2、高可用集群
单服务如果不能安稳的支撑业务需求,很自然集群模式就该上场了。提供多台MySQL服务[A,B,C],处理策略也不止一种:
- 库设置主键自增策略
例如A库[1,4,7],B库[2,5,8],C库[3,6,9],基于不同自增规则,生成统一的自增唯一标识。
- 生成ID做分库标识
这种先把ID生成,然后不同的数据库生成的ID给一个不同的标识,例如UIDA,UIDB,UIDC。
@Service
public class TempIdServiceImpl implements TempIdService {
@Resource
private TempIdMapper tempIdMapper ;
@Override
public List<String> getRouteIdList() {
List<String> idList = new ArrayList<>() ;
TempIdEntity tempIdEntity = new TempIdEntity ();
tempIdEntity.setCreateTime(new Date());
for (int i = 0 ; i < 2 ; i++){
tempIdMapper.insertA(tempIdEntity);
idList.add(UuidUtil.getRouteId("UID-A",10,
Long.parseLong(tempIdEntity.getId().toString()))) ;
tempIdMapper.insertB(tempIdEntity);
idList.add(UuidUtil.getRouteId("UID-B",10,
Long.parseLong(tempIdEntity.getId().toString()))) ;
tempIdMapper.insertC(tempIdEntity);
idList.add(UuidUtil.getRouteId("UID-C",10,
Long.parseLong(tempIdEntity.getId().toString()))) ;
}
return idList ;
}
}
结果样例:
UID-A00001,UID-B00001,UID-C00001
UID-A00002,UID-B00002,UID-C00002
3、ID样式优化
从数据获取的ID基本是一个自增的整数序列,可以提供一个格式美化工具方法。
public class UuidUtil {
private static final String ZERO = "00000000000";
private static final String PREFIX = "UID";
public static String getNoId(int length,Long id){
String idVar = String.valueOf(id) ;
if (idVar.length()>length){
return PREFIX+idVar ;
} else {
int gapLen = length-idVar.length()-PREFIX.length() ;
return PREFIX+ZERO.substring(0,gapLen)+idVar ;
}
}
public static String getRouteId(String route,Integer length,Long id){
String idVar = String.valueOf(id) ;
if (idVar.length()>length){
return route+idVar ;
} else {
int gapLen = length-idVar.length()-route.length() ;
return route+ZERO.substring(0,gapLen)+idVar ;
}
}
}
基于不同的策略,把ID格式为统一的位数。
4、性能问题
如果在高并发的业务场景下,实时基于MySQL去生成唯一ID容易产生性能瓶颈,当然其他方法也可能产生这个问题。可以在系统空闲时间批量生成一批,放入缓存中,在使用的时候直接从缓存层取出即可。
四、源代码地址
GitHub·地址
//github.com/cicadasmile/data-manage-parent
GitEE·地址
//gitee.com/cicadasmile/data-manage-parent

推荐阅读:数据和架构管理
| 序号 | 标题 |
|---|---|
| A01 | 数据源管理:主从库动态路由,AOP模式读写分离 |
| A02 | 数据源管理:基于JDBC模式,适配和管理动态数据源 |
| A03 | 数据源管理:动态权限校验,表结构和数据迁移流程 |
| A04 | 数据源管理:关系型分库分表,列式库分布式计算 |
| C01 | 架构基础:单服务.集群.分布式,基本区别和联系 |