scrapy爬虫案例–爬取阳关热线问政平台
- 2021 年 5 月 8 日
- 筆記
阳光热线问政平台://wz.sun0769.com/political/index/politicsNewest?id= …
Continue Reading阳光热线问政平台://wz.sun0769.com/political/index/politicsNewest?id= …
Continue Reading
Scrapy Scrapy是纯python实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。 Scrapy使用 …
Continue Reading
笔者最近对scrapy的学习可谓如火如荼,虽然但是,即使是一整天地学习下来也会有中间两三个小时的“无效学习”,不是笔者开 …
Continue ReadingSelenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,可以按指定的命令自动操作,但是他需要与第三 …
Continue ReadingBeautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。 一 …
Continue Reading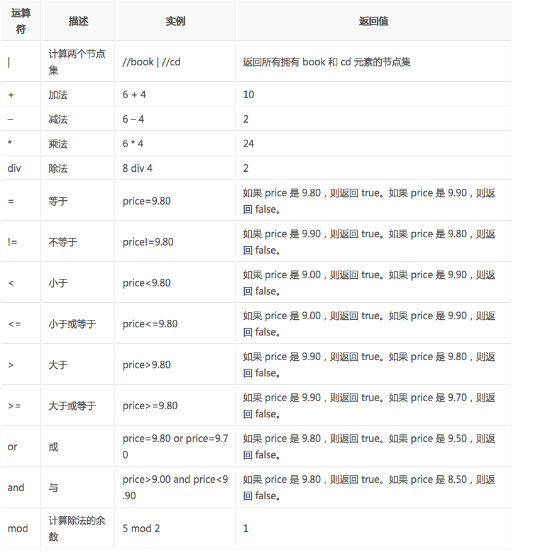
使用lxml之前,我们首先要会使用XPath。利用XPath,就可以将html文档当做xml文档去进行处理解析了。 一、 …
Continue Reading一、什么是正则表达式? 正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。 正则表达式是对 …
Continue Readingurllib3是一个功能强大,对SAP健全的 HTTP客户端,许多Python生态系统已经使用了urllib3。 一、安 …
Continue Readingurllib是Python中请求url连接的官方标准库,在Python3中将Python2中的urllib和urllib …
Continue Reading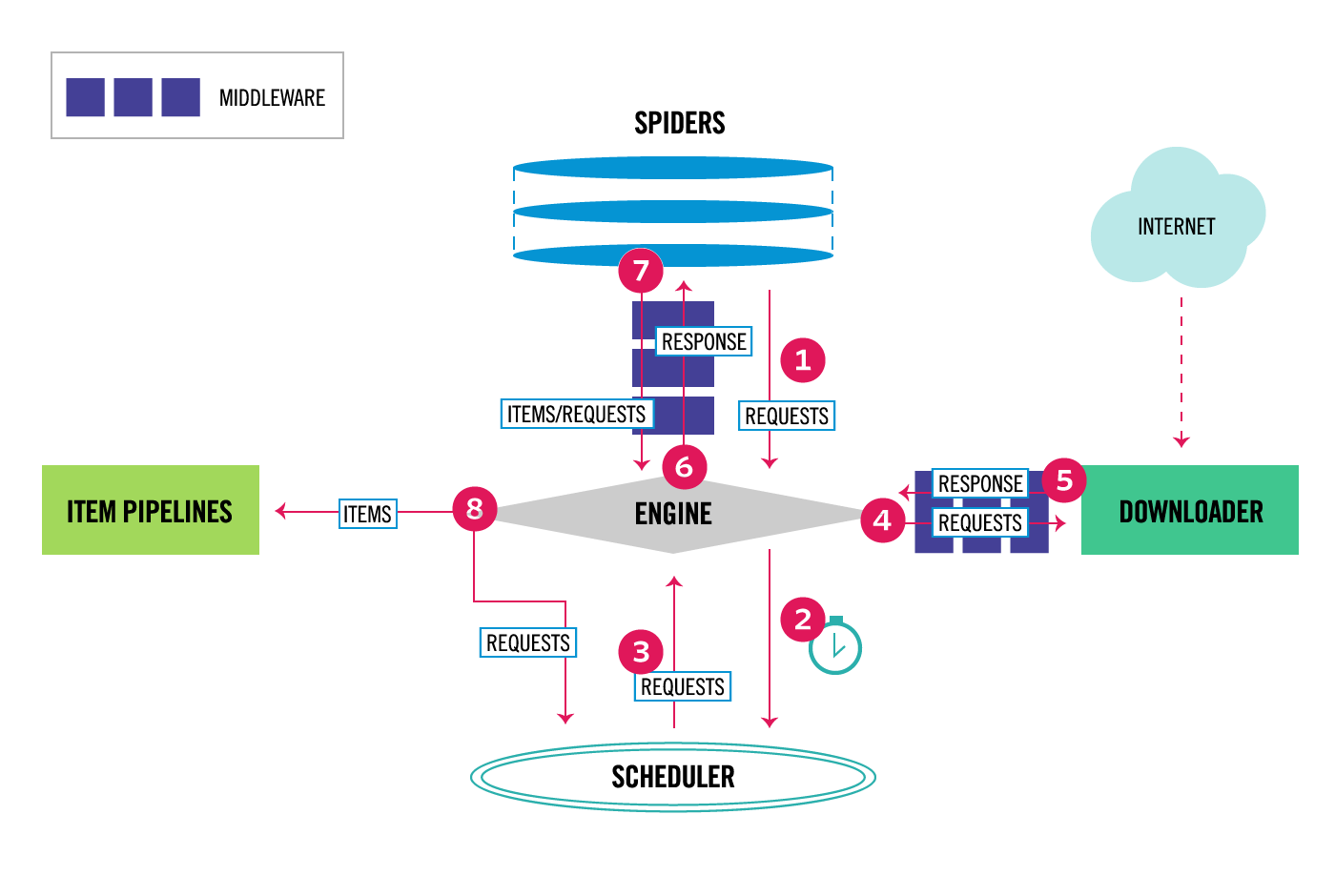
基于Scrapy的B站爬虫 最近又被叫去做爬虫了,不得不拾起两年前搞的东西。 说起来那时也是突发奇想,想到做一个B站的爬 …
Continue Reading