Flume数据采集结合etcd作为配置中心在爬虫数据采集处理中的架构实践。
- 2020 年 4 月 2 日
- 筆記
Apache Flume是一个分布式的、可靠的、可用的系统,用于有效地收集、 聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储,但是其本身是以本地properties作为配置的,配置无法做到动态监听和更新。
一、Flume和ETCD的结合,使用ETCD作为flume 数据采集的配置中心。
那么如何做出一个flume的动态配置中心呢,etcd 可以是一个很好的选择。etcd的API版本有v2和v3两个,这里选择v3版本。在flume启动的时候,可以启动etcd的监听。
... @Override public void start() { //初始化监听 EtcdUtil.initListen(etcdConfig); sinkCounter.start(); sinkCounter.incrementConnectionCreatedCount(); super.start(); } ...
/** * etcd的监听,监听指定的key,当key 发生变化后,监听自动感知到变化。 key发生变化后,会更新本地缓存数据 * * @param key 指定需要监听的key */ public static void initListen(String key) { try { //加载配置 loadProperties(getConfig(EtcdUtil.getEtclClient().getKVClient().get(ByteSequence.fromString(key)).get().getKvs())); new Thread(() -> { Watch.Watcher watcher = EtcdUtil.getEtclClient().getWatchClient().watch(ByteSequence.fromString(key)); try { while (true) { watcher.listen().getEvents().stream().forEach(watchEvent -> { KeyValue kv = watchEvent.getKeyValue(); log.info("etcd event:{} ,change key is:{},afterChangeValue:{}", watchEvent.getEventType(), kv.getKey().toStringUtf8(), kv.getValue().toStringUtf8()); loadProperties(kv.getValue().toStringUtf8()); }); } } catch (InterruptedException e) { log.error("etcd listen start cause Exception:{}", e); } }).start(); } catch (Exception e) { log.error("etcd listen start cause Exception:{}", e); } }
备注:完整的代码可以参考笔者博客:https://www.cnblogs.com/laoqing/p/8967549.html
监听完配置后,就可以在etcd 的配置中心中管理配置了

然后就可以通过如下代码获取配置了
.... EtcdUtil.getLocalPropertie("xxxxx") ....
二、Flume 日志采集中的流水线架构设计
flume 中数据采集是通过source->Sink的方式进行数据采集入库的,但是有一个缺点就是数据中如果需要做一些ETL的业务处理,比如简单的数据加工,或者增加一些业务逻辑处理等然后再入库,无法满足。而是我们就可以对flume原有的架构进行拓展。
拓展后的架构图如下所示。
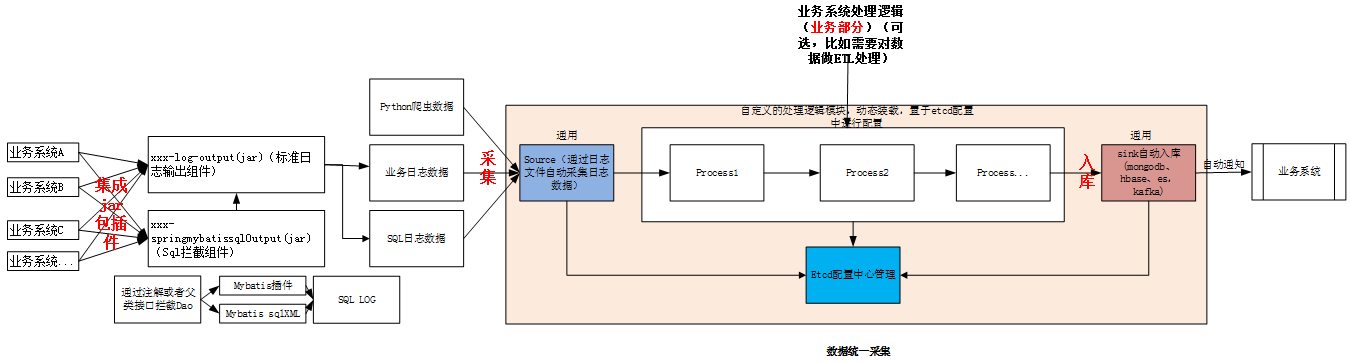
- 1、用户可以自定义process,继承统一的process接口,用户的process自己打成jar包。放到flume的lib目录中。
-
public interface Processor<T> { T process(T log); }
-
- 2、etcd动态配置中,配置需要使用哪些process,在多个process的时候,在etcd动态配置中配置顺序。
- processors=[{“processor”:”com.xxx.flume.tax.processor.TaxCrawlerDataCommonProcessor”,”logType”:”5″}] # logType代表日志类型
-
public class ProcessorBean { private String processor; private String logType; private Processor processorInstance; public Processor getProcessorInstance() { return processorInstance; } public void setProcessorInstance(Processor processorInstance) { this.processorInstance = processorInstance; } public String getProcessor() { return processor; } public void setProcessor(String processor) { this.processor = processor; } public String getLogType() { return logType; } public void setLogType(String logType) { this.logType = logType; } @Override public String toString() { return "ProcessorBean{" + "processor='" + processor + ''' + ", logType='" + logType + ''' + ", processorInstance=" + processorInstance + '}'; } }
...
processorBeanList = GsonUtil.gson.fromJson(EtcdUtil.getLocalPropertie("processors"), new TypeToken<List<ProcessorBean>>() { }.getType()); processorBeanList.forEach(processorBean -> { try { Processor<?> processor = (Processor<?>) Class.forName(processorBean.getProcessor()).newInstance(); processorBean.setProcessorInstance(processor); } catch (Throwable e) { e.printStackTrace(); } });
...
- 3、process 为动态装载形式,可以随时开启和关闭。Process中业务自己处理自己的业务逻辑。
- 4、source负责数据采集
- 5、sink负责数据入库到目标端,并且负责通知(可以在动态配置中配置是否开启通知功能)
- isNotice=1#1代表打开通知
-
public interface Notice { void noticePostLog(String logType); void noticePostLog(List<Map<String,Object>> noticeMsg); }
public void noticePostLog(String logType) { if (null != EtcdUtil.getLocalPropertie("isNotice") && "1".equals(EtcdUtil.getLocalPropertie("isNotice"))) { List<Map<String, Object>> callList = new ArrayList<>(); ................ if (null != callList && callList.size() > 0) { noticePostLog(callList); } } }
if (null != processorBeanList && processorBeanList.size() > 0) { for (ProcessorBean processorBean : processorBeanList) { try { if (logType.equals(processorBean.getLogType())) { if ("2".equals(logType)) { log = (BusinessLog) processorBean.getProcessorInstance().process(log); } else if ("5".equals(logType)) { log = (CrawlerLog) processorBean.getProcessorInstance().process(log); } } } catch (Throwable e) { logger.error("exec process cause Exception", e); } } }
- 6、通知为一个通用的json字段。
- 7、后续所有的应用服务器都在装机时,统一预先把flume包放入进去。用户在使用flume时,只需要做配置以及上传自己的process包。
- 8、除了process不能复用外,其他的部分都通用组件复用。
- 9、process就类似流水线作业的一样。
本文作者:张永清 连接:https://www.cnblogs.com/laoqing/p/12620747.html
三、Flume 日志采集中的流水线架构设计在爬虫中的架构实践
这里以税务数据爬虫为例,仔细看如下的架构设计
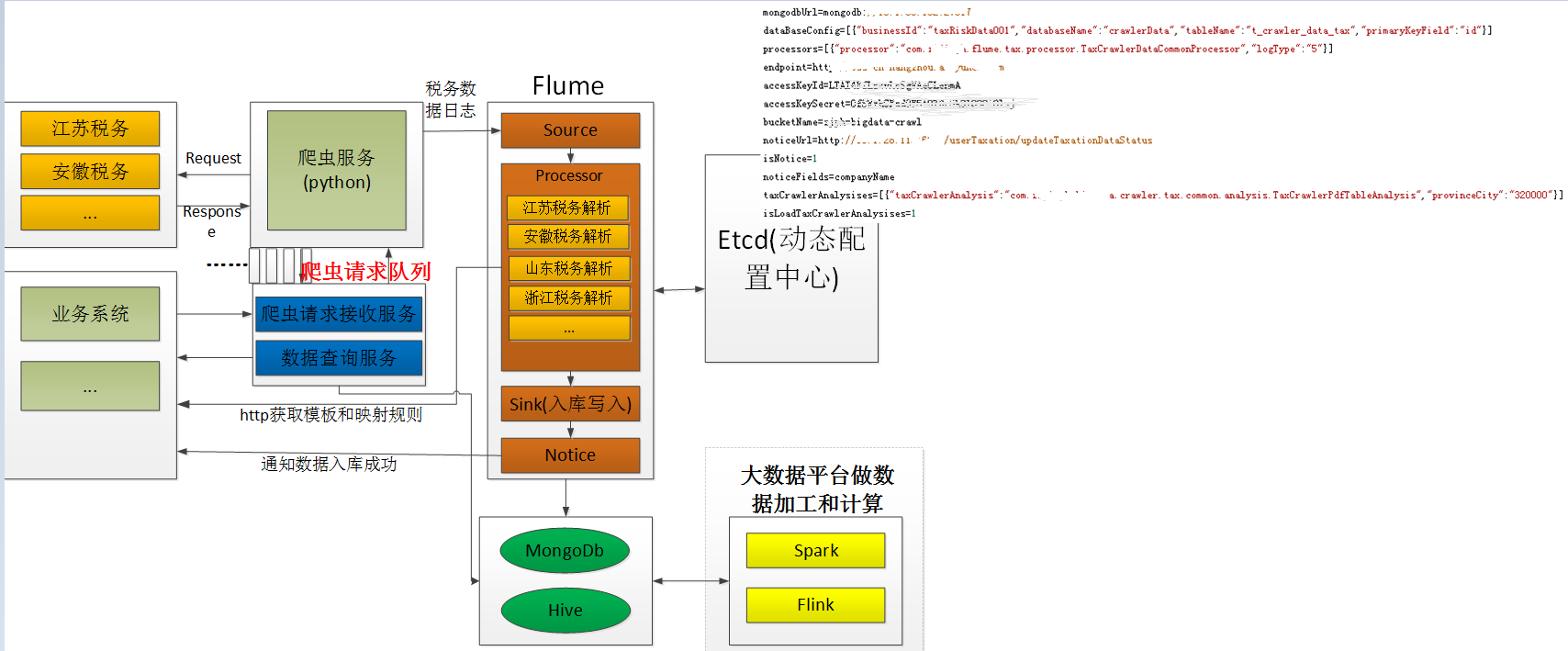
- 1、税务的爬虫数据采用flume进行采集入库
- 2、由于各个省的税务网站欠差万别,数据在爬虫下来后,需要按照不同的省份进行进行(html页面数据解析,由于每个省的税务网站不同,html不一样)。解析时,就采用了process处理。
- 3、每个省份有一套解析的代码,每个省份实现同一个底层的解析接口,解析时,通过http接口从业务系统中获取配置的解析规则。
public interface TaxCrawlerAnalysis { TaxTable analysisTaxTable(TaxHtmlTable taxHtmlTable,String taxTableType); }
- 4、每个省份的解析类同样采用动态加载的方式,在解析处理时通过省份编码的形式进行匹配。
taxCrawlerAnalysises=[{"taxCrawlerAnalysis":"com.xxx.bigdata.crawler.tax.common.analysis.TaxCrawlerPdfTableAnalysis","provinceCity":"320000"}]
四、总结
作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。本文作者:张永清 连接:https://www.cnblogs.com/laoqing/p/12620747.html
1、流水线的处理,让flume可以动态的扩展,可以支持自定义的业务处理。业务处理的代码可以作为单独的项目即插即用的集成到flume中。
2、etcd作为动态配置中心后,配置可以做到动态的更新,而不需要配置变更后,对jvm进程进行重启。
3、对flume进行改造和扩展的代码,后续都会放入个人github中。