Mybatis源码分析
一、Mybatis的使用
-
创建maven工程。
-
添加maven依赖
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.20</version>
</dependency>
- 添加配置文件mybatis.xml,内容如下:
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"//mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/aoptest"/>
<property name="username" value="xxx"/>
<property name="password" value="xxx"/>
</dataSource>
</environment>
</environments>
<mappers>
<!-- 把上面的Mapper.xml 注册进来,路径写在resources目录下的路径-->
<mapper resource="com/ybe/mapper/BookMapper.xml"/>
</mappers>
</configuration>
- 添加实体类,代码如下:
package com.ybe.entity;
public class Book {
int id;
double price;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
- 添加BookMapper接口,代码如下:
package com.ybe.mapper;
import com.ybe.entity.Book;
public interface BookMapper {
Book getBook();
}
- 添加BookMapper.xml配置文件,内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"//mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ybe.mapper.BookMapper">
<select id="getBook" resultType="com.ybe.entity.Book">
select * from book where id = 1
</select>
</mapper>
- 替换pom文件的 build节点,把resources路径下的xml文件包括在打包目录中,内容如下:
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
- App主类添加代码,使用mybaits:
//加载mybatis的配置文件
InputStream input = Book.class.getClassLoader().getResourceAsStream("mybatis.xml");
// 用建造者模式,创造 生产SqlSession的工厂(这个工厂的类型由配置文件决定)
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(input);
// 工厂生产Sqlsession
SqlSession sqlSession = factory.openSession();
Book book = sqlSession.selectOne("getBook");
System.out.println(book);
//关闭IO资源(工厂对象会自动回收)
input.close();
sqlSession.close();
二、Mybatis的初始化
- Mybatis的初始化就是创建一个SqlSessionFactory实例对象。
步骤一、先根据配置文件创建资源流,
步骤二、根据文件流解析生成SqlSessionFactory对象
-
时序图如下:
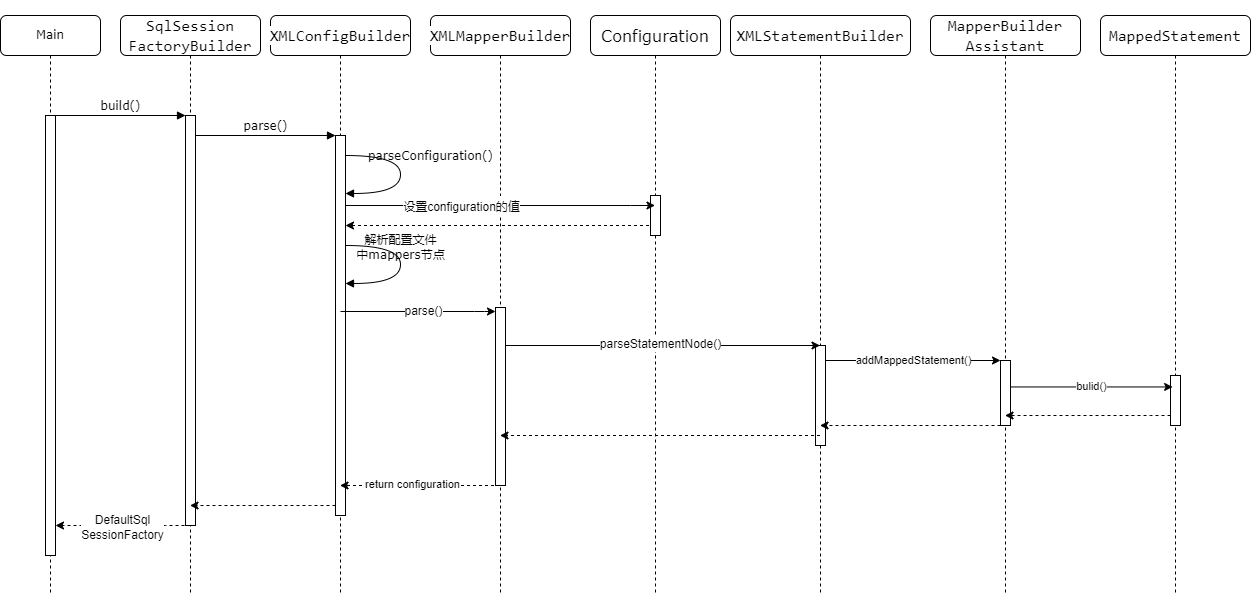
-
初始化代码如下,

InputStream input = Book.class.getClassLoader().getResourceAsStream("mybatis.xml");
// 用建造者模式,创造 生产SqlSession的工厂(这个工厂的类型由配置文件决定)
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(input);
- SqlSessionFactoryBuilder().build(input)方法的代码如下,
// 创建XMLConfigBuilder对象,该对象解析配置文件,并给configuration对象赋值。
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
// parser.parse()进行具体的解析,返回configuration实例
// build构建 SqlSessionFactory对象
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
-
其中逻辑主要是创建了一个XMLConfigBuilder实例,并进行了parse()调用,该方法返回的是Configuration实例,Configuration保存了主配置文件的所有信息,比如,数据库事务工厂、数据源对象、类型别名注册器、类型处理注册器等。Configuration实例用于对象查询中整个过程,非常重要。
-
parser.parse()方法进行具体解析,parseConfiguration()核心代码如下:
// issue #117 read properties first
// 解析 properties 内容
propertiesElement(root.evalNode("properties"));
// 解析 settings 内容
Properties settings = settingsAsProperties(root.evalNode("settings"));
//添加vfs的自定义实现,这个功能不怎么用
loadCustomVfs(settings);
loadCustomLogImpl(settings);
//配置类的别名,配置后就可以用别名来替代全限定名
//mybatis默认设置了很多别名,参考附录部分
typeAliasesElement(root.evalNode("typeAliases"));
//解析拦截器和拦截器的属性,set到 Configration的interceptorChain中
//MyBatis 允许你在已映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用
//包括:
//Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
//ParameterHandler (getParameterObject, setParameters)
//ResultSetHandler (handleResultSets, handleOutputParameters)
//StatementHandler (prepare, parameterize, batch, update, query)
pluginElement(root.evalNode("plugins"));
//Mybatis创建对象是会使用objectFactory来创建对象,一般情况下不会自己配置这个objectFactory,
// 使用系统默认的objectFactory就好了
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
//设置在setting标签中配置的配置
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
//解析环境信息,包括事物管理器和数据源,SqlSessionFactoryBuilder在解析时需要指定环境id
// ,如果不指定的话,会选择默认的环境;
//最后将这些信息set到 Configration的 Environment属性里面
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
//无论是 MyBatis 在预处理语句(PreparedStatement)中设置一个参数时,还是从结果集中取出一个值时,
// 都会用类型处理器将获取的值以合适的方式转换成 Java 类型。解析typeHandler。
typeHandlerElement(root.evalNode("typeHandlers"));
//解析mapper文件
mapperElement(root.evalNode("mappers"));
- build(Configuration config)返回DefaultSqlSessionFactory对象,代码如下,
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
- Configuration类主要属性说明:
variables:用来存放 properties 节点中解析出来的 Properties 数据。
typeAliasRegistry:用来存放 typeAliases 节点中解析出来的数据。
interceptorChain: 用来存放 plugins 节点解析出来的拦截器链。
environment: 用来存放 environments 节点解析出来的数据,比如数据库事务管理器和数据源。
typeHandlerRegistry:用来存放 typeHandlers 节点解析出来的数据。
mapperRegistry:用来注册Mapper接口 。
mappedStatements:用来存储 MappedStatement 对象,MappedStatement用来表示XXXMapper.XML文件中具体的 select|insert|update|delete节点数据 。
三、配置文件解析
Mybaits配置文件解析读取的过程是通过创建不同的XML构建器来完成的,把解析出来的数据赋值给Configuration实例的属性。
3.1 XML构造解析类
Mybatis主要构造解析类有XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder、MapperBuilderAssistant。他们有一个共同的基类BaseBuilder。
**BaseBuilder **类中有3个字段,用来存储别名注册器、类型处理器注册器、配置类。其中类型别名注册器和类型处理注册器是从configuration对象中获取的。BaseBuilder提供了根据别名获取具体的对象实例的方法以及根据java类型获取类型处理器对象的方法等。
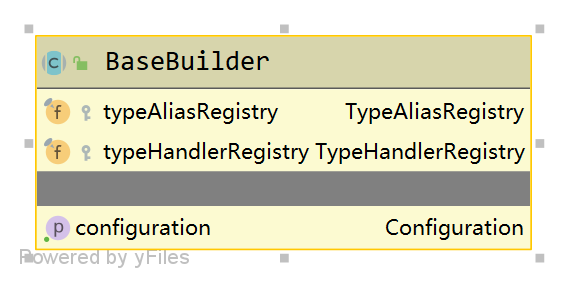
XMLConfigBuilder 主要用来构建解析主配置文件,构造方法中会创建XPathParser类,通过XPathParser 来解析和读取XML文件,XMLConfigBuilder的构造方法如下:
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
super(new Configuration());
ErrorContext.instance().resource("SQL Mapper Configuration");
this.configuration.setVariables(props);
this.parsed = false;
this.environment = environment;
this.parser = parser;
}
在构造方法中会创建了一个 Configuration的实例。在Configuration的构造方法中会进行一些别名的注册和属性的初始化,部分代码如下:
protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
protected final InterceptorChain interceptorChain = new InterceptorChain();
protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry(this);
protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();
protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry();
protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection")
.conflictMessageProducer((savedValue, targetValue) ->
". please check " + savedValue.getResource() + " and " + targetValue.getResource());
protected final Map<String, Cache> caches = new StrictMap<>("Caches collection");
protected final Map<String, ResultMap> resultMaps = new StrictMap<>("Result Maps collection");
protected final Map<String, ParameterMap> parameterMaps = new StrictMap<>("Parameter Maps collection");
protected final Map<String, KeyGenerator> keyGenerators = new StrictMap<>("Key Generators collection");
protected final Set<String> loadedResources = new HashSet<>();
protected final Map<String, XNode> sqlFragments = new StrictMap<>("XML fragments parsed from previous mappers");
public Configuration() {
typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class);
typeAliasRegistry.registerAlias("JNDI", JndiDataSourceFactory.class);
typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class);
typeAliasRegistry.registerAlias("UNPOOLED", UnpooledDataSourceFactory.class);
typeAliasRegistry.registerAlias("PERPETUAL", PerpetualCache.class);
typeAliasRegistry.registerAlias("FIFO", FifoCache.class);
typeAliasRegistry.registerAlias("LRU", LruCache.class);
typeAliasRegistry.registerAlias("SOFT", SoftCache.class);
typeAliasRegistry.registerAlias("WEAK", WeakCache.class);
typeAliasRegistry.registerAlias("DB_VENDOR", VendorDatabaseIdProvider.class);
typeAliasRegistry.registerAlias("XML", XMLLanguageDriver.class);
languageRegistry.register(RawLanguageDriver.class);
}
其中的 TypeAliasRegistry 类的构造方法中也进行了一些数据类型别名的注册,部分代码如下:
registerAlias("string", String.class);
registerAlias("byte", Byte.class);
registerAlias("long", Long.class);
registerAlias("short", Short.class);
registerAlias("int", Integer.class);
registerAlias("integer", Integer.class);
registerAlias("double", Double.class);
registerAlias("float", Float.class);
registerAlias("boolean", Boolean.class);
registerAlias("byte[]", Byte[].class);
registerAlias("long[]", Long[].class);
registerAlias("short[]", Short[].class);
registerAlias("int[]", Integer[].class);
registerAlias("integer[]", Integer[].class);
registerAlias("double[]", Double[].class);
registerAlias("float[]", Float[].class);
registerAlias("boolean[]", Boolean[].class);
XMLMapperBuilder: 主要用来解析 Mapper.XML文件的。
XMLStatementBuilder :主要用来解析 Mapper.xml 文件中 select|insert|update|delete 等语句的。
MapperBuilderAssistant :Mapper解析过程中的助手类,可以用来创建Mapper的二级缓存,添加MappedStatement等。
MappedStatement:用来存放解析 Mapper.xml 文件中的 select|insert|update|delete 节点数据。
3.2 解析过程
3.2.1environments节点解析
过程比较简单,根据environments的默认值创建environments的子节点,其中主要是创建数据库事务工厂和数据源对象,并构建Environment类,赋值给configuration实例,代码如下,
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
// 解析 default 属性值
environment = context.getStringAttribute("default");
}
// 获取子节点
for (XNode child : context.getChildren()) {
// 获取 id 属性值
String id = child.getStringAttribute("id");
// 判断 子节点的id 是否 等于 default 值
if (isSpecifiedEnvironment(id)) {
// 获取事务工厂
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
// 获取数据源工厂
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
// 获取数据源
DataSource dataSource = dsFactory.getDataSource();
// 构建 Environment 实例,赋值给configuration
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
break;
}
}
}
}
3.2.2mappers节点解析
整个解析过程中比较复杂,主要逻辑是要解析具体的mapper文件或者mapper接口。关键业务实现在XMLConfigBuilder.mapperElement()方法中。根据mappers的子节点的name值和属性来执行不同的方法。
一、如果为mappers子节点是以 package 开头则调用
configuration.addMappers(mapperPackage);
public void addMappers(String packageName) {
mapperRegistry.addMappers(packageName);
}
MapperRegistry类中方法如下:
public void addMappers(String packageName) {
addMappers(packageName, Object.class);
}
public void addMappers(String packageName, Class<?> superType) {
//创建解析类
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
// 找到 package 路径下所有继承 superType的类, 并且放入 matches 属性当中
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
// 获取所有 matches 的值
Set<Class<? extends Class<?>>> mapperSet = resolverUtil.getClasses();
for (Class<?> mapperClass : mapperSet) {
// 添加 具体的 映射类
addMapper(mapperClass);
}
}
public <T> void addMapper(Class<T> type) {
// 必须是接口类型才能添加成功
if (type.isInterface()) {
// 如果该类型以及添加,则抛异常
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// 添加type 类型的代理工程对象 到 knownMappers 对象中。
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
//创建 mapper 注解解析类
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
二、如果为mappers子节点是以 mapper 开头并且属性为 class 则调用
configuration.addMapper(mapperInterface);
1. 这上面两种方式,都会调用类MapperAnnotationBuilder的parse()方法进行Mapper文件或者Mapper接口的解析,代码如下,
public void parse() {
String resource = type.toString();
// 判断资源是否已经添加过
if (!configuration.isResourceLoaded(resource)) {
// 加载 mapperxml 文件
loadXmlResource();
//添加 已经加载的资源
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
// 解析二级缓存
parseCache();
// 解析缓存引用
parseCacheRef();
// 遍历mapper 接口的 方法
for (Method method : type.getMethods()) {
if (!canHaveStatement(method)) {
continue;
}
// 解析 ResultMap
if (getAnnotationWrapper(method, false, Select.class, SelectProvider.class).isPresent()
&& method.getAnnotation(ResultMap.class) == null) {
parseResultMap(method);
}
try {
// 解析具体的sql语句
parseStatement(method);
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
- loadXmlResource()方法是进行Mapper.Xml文件解析,parseStatement()方法则是进行Mapper接口的解析。这里主要讲解mapper.xml文件解析,loadXmlResource中主要逻辑为:找到资源文件流,创建XMLMapperBuilder实例,调用其parse()方法进行MapperXML文件的解析,主要代码如下,
// 通过文件流创建 XMLMapper 解析对象,
XMLMapperBuilder xmlParser = new XMLMapperBuilder(inputStream, assistant.getConfiguration(), xmlResource, configuration.getSqlFragments(), type.getName());
// 进行具体解析
xmlParser.parse();
- XMLMapperBuilder.parse()解析Mapper文件的mapper节点,代码如下:
// 判断 资源 是否加载过
if (!configuration.isResourceLoaded(resource)) {
// 解析 具体的 mapper.xml 文件
configurationElement(parser.evalNode("/mapper"));
// 设置为已经加载过的 资源
configuration.addLoadedResource(resource);
// 绑定该资源的 Mapper接口到 configuration 中
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
- configurationElement()为具体解析 mapper节点的方法,其中会解析 mapper中的namespace、cache、parameterMap、resultMap、sql、select|insert|update|delete,代码如下:
private void configurationElement(XNode context) {
try {
// 获取节点的 namespace 值
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.isEmpty()) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 设置助手类的 CurrentNamespace,即 mapper.xml 文件中的 namespace 值
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
// 解析 mapper 的 parameterMap
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析 mapper 的 resultMap
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析 sql 片段
sqlElement(context.evalNodes("/mapper/sql"));
// 解析 select|insert|update|delete
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
- buildStatementFromContext()方法用来解析mapper文件中 select|insert|update|delete 节点,代码如下,
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
// 创建 XMLStatementBuilder 类
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
// 解析 具体的 select|insert|update|delete 节点
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
- XMLStatementBuilder.parseStatementNode()方法为实际解析select|insert|update|delete 节点的方法,主要逻辑为从节点中获取相关参数构建MapperStatement对象,调用builderAssistant.addMappedStatement方法把MapperStatement添加到configuration.mappedStatements集合中去。部分代码如下,
// 获取节点名称
String nodeName = context.getNode().getNodeName();
// 节点名称就是数据命令名称
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
// 判断是否是 SELECT 命令
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// 设置是否刷新缓存
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
// 设置是否用缓存
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
// 获取自定义sql脚本语言驱动 默认 为 XMLLanguageDriver
LanguageDriver langDriver = getLanguageDriver(lang);
// 通过 XMLLanguageDriver 来解析我们的sql 脚本对象,解析 SqlNode ,
// 注意,只是解析成一个个的SqlNode,并不会完全解析sql,因为这个
// 时候参数都没确定,动态sql无法解析
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
// 获取 StatementType 类型
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 构建 MappedStatement 对象,添加到configuration.mappedStatements集合中去
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
- langDriver.createSqlSource(configuration, context, parameterTypeClass),具体的Sql语句被解析构造为了实现了SqlSource接口的类。这些实现类通过SqlNode节点来记录具体的Sql语句、参数类型、configuration对象。此过程只是根据配置的Sql语句生成具体的SqlNode对象,以便后面在执行sql语句的时候进行解析。
- builderAssistant.addMappedStatement();构建MappedStatement类里面主要存放了 statementLog日志对象、,添加到configuration实例的mappedStatements集合中去。集合key值为 mapper文件的 namaspace值 + id 值。
三、如果为mappers子节点是以 mapper 开头并且属性为 resouce 或者 url 则调用
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
#具体解析过程请看上面讲解
mapperParser.parse();
四、Mybatis的使用
使用分为两步,第一步获取SqlSession对象,第二步调用SqlSession对象具体方法。
4.1 获取SqlSession对象
通过factory.openSession()获取DefaultSqlSession实例。主要逻辑为,先从configuration对象中获取 environment环境变量、Executor执行器对象,然后从环境变量中创建事务对象,最后构建DefaultSqlSession对象实例。代码如下,
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
// 获取 环境对象
final Environment environment = configuration.getEnvironment();
// 获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 创建事务
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 获取 executor
final Executor executor = configuration.newExecutor(tx, execType);
// 构造 DefaultSqlSession
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
configuration.newExecutor(tx, execType),根据事务对象和执行器类型创建执行器,执行器有三种类型SIMPLE(简单), REUSE(可复用), BATCH(批量)。默认为SIMPLE。如果开启cacheEnabled(二级缓存),则会创建CachingExecutor对象实例包装SimpleExecutor实例。cacheEnabled默认是true。然后判断是否有拦截器进行代理,如果有会创建CachingExecutor实例的代理类。代码如下,
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 是否开启缓存,默认开启二级缓存
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 获取拦截器的代理
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
4.2 根据id调用SqlSession具体的方法
执行sqlSession.selectOne(“getBook”)语句来获取 Book对象实例。selectOne其实内部调用的是SelectList。主要逻辑:先通过statment的id获取configuration中的MappedStatement实例,再调用执行器的query方法进行查询,并返回。代码如下,
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
// 根据 id 获取 MappedStatement类
MappedStatement ms = configuration.getMappedStatement(statement);
// 调用执行器执行查询语句,并返回对象实例
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
executor.query 是执行的 CachingExecutor的query方法。主要逻辑:先通过 调用 实例获取ms.getBoundSql()方法获取 BondSql实例,BondSql中有具体的sql语句、传入的参数对象。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 解析获取 SqlSource 实现类,获取BoundSql, BoundSql里面存储了 解析之后的sql语句 ,参数对象
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建缓存key (命名空间id + sql语句 + 参数值 + 环境变量id)
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 进行查询
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
createCacheKey(ms, parameterObject, rowBounds, boundSql),创建缓存的key,key的规则为(命名空间id + sql语句 + 参数值 + 环境变量id)。query()方法主体逻辑为:先获取MappedStatement实例中的缓存,如果缓存存则获取key的对象,代码如下,
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取二级缓存
Cache cache = ms.getCache();
// 如果有二级缓存
if (cache != null) {
flushCacheIfRequired(ms);
// 如果是查询,并且 resultHandler 为null
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从 TransactionalCacheManager 中获取 key的 缓存对象
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 调用代理执行器(默认为 SimpleExecutor)
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql),调用代理执行器(默认为 SimpleExecutor)的query方法,具体执行的是BaseExecutor.query方法,此方法的主要逻辑为:先从本地缓存中获取key的对象,如果缓存存在即返回该对象,如果缓存不存在则调用queryFromDatabase()方法走数据库查询。代码如下,
queryStack++;
// 从一级缓存中拿数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 如果没有则走数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
queryFromDatabase()的关键逻辑为,先执行sql语句拿到具体的对象实例,再把返回结果存入本地缓存,最终返回执行结果。代码如下,
// 具体的查询语句
doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
// 把数据存入一级缓存
localCache.putObject(key, list);
return list;
doQuery()方法中执行数据库sql,并且将数据库结果集转成具体的对象实例。主要逻辑为:通过 MappedStatement 获取configuration对象,然后configuration创建 StatementHandler的实例,默认值为PreparedStatementHandler类型的实例。再通过prepareStatement方法对Statement对象进行初始化 。最后通过调用StatementHandler的query方法,返回对象实例。代码如下,
// 获取 configuration 实例
Configuration configuration = ms.getConfiguration();
// 创建 StatementHandler 实例
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 初始化 Statement 对象
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行 Statement,并且处理结果集
return handler.query(stmt, resultHandler);
handler.query(stmt, resultHandler),会调用PreparedStatementHandler的query方法, 主体逻辑执行statement.execute拿到结果集,再通过结果处理器将数据库结果集转成对象实例,最终返回。
// 转成 PreparedStatement
PreparedStatement ps = (PreparedStatement) statement;
// 执行sql,拿到结果
ps.execute();
// 结果处理器处理数据库结果集
// 最终会返回实体对象
return resultSetHandler.handleResultSets(ps);
resultSetHandler.handleResultSets(ps)方法主要是转换查询出的数据库结果集为配置的对象实例,最终返回对象实例。代码如下,
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 获取 数据库结果集的包装类 ResultSetWrapper
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 获取返回结果Map对象
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// 判断 rsw 结果集不为空 ,并且 mappedStatement的 resultMapCount 数量 小于 1
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
// 获取结果 Map 对象
ResultMap resultMap = resultMaps.get(resultSetCount);
// 处理结果集,集体返回结果存在 multipleResults 中
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个结果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
//获取返回结果Set对象
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
// 返回结果
return collapseSingleResultList(multipleResults);
}
handleResultSet(rsw, resultMap, multipleResults, null)方法,封装了处理数据库结果集的具体逻辑,源码里面逻辑比较复杂,大概逻辑:利用反射创建需要返回的对象实例,再根据数据库结果集以及相关配置,把数据库结果集的数据赋值给反射创建对象的属性。并且把结果添加在multipleResults实例中。整个过程至此完结。
说明:通过SqlSession获取Mapper接口,再调用Mapper接口的方法执行SQL。其实是先通过JKD生成代理类,底层也是用的根据id调用SqlSession方法的逻辑,和上面讲解的一样。这里不做讲解。
五、缓存
1.一级缓存
结论:一级缓存可以理解为同一个SqlSession的缓存。一级缓存默认开启。开启后,在同一个SqlSession中用相同参数值多次调用同一方法,只会查询一次数据库,返回对象实例的内存地址相同,对象实例属性也相同。
源码分析:在BaseExecutor类中localCache属性表示一级缓存,它类型为PerpetualCache,底层是一个HashMap对象,用来缓存查询结果对象。缓存的 key 是在createCacheKey()方法中创建,key的规则为(命名空间id + sql语句 + 参数值 + 环境变量id),在BaseExecutor类中query方法里面有localCache.getObject(key),表示从缓存中获取对象。queryFromDatabase方法中的localCache.putObject(key, list),表示把查出来的对象实例放进key的缓存中。
2.二级缓存
结论:二级缓存可以理解为Mapper文件的缓存,多个SqlSession之间的缓存。二级缓存默认不开启。开启后,在不同的SqlSession中用相同参数值按照同步顺序多次调用同一个方法,(每次用完SqlSession需要调用SqlSession的close()关闭SqlSession),只会查询一次数据库,返回对象实例的内存地址不相同,对象实例属性相同。开启二级缓存需要对象支持序列化。
源码分析:
2.1二级缓存的创建
org.apache.ibatis.builder.xml.XMLMapperBuilder#configurationElement中调用cacheElement()方法,源码如下
private void cacheElement(XNode context) {
// 如果节点不为null,则创建二级缓存
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
// 创建新缓存
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
useNewCache()方法是创建缓存的具体方法,其中创建了一个缓存类,并且给currentCache赋值。代码如下
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
//
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
//给配置文件添加二级缓存类
configuration.addCache(cache);
//给 currentCache 赋值
currentCache = cache;
return cache;
}
在 org.apache.ibatis.builder.MapperBuilderAssistant#addMappedStatement()方法中构建MapperStatement的时候,会把二级缓存对象传进去,代码如下:
MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
.resource(resource)
.fetchSize(fetchSize)
.timeout(timeout)
.statementType(statementType)
.keyGenerator(keyGenerator)
.keyProperty(keyProperty)
.keyColumn(keyColumn)
.databaseId(databaseId)
.lang(lang)
.resultOrdered(resultOrdered)
.resultSets(resultSets)
.resultMaps(getStatementResultMaps(resultMap, resultType, id))
.resultSetType(resultSetType)
.flushCacheRequired(valueOrDefault(flushCache, !isSelect))
.useCache(valueOrDefault(useCache, isSelect))
//赋值二级缓存
.cache(currentCache);
至此,二级缓存对象被初始化在了MappedStatement 对象中。
2.2二级缓存使用
在 org.apache.ibatis.executor.CachingExecutor#query()方法中会先查询缓存,如果缓存对象不为空,则判断是否使用缓存,再从TransactionalCacheManager对象中获取缓存数据。代码如下,
// 获取二级缓存
Cache cache = ms.getCache();
// 如果有二级缓存
if (cache != null) {
flushCacheIfRequired(ms);
// 如果是查询,并且 resultHandler 为null
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从 TransactionalCacheManager 中获取 key的 缓存对象
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 继续查询缓存对象
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 放入缓存管理对象中,这里只是放入tcm的 临时集合对象中,二级缓存具体的更新是在session关闭之后才会提交更新
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
tcm.putObject(cache, key, list);放入缓存管理对象中,这里只是放入tcm的 临时集合对象中,二级缓存具体的更新是在session关闭之后才会提交更新,putObject的代码如下,
@Override
public void putObject(Object key, Object object) {
//放入临时集合中,保存缓存的数据
entriesToAddOnCommit.put(key, object);
}
session.close()方法代码会调用executor.close方法进行执行器的关闭,executor.close代码如下
@Override
public void close(boolean forceRollback) {
try {
// issues #499, #524 and #573
if (forceRollback) {
tcm.rollback();
} else {
tcm.commit();
}
} finally {
delegate.close(forceRollback);
}
}
tcm.commit()方法中,会调用tcm缓存管理器中所有缓存对象的commit的方法,代码如下
public void commit() {
// 遍历 transactionalCaches 对象的 values 进行提交
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
transactionalCaches的commit的方法代码如下,
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
// 刷新 缓存中的待刷新的缓存数据
flushPendingEntries();
reset();
}
private void flushPendingEntries()
// 提交entriesToAddOnCommit集合的数据到二级缓存代对象
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}


