CMU 15-445 数据库课程第四课文字版 – 存储2
- 2022 年 5 月 27 日
- 筆記
- CMU 15-445, MySQL, 数据库
熟肉视频地址:
1. 面向日志的存储
上节课我们讲完了面向元组的存储,这节课从面向日志的存储设计开始。
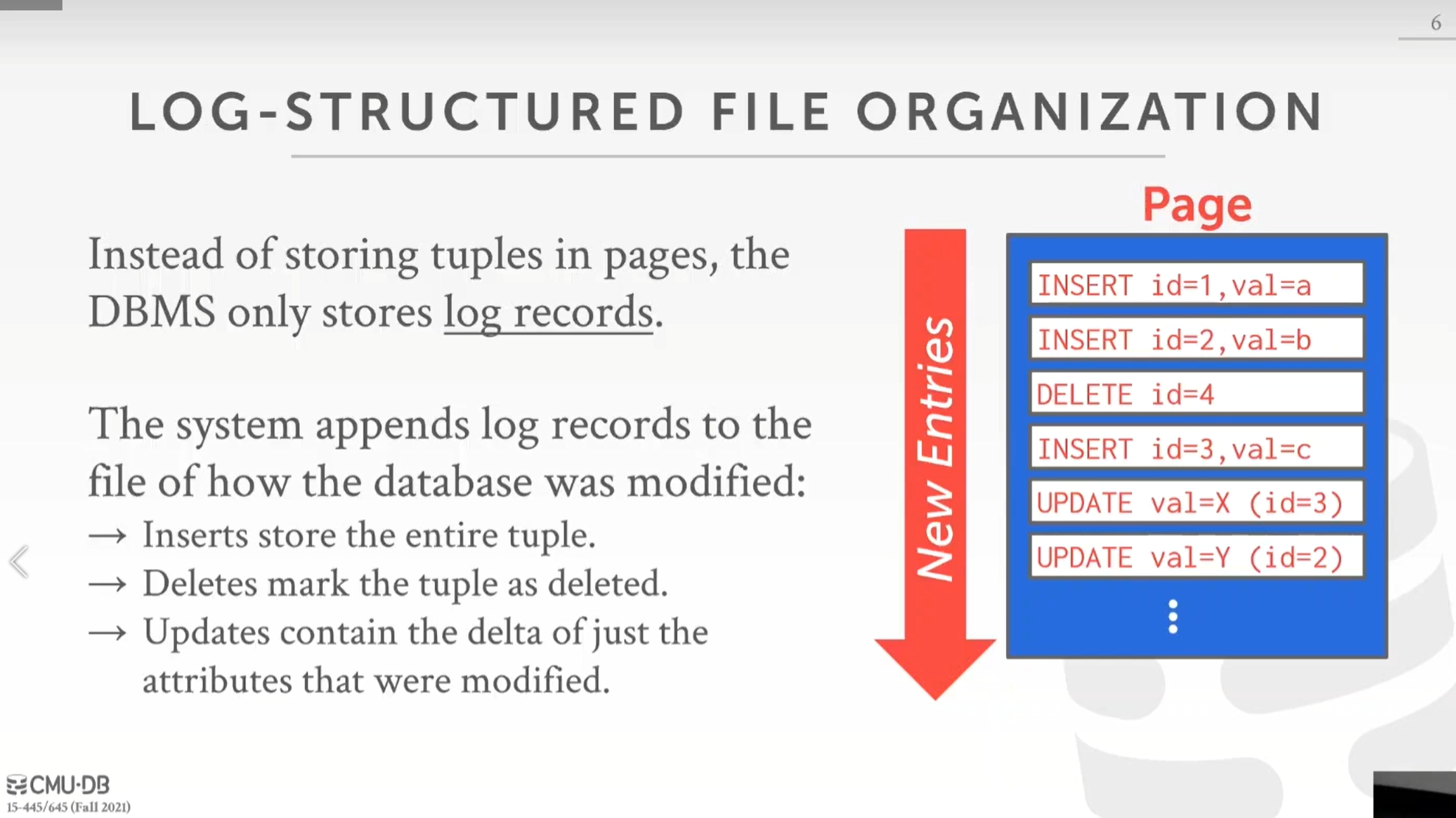
在这里,页中不存储元组数据,只会存储日志记录,即通过日志记录我们插入的数据以及我们如何更新系统中的数据,包括:插入元组的语句日志,删除元组的语句日志,更新元组的语句日志。
这种设计写得很快,因为不用在一个页里寻找并更新单个元组,就是在末尾追加写,这样写起来非常快,对于磁盘 I/O 也很好。

但是对于读取,就很麻烦了。为了读取一条记录,我们要做的就是从后向前扫描这个日志,以便重新创建我们想要查询的元组。
当然我们可以做一些优化,比如我们可以建立一个索引,用来找到应用于每个元组的不同日志记录,这样我们就不需要对所有的日志记录进行完整的扫描。但是这带来了而外的元数据存储消耗。

另一种优化方式就是定期压缩这些日志,基本上只是把所有的日志记录压缩成单个值,过程是:获取页的锁并锁定,然后执行压缩,然后释放锁。让我们更深入地讨论一下压缩是如何进行的:

首先是层级压缩(level compaction)的:从顶层开始是第 0 级,我们有这个按照执行顺序排好序的日志文件,它在不断积累,随着时间积累了所有这些页。我们要做的是做一个周期性的压缩,即当第 0 级有两页被填满的时候,将它们里面的记录做归并排序,并压缩到一个更大的文件中并放到下一级,即第 1 级。之后更多的日志文件会在顶层第 0 级建立,我们只是不断重复这个过程,第 1 级有两页满了的就归并排序压缩成为一个新的放入第 2 级,依次类推。
另一种是全体压缩(universal compaction)的:即没有等级概念,只是合并归并压缩相邻的页文件。
数据格式(Data Representation)
如果我们在页面中有一个单独的元组,我们如何存储它,如何解释存储在里面的数据,以及 DBMS 的其他层如何利用或从元组存储中提取它们需要的数据。

元组本质上就是一个字节序列,DBMS 目录中会包含表的模式信息,通过这个模式信息可以解析出元组中的数据。

元组内的数据属性可以有不同的类型,一般常见的类型包括:
- 整数类型:有不同的大小的整数,在 SQL 标准中是基于它们支持的值范围定义的,一般有 BIGINT/SMALLINT/TINYINT/INTEGER 等等
- 浮点数类型或者小数类型:一种是基于 IEEE-754 标准定义的近似浮点值,还有就是固定小数点的小数,一般有 FLOAT/REAL,以及 NUMERIC/DECIMAL 等等。
- 变长类型:这种数据类型并非固定长度,所以带有头部标识数据长度,之后跟着实际数据,比如 VARCHAR/VARBINARY/TEXT/BLOB
- 时间类型:一般通过计算与 Unix Epoch(1970-01-01 00:00:00 UTC)时间经过的时间长度(单位为毫秒或者秒),保存在一个 32 位或者 64 为的整数类型中存储。


这里最棘手的是浮点小数或者任意精度的小数的处理。
对于小数精度不确认的小数,例如不限制计算结果的数字的小数位数这种情况,由于精度是不确认的,所以很难通过一些计算机结构表示出来,例如 C/C++ 中对应的 FLOAT 和 DOUBLE/REAL 等类型,他们是通过 IEEE-754 标准去近似逼近实际存储的小数:
- 最高位 bit 表示符号位(0x8000000000000000)
- 第二到第十二的 bit 表示指数(0x7ff0000000000000)
- 剩下的 bit 表示浮点数真正的数字(0x000fffffffffffffL)
举个例子,78.5 这个数字,对于 double,实际存储的就是:40 53 a0 00 00 00 00 00,转换成二进制:01000000 01010011 10100000 00000000 00000000 00000000 00000000 00000000,符号位:0,指数位10000000101 = 1029,减去阶数 1023 = 实际指数 6,小数部分0.0011101000000000000000000000000000000000000000000000,转换为十进制为0.125 + 0.0625 + 0.03125 + 0.0078125 = 0.2265625, 加上隐含数字 1 为 1.2265625, 之后乘以 2 的 6 次方就是 1.2265625 * 64 = 78.5
double 使用的位数比较多,所以逼近的误差更小一些,float 使用的位数比较少,可能的误差就会大一些。

这里使用一个指定精度显示的程序展示了这种 IEEE-754 标准逼近带来的可能的误差。
如果你是在不需要那么精确的场景,那么可以使用这种 IEEE-754 标准逼近的近似小数,如果你需要很精确的场景,那么就不要用这种了。你就需要使用固定精度的数字类型(Numeric Type)

可以在给数字类型设置一个任意的精度和位数,这些东西在实际系统中如何工作有很多不同的实现。一般来说,商业版的数据库要复杂得多,因为他们知道商业应用对固定精度的数值有很大的需求。但是这里需要权衡,因为你需要的精确度越高会在你的处理过程中需要更多的开销。
postgres 是这样实现其数字数据类型:

这个结构体包括:
int ndigits: 包含数字的个数int weight:第一个数字的权重,实际的数字由第一个数字乘以这个权重组成int scale:放大系数int sign:符号,是正是负还是空NumericDigit *digits:是一个字符数组,保存所有的数字
MySQL 的存储结构也是类似的:

这个结构体包括:
int intg: 小数点前的数字个数int frac:小数点后面的数字个数int len:数字占用字节长度bool sign:符号,是正是负decimal_digit_t *buf:是一个 int32 数组,保存所有的数字
大多数系统不允许元组超过单个页的大小,所以它要么受列的大小限制要么受列的个数限制,或者两者都受限制,所以基本不能指定一个大于一页大小的元组。但是如果元组的某个值大于一页大小怎么办?例如一个某个元组有个值是 VARCHAR 类型,保存了很长的字符串,那么我们不会把所有数据和元组其他数据放在一起,而是把它存储在溢出页中。

假设元组的 c 属性是一个 VARCHAR 类型并且保存的值很大,那么元组内在 c 的位置会保存一个指针,它会指向存储在溢出页中的 varchar 数据。溢出页可能一页存不下,不止一页大小,所以会是一个页链表。这在不同的系统中有不同的叫法:
- postgres 称它为 toast,如果大于2KB,溢出页就会出现
- MySQL:大于页大小的一半就会出现溢出页
- SQL Server:大于页大小才会出现溢出页
除了溢出页还有另一种方式即存储为外部文件

某些 DBMS 允许你将这种大值存储到外部的文件中,以 BLOB 的方式处理这个数据,例如:
- Oracle: BFILE 数据类型
- Microsoft:FILESTREAM 数据类型
我们一般不不适合存储进数据库的大数据放入外部文件存储,例如视频、图片等等。我们只是存储了一个指向数据的指针,实际指向的数据位于文件系统的其他地方,我们可以在需要的时候引用它。
但是这样就丧失了 DBMS 对其的管理特性,例如不能保证外部是否有修改或者删除这个外部文件,不能保证事务性修改等等。
对于非不适合放入数据库存储的那种大数据,比如大 JSON 等等,Jim Gray 曾经有一篇论文研究,评估数据大小对于是直接在溢出页面内存储blob好,还是在外部存储blob更好的影响,这是一篇 15 年前的论文,这篇论文得出的结论是,他们得出的结论是256KB的大小在外部存储更有利,现在这个数字可能变得更大了。但是我们要记住,如果它存储在DBMS中,我们每次都要把这些巨大的对象通过很多页写入和从磁盘中读取,这是我们要考虑的权衡。
3. 系统目录(System Catalog)

我们接下来要讲的是系统级别的目录,DBMS 需要在内部保存所有关于数据库的元数据以便于他能需要知道如何编码和解码存储在代表元组的字节中的数据。一般存储关于表,列,索引,视图的结构信息,诸如此类的结构信息。DBMS 通常还存储有关用户和权限的信息,就像访问权限,即用户应该能够查看或修改哪些数据。最后,DBMS 还存储了大量的内部统计数据,比如不同值的数量,或者连接基数,或者数据范围之类的,这些是构建查询计划,查询执行中非常重要的。
大部分的 DBMS 都将数据库存储为目录类型的结构,前面我们说过,在这个系统目录中也会存储关于表,列,索引,视图的结构信息,这些结构信息也像普通的表一样存储。那么现在就有了鸡生蛋蛋生鸡的问题,我们需要这些结构信息解析读取表数据,但是这些信息也以表的形式存储。所以一般的设计是它们有这些特殊的元数据对象包装器,系统可以用来直接编码和解码存储在系统目录中的值。

用户可以查询 DBMS 的这个内部目录,它通常存储在这个 INFORMATION_SCHEMA 中,以获取关于数据库的信息以及各种统计信息等等。这被 ANSI 标准定义为只读视图的集合,在它标准化之前,这曾经很混乱,每个系统都有自己的方式来暴露这些元数据。现在有了这个标准,大家都可以通过访问 INFORMATION_SCHEMA 来访问这些信息。不过不同的系统还是暴露了其他的一些等价的快捷方式命令访问这些信息,比如:

这是列出某个数据库中所有表的命令:
- SQL-92 标准中是:
select * from information_schema.tables - Postgres 中是:
\d - MySQL 中是:
show tables - sqlite 中是:
.tables

这是查看某个表的详细信息的命令:
- SQL-92 标准中是:
select * from information_schema.tables where table_name = 'student' - Postgres 中是:
\d student - MySQL 中是:
DESCRIBE student - sqlite 中是:
.schema student
4. 数据库工作负载类型(Database Workload)

我们主要有三种不同类型的数据库工作负载:
- 第一个是在线事务处理,简称 OLTP(Online Transaction Processing):这意味着你有很多快速短小的运行操作,即每次只读取或更新一小部分数据。例如你的银行账户场景,比如你想要得到你银行账户的余额,你只是读取一个值,或者如果你想做一笔交易,比如存款,这是一笔相当短的交易。还有就是像亚马逊这样的网上商店,你浏览不同的产品把它们加到你的购物车结账付运费,你访问的数据量相对于亚马逊提供的所有产品来说是相对较小的,但是如果你思考下世界上有很多同时购物的人,这就积少成多了,即各个事务访问或修改的数据量积少成多了。
- 第二个是在线分析处理,简称 OLAP(Online Analytical Processing):这些有点像分析查询,读取大量的数据,扫描表的大部分,会产生聚合,有很多表之间的连接,通常用于决策支持或商业智能。同样是亚马逊的例子,比如亚马逊想知道在过去的一个月里,CMU 学生购买最多的五个商品是什么。这种查询需要扫描一个大的样本,而不仅仅是更新单个或读取单个记录。
- 最后一个是最近越来越流行的混合事务和分析处理,简称 HTAP(Hybrid Transaction and Analytical Processing):目标是能够把 OLTP 和 OLAP 放在同一个数据库实例上,事务处理和分析同时运行,这样能够得到关于交易数据更快或更实时的见解。

这个坐标图可能更直观些,X 轴是从写多读少到读多写少,Y 轴是请求复杂度,从简答到复杂。OLTP 的工作负载更多的是写多一些并且比较简单的请求,OLAP 的工作负载更多的是读多一些并且比较复杂的请求,HTAP 介于两者之间。

在实际使用中,一般公司会建立 OLAP 与 OLTP 独立的环境:因此,在一端你通常会有多个 OLTP 数据筒仓,这里做所有的在线业务请求;另一端非常大的 OLAP 数据仓库,你要在数据仓库转储所有的数据筒仓的数据以供分析。我们需要从数据筒仓到数据仓库的数据传输,主要通过这个 ETL(Extract Transform Load,提取、转换、加载)过程:我们从这些不同的数据筒仓中提取所有的数据,这些数据格式可能与我们最终需要的数据格式有差异,所以我们需要转换这些数据,并且对数据做一些处理,比如合并,删除重复等等,最后加载到数据仓库中。还有一些数据分析的结果需要从数据仓库传回数据筒仓中,例如一些产品推荐信息,在你访问商品网页时为你推荐的产品。HTAP 的思想就是让这些事务工作与查询工作一起并发执行,并省略很多中间的同步操作。

为什么区分不同类型的工作负载很重要?回顾一下关系模型,它为我们对数据进行不同操作提供了一定的规则和要求,但它并没有告诉我们在物理上我们需要如何存储数据。我们需要根据我们的业务即工作负载的类型,来决定我们的数据如何存储。我们前面主要讲的主要是基于行的存储,即某一个元组的所有属性的数据都紧密的保存在一起。但是这种设计并不适用所有的场景,我们来看一个维基百科的例子:

我们有有一个 useracct 表,也就是维基百科的用户,它包含 userId 和 userName;然后有 pages 表,存储了维基百科数据;然后有 revisions 表,它说明哪个用户对哪个页面进行了哪些编辑或修订。同时,userId 指向 useracct 表,pageId 指向 pages 表,其中 pages 表的 revId 指向 revisions 表。
对于维基百科 OLTP 业务场景举几个例子,这些场景都只会修改或者查询表中很少的数据:
- 查询某一个维基百科词条,这样就是查询 pages 以及 revisions 表。
- 比如可能是用户每次登陆的时候更新用户记录
- 获取用户上次登录时更新的词条数据
- 修改词条,即修改 pages 表以及添加一个新的记录到 revisions 表中。这些是运行时间很短的简单操作,只在数据库中读取或写入一些值。
对于维基百科 OLAP 业务场景的一个例子是查看上个月来自于 .gov 的用户不同登陆次数,这种就会扫描表中的大部分数据。

我们引入存储模型的概念,第一种是基于行的存储模型,这就是所谓的n元存储模型(N-ary Storage Model),在一个页中存储基于行的数据,所有东西都像一个字节数组,所有东西都是连续存储的。这种格式对于 OLTP 业务请求更加友好,因为查询倾向于操作单个记录或者行这个行的所有数据是存储在一起的,如果不考虑溢出页的话就都在一页,也就是大部分请求每个都只会操作一页。

使用前面维基百科的 OLTP 例子,例如用户登录需要查询单个用户,这个请求会走索引(索引在后面的课堂中会讲到,在第七讲),索引会告诉我们去哪个页的哪个槽去获取这个用户元组的位置,读取槽获取到用户元组位与页中的位置,然后就能读取到这个用户元组的所有信息。同时注册新用户需要插入记录,这个插入也只会放在一页上,并且用户所有值都在一起。

但是这种存储不太适合 OLAP 的场景,还是用前面提到的维基百科的例子,查看上个月来自于 .gov 的用户不同登陆次数,这个查询不能走索引,我们需要遍历这个表的所有页,过滤 hostname 是.gov的以及 lastlogin 是上个月的,然后统计 lastlogin 字段,也就是我们其实只需要 hostname 和 lastlogin 这两个字段的值,但是实际我们却加载并解析了整个元组的所有属性值。这些带来了首先是磁盘 I/O 的浪费,以及对于解析整个元组数据带来的额外的内存与 CPU 消耗。

我们总结下 n 元存储模型的优缺点:
- 优点:
- 元组的增删改查很快
- 适合需要查询整个元组数据的查询
- 缺点:
- 很不适合要扫描表中大部分数据,并且查询的只是元组属性的子集的场景


第二种是基于列的存储模型,这就是所谓的分解存储模型或 DSM(Decomposition Storage Model),即将一个元组的单一属性的值于一个页面中连续存储,而不是连续地存储单个元组的所有不同属性值。我们将提取所有的元组这个列值并将他们连续存储,这也是”列存储”这个名字的来源。这对于有很多只读查询的 OLAP 工作负载非常理想,一般这种查询需要分析大部分行的某些属性值,如果我们把同一属性的值放在一起,我们就不用扫描查询中用不到的属性,并且同一属性的值在一起这样对于某个属性运行聚合函数窗口函数就会效率更高。

我们回到前面提到的维基百科的 OLAP 例子,查看上个月来自于 .gov 的用户不同登陆次数,这个查询我们只需要hostname和lastLogin,我们不需要表格中的任何其他属性,所以我们现在就可以找到对应于这两个列的页,减少了要扫描的数据消耗。
但是对于那种需要返回元组所有属性的请求,比如要查询某一个元组的所有属性,需要查询每个属性的所在的页,然后汇总返回。那么如何从每个属性所在的页找到这个元组对应的数据呢?

可以有两种方式:
- 固定长度的偏移量:因为每个列值都是相同的类型,对于固定长度字段,我们直接通过长度乘以个数就能得到对应数据的位置偏移。但是如果对于可变长度的字段,例如可变长度的字符串,可以通过一些方式转换成固定长度的字段,例如将字符串填充拉长到特定的长度,或者进行编码使用长度的整数代码替换字符串,这个在之后的课程会详细讨论。这种方式虽然占用空间小实现简单,但是对于变长字段实现比较麻烦并且会有空间浪费等问题。
- 另一种选择是存储元组的id直接嵌入到列中:一般这些列还是通过某种排序规则排序的,我们可以通过二分查找来找到对应 id 的数据。

我们总结下 DSM 存储模型的优缺点:
- 优点:
- 减少了I/O浪费,因为只读取查询所需的列中的数据
- 对于实际存储的列,您可以得到更好的查询处理和压缩(后面课程还会详细讨论这个,同一种类型的数据放在一起更好压缩,例如我们存储的是日期,那么我们不用每一个值都存储日期,而是第一个存储日期,之后的存储与第一个日期的相对日期)
- 缺点:
- 如果你想去重建一个单独的元组的所有数据,那么就比较慢
- 要做插入更新之类的事情要困难得多,因为你现在需要在多列多页中添加值而不是一次写完

DSM 系统并不是新的设计,它们已经存在了一段时间,第一个是在20世纪70年代发布的 Cantor,它实际上不像DBMS,而是像一个文件系统。在20世纪80年代,有了第一个关于DSM存储的理论基础或提议。在20世纪90年代,有一种产品叫做SybaseIQ,它就像Sybase这个行存储的内存加速器,可惜并不流行。他们所做的是将数据以列存储形式在内存中,以加速某些类型的查询。在21世纪初到中期,这三个系统开始流行,Vertica, VectorWise 和 MonetDB,他们是第一个受欢迎的,商业上成功的列存储,为很多目前很常见的列存储技术铺平了道路。从 2010 以后,基本所有人都会用到基于 DSM 的系统了。

总结一下,虽然课程开始的时候一直在说DBMS是由这些独立的部分组成的技术栈,但其实并不是完全独立的,比如这里,为目标工作负载选择正确的存储模型非常重要,对于 OLTP 你想要行存储,OLAP 需要列存储。
微信搜索“干货满满张哈希”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:



