transformers—BERT
transformers—BERT
BERT模型主要包括两个部分,encoder和decoder,encoder可以理解为一个加强版的word2vec模型,以下是对于encoder部分的内容
预训练任务
- MLM任务
MLM任务通过单词表示来表示上下文关系 - NSP任务
NSP任务通过句子向量表示句间的关系
1. BERT模型的输入
- wordpiece embedding 单词向量
- position embedding 位置编码向量
两种生成方式:- 相对位置编码
\[PE_{(pos,2i)}=sin(\frac{pos}{10000^{\frac{2i}{model}}})
\]\[PE_{(pos,2i+1)}=cos(\frac{pos}{10000^{\frac{2i}{model}}})
\] - 通过模型学习生成
- 相对位置编码
- segment embedding 区分文中的上下句,应用在问答匹配中
2. self-attention
-
句子向量
\(\downarrow \ \ \ \ \downarrow\) -
Input Embedding + Position Embedding
\(\downarrow\) -
\[X_{embedding}\in R^{batch size\ *\ seq len\ *\ embed dim}
\]\(\downarrow\) 线性映射(学到多重含义,分配三个权重(\(W_Q,W_k,W_v\))
-
\(Q=Linear(X_{embedding})=X_{embedding}W_Q\)
\(K=Linear(K_{embedding})=K_{embedding}W_K\)
\(V=Linear(V_{embedding})=V_{embedding}W_V\)
\(\downarrow\) multi head atention(\(head size=embed dim/head size\)) -
\(Q,K,V \rightarrow[batch size,seq len,head size,embed dim/h\)
\((Q,K,V)^T \rightarrow[batch size,head size,
seq len,embed dim/h]\)head_size:即多头注意力机制中的head, \(head size=embed dim/head num\)
embed_size:句子中每个字的编码向量的长度
seq_len:句子的长度
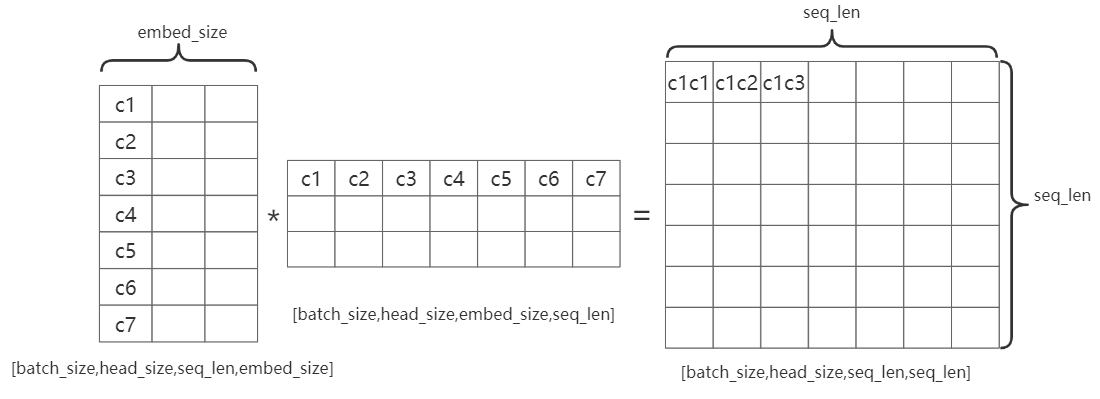
如图:C1C2表示第一个字和第二个字的注意力机制结果
\(Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\)
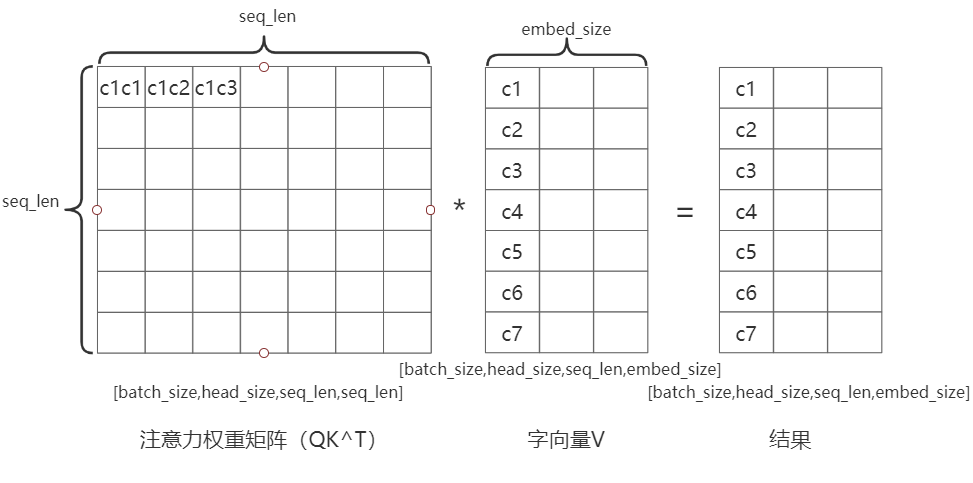
\(\frac{QK^T}{\sqrt{d_k}}\)的第一列和\(V\)的第一行决定了结果中的第一个值,这样保证了结果向量中每个元素包含了该句中所有字的特征note:
Attention mask
在encoder的过程中,输入句子的\(seq len\)是不等长的,此时需要对句子进行补全,如果使用0补全,使用softmax函数\(softmax=\sigma(z)=\frac{e^{z_i}}{\sum^{k}_{j=1}e^{z_j}}\),e=0时,将导致补0的部分参与到运算中
解决办法:给补0的部分添加偏置\(Z_{illeagl}=Z_{illeagl}+bias ,\ bias\rightarrow -\infty\)
此时,\(e^{-\infty}=0 ,\ e^{Z_{illegal}}=0\),便面了无效区参与运算。


3. Layer Normalization 残差连接
- \(X=X_{embedding}+Attention(Q,K,V)\)


