【Python机器学习实战】决策树与集成学习(六)——集成学习(4)XGBoost原理篇
XGBoost是陈天奇等人开发的一个开源项目,前文提到XGBoost是GBDT的一种提升和变异形式,其本质上还是一个GBDT,但力争将GBDT的性能发挥到极致,因此这里的X指代的“Extreme”的意思。XGBoost通过在算法和工程上进行了改进,使其在性能和精度上都得到了很大的提升,也成为了Kaggle比赛和工程应用的大热门。XGBoost是大规模并行的BoostingTree的工具,比通常的工具包快10倍以上,是目前最好的开源BoostingTree的工具包,在工业界规模方面,XGBoost的分布式版本有广泛的可移植性,支持在YARN, MPI, Sungrid Engine等各个平台上面运行,并且保留了单机并行版本的各种优化,使得它可以很好地解决于工业界规模的问题。
XGBoost原理
从GBDT到XGBoost
引言中说到,XGBoost实际上也是一种GBDT,不过在算法和性能上做了很多优化和提升,其优化主要包括以下几个方面:
- 就算法本身有以下优化:就性能方面的优化主要是对每个弱分类器(如决策树)的学习时,采用并行的方式进行选择节点所要分裂的特征和特征值,其做法是,在进行分裂之前,首先对所有的特征值进行排序和分组,以便进行并行处理,对分组的特征,选择合适的分组大小,利用CPU的缓存读取加速,将分组保存在多个硬盘提高IO速度。
- 在算法的弱分类器的选择上,GBDT所选择的只能是回归树,而XGBoost中则可以选择其他很多的弱分类器;
- 在算法的损失函数上,XGBoost除了本身的损失,还加上了正则化提高模型的泛化能力;
- 在算法的优化过程中,GBDT采用负梯度(一阶泰勒展开)来近似代替残差,而在XGBoost算法中,使用二阶泰勒展开来损失函数误差进行拟合,使其更加精确。
- 此外还有XGBoost在对缺失值进行处理时,通过枚举所有可能的取值在当前节点是进入左子树还是右子树来决定缺失值的处理方式。
上面就是XGBoost在GBDT的基础上进行的优化的几个方面,其中主要是算法方面的优化,GBDT其实也可以以并行的方式进行处理,接下来就主要描述XGBoost在算法方面的具体优化过程。
首先回顾一下GBDT的算法过程:
”””
对于迭代次数1~M:
-
-
-
- 计算负梯度:
-
-
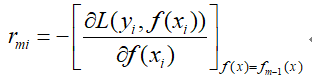
-
-
-
- 然后以数据(xi,rmi)构建一颗决策树,所构建的决策树叶子结点区域为Rmj。
- 分别对于每个叶子节点区域,拟合出该叶子节点最佳的输出值:
-
-
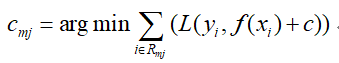
-
-
-
- 然后更新强分类器:
-
-
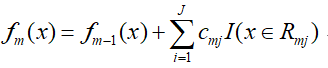
”””
整个迭代过程就是首先获得负梯度,然后以负梯度代替残差拟合一颗最优的决策树,接下来对叶子结点进行线性搜索,得到每个叶子节点的最优值,最终得到当前轮的强分类器。
从上面可以看出,在求解过程中,分别求了最优的决策树,即最优的叶子节点区域和最优的叶子结点区域的取值,也就是进行了两次优化,且两次优化是顺序进行的,那么对于XGBoost中希望能够将两步合并在一起进行,即一次求解出最优的J个叶子节点区域和叶子结点区域对应的最优值,在讨论二者如何同时进行之前,先来看一下XGBoost的损失函数:
上面提到,XGBoost在GBDT的损失函数的基础上加上了正则化项,其正则化项如下(假设当前迭代为第m轮):
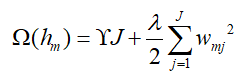
这里的wmj就是GBDT中第j个叶子结点的最优值cmj,不过论文中是以w的形式给出,这里就以w表示叶子结点的最优值。
那么根据正则化项,XGBoost的损失函数变成了:
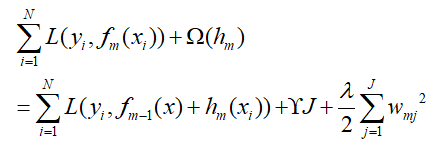
将本身损失函数部分按泰勒二阶展开,如下:
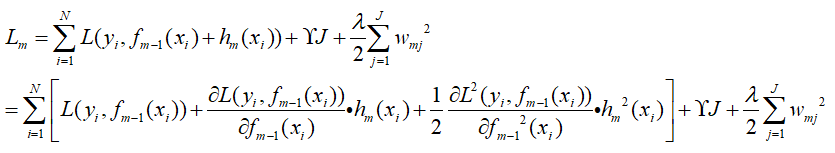
令一阶导数为hmi,令二阶导数为gmi(这里一阶和二阶跟原文搞反了,后面就按这个推导吧),那么上式变成了:
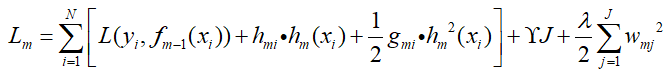
上式中L(yi,fm-1(xi))是一个常数,对其没有影响,忽略不计,那么:
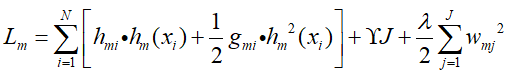
由于叶子节点j,其对应的输出值wmj,那么hm(xi)进一步转化:
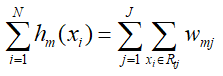
那么损失函数进一步合并,转换为:

再次令:

那么最终,XGBoost的损失函数变成了:
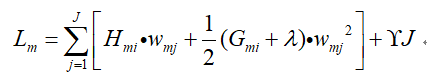
那么接下来如何同时求得最优的叶子节点J和叶子节点最优的输出值wmj*呢?
XGBoost的求解
这两个问题并成一步其实就是:同时(1)找出一颗最优的决策树,然后(2)使得最优的决策树的所有叶子节点的输出值最优。
首先先看第二个问题,要想找到叶子节点最优的输出值,只需要让损失函数Lm最小即可,这一点同GBDT是一样的,对Lm进行求导,令其为0,即可求解出wmj*:
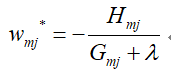
—————————————————–
Tips:
为什么说在GBDT中也是这样的呢?,在GBDT中,第m颗树的叶子结点j最优输出值cmj的近似值是这样的:
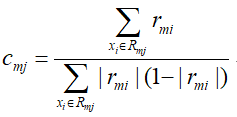
还记得二元分类中的对数似然损失函数:
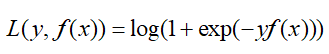
那么这个损失函数的一阶倒数hi和二阶导数gi如下:

在GBDT中没有正则项,那么可以看出cmj的近似表达式就是一阶倒数和二阶导数的比值,即:
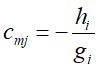
—————————————————–
上述过程也解释了在XGBoost算法中,使用二阶泰勒展开来损失函数误差进行拟合,那么接下来就要看树是如何进行分裂,才能得到最优的决策树及其叶子节点区域了,即如何选择特征及其对应的特征值使得最终的损失函数Lm最小?
在GBDT中是采用的CART回归树的算法(前面在GBDT实例中有个标注,说无论损失函数是什么,在节点进行分裂时,都是使用的均方误差最小作为划分依据,这样看来那里理解是对的)进行树的分裂,而在XGBoost中,树的分裂不再使用均方误差作为划分依据,而是采用贪心算法,在每次进行分裂时都期望最小化损失函数。
当每个叶子节点都取值达到最优的时候,即将wml*代入到原损失函数中,那么损失函数就变成了:

那么,如果每次进行分裂时,让这个损失函数减小的越多就越好,假设当前节点的左右子节点的一阶导数和分别为HL、HR,二阶导数的和分别为:GL、GR,若当前节点不再进行分裂的损失为:
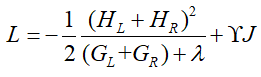
若进行分裂,则分裂出左右子节点,那么损失为:

我们期望两者的差值越大越好,即:
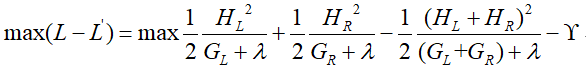
使得上面这个式子值最大的划分点就是最好的。
举个例子:
假设一组数据,其中有一个年龄特征,将年龄的值进行排序,同CART一样对可能的年龄取值进行遍历,可以将数据划分为两部分,比如某个取值a,将年龄大于a的放在右边,年龄小于a的放在左边:

将数据划分为上图中的两个部分,然后分别计算左右子树的一阶导数和、二阶导数和,代入到L-L‘中求得一个分数(score),不断调整a的值,重复上述过程,然后更换其他特征(相当于外循环),再次循环上述过程,最终最大的score即为最优的特征和对应的特征切分点。
那么,到这里就能理解了XGBoost论文中对于切分点搜索的算法了(下文会对此做一个描述):

到这里上述两个过程已经解决了,之所以不同于GBDT就是上面的两个方面是同步进行的,因为在进行树的分裂的时候就已经朝着叶子节点最优输出值的目标(wml*)进行的,而GBDT则是先根据上一轮残差拟合出一颗决策树,然后再去求最优的叶子节点最优值。
XGBoost算法流程
上面过程是XGBoost的核心步骤,那么整个算法在GBDT的基础上,换掉其核心算法即为XGBoost的算法流程,下面对算法进行描述:
“””
输入:训练数据{(x1,y1),(x2,y2),…,(xN,yN)},迭代次数M,损失函数L,正则化参数γ、λ;
输出:强分类器f(x);
- 初始化强分类器f0(x);
- 对于迭代次数m=1~M:
- 计算每个样本在当前损失函数L对fm-1(xi)的一阶导数hmi,二阶导数gmi;
- 对当前节点开始尝试进行分裂,默认score=0,并计算当前节点的一阶导数和H,二阶导数和G;
- 对于特征1~K:
- HL=0,GL=0:
- 将特征值按照从小到大进行排序,依次取出样本xi将其放入左子树,然后计算左右子树的一阶导数、二阶导数和:

-
-
- 更新分数score:
-
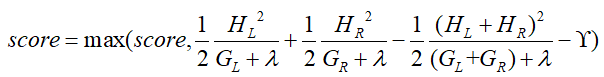
-
- 选出最大的score所对应的特征及其特征值对该节点进行分裂;
- 若score值为0,则当前决策树建立完毕,计算出所有的叶子节点的值wmj*,得到弱分类器hm(x),叠加得到强分类器fm(x),退出当前轮迭代,进入下一轮;若score不为0,则转回节点分裂开始阶段,继续对下层节点进行树的分裂;
“””
性能上的优化
XGBoost在对某一特征选取最优特征划分点的时候采用的是并行的方式处理的,将其放到多线程中运行提高运行效率。具体做法是:前面算法中提到,将特征值按照从小到大的顺序进行排列,首先所有样本默认放在右子树中,然后从小到大迭代,依次放入左子树中,寻找出最优的切分点,这样减少了很多不必要的比较。此外,通过设置合理的分块的大小,充分利用了CPU缓存进行读取加速(cache-aware access),使得数据读取的速度更快。另外,通过将分块进行压缩(block compressoin)并存储到硬盘上,并且通过将分块分区到多个硬盘上实现了更大的IO。
健壮性的优化
在对算法和性能优化的同时,XGBoost还对算法的健壮性进行了优化,除了前面提到的加入了正则化提高模型的泛化能力,XGBoost还对特征的缺失值进行了处理。
XGBoost没有假设缺失值一定进入到左子树还是右子树,而是通过枚举所有可能缺失值进入左子树还是右子树,来决定缺失值到底进入到左还是右。
也就是说,上面的算法步骤中节点分裂步骤会走两次,假设缺失的特征为k,第一次所有的缺失样本都走左子树,第二次是都走右子树,然后每次没有缺失值的特征(除k以外)的样本都走上述流程,而不是所有的样本。由于默认样本都在右子树,步骤不变,当样本都走左子树时,要依次往右节点放入样本,那么初始化需要HR、GR为0。
以上就是XGBoost的基本原理内容,XGBoost主要是对算法上的优化比较多,就整体算法流程而言,XGBoost与GBDT无异,主要体现在了弱学习器(树)的生成方面,具体XGBoost的原论文://arxiv.org/pdf/1603.02754v1.pdf。后面会找一些XGBoost的实例和调参过程学习一下,了解其涉及的参数和优化过程。
XGBoost是一个比较重要的机器学习算法,后续有机会通过小实例重复一下其算法步骤,加深算法的理解,会再翻看一些大神的文章去发现自己理解问题,后面会再进行补充。


