Redis应用场景及缓存问题
1.应用场景
(1) 缓存
缓存机制几乎在所有的大型网站都有使用,合理地使用缓存不仅可以加快数据的访问速度,而且能够有效地降低后端数据源的压力。Redis 提供了键值过期时间设置,并且也提供了灵活控制最大内存和内存溢出后的淘汰策略。可以这么说,一个合理的缓存设计能够为一个网站的稳定保驾护航。
(2) 排行榜系统
排行榜系统几乎存在于所有的网站,例如按照热度排名的排行榜,按照发布时间的排行榜,按照各种复杂维度计算出的排行榜, Redis 提供了列表和有序集合数据结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统。
(3) 计数器应用
计数器在网站中的作用至关重要,例如视频网站有播放数、电商网站有浏览数,为了保证数据的实时性,每一次播放和浏览都要做加1 的操作,如果并发量很大对千传统关系型数据的性能是一种挑战。Redis 天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
(4) 社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大,而且传统的关系型数据不太适合保存这种类型的数据, Redis 提供的数据结构可以相对比较容易地实现这些功能。
(5) 消息队列系统
消息队列系统可以说是一个大型网站的必备基础组件,因为其具有业务解耦、非实时业务削峰等特性。Redis 提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列比还不够足够强大,但是对于一般的消息队列功能基本可以满足。
2.使用缓存的收益和成本
如图左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层+存储层架构,下面分析一下缓存加入后带来的收益和成本。
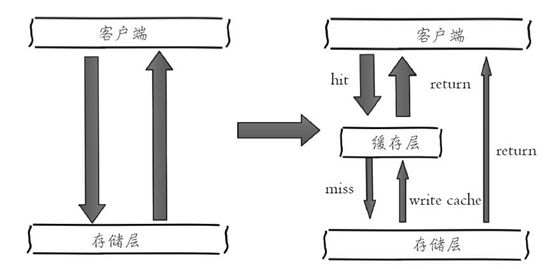
收益:
l 加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
l 降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。
成本:
l 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
l 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
l 运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。
3. 缓存问题
3.1 缓存穿透
3.1.1 问题描述
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层,如下图所示
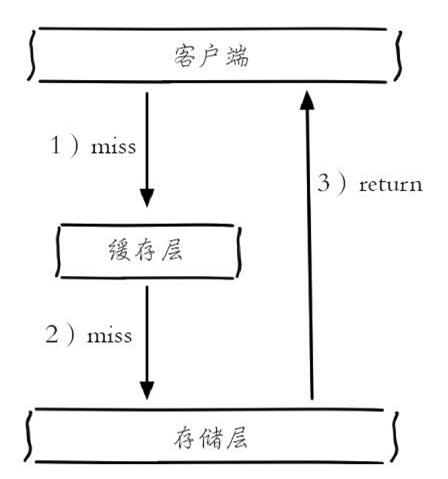
整个过程分为如下3步:
1) 缓存层不命中。
2) 存储层不命中,不将空结果写回缓存。
3) 返回空结果。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
3.1.2解决方案
造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题,第二,一些恶意攻击、爬虫等造成大量空命中。下面我们来看一下如何解决缓存穿透问题。
(1) 缓存空对象
如图所示,当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。
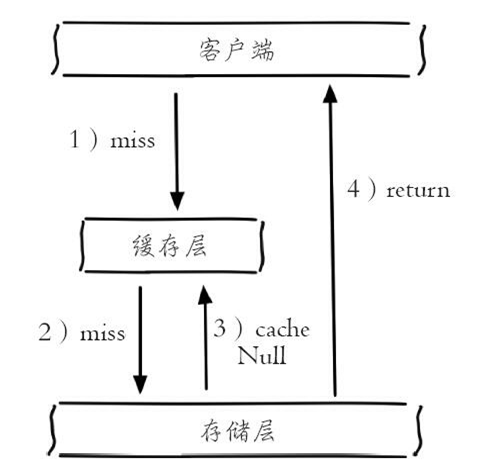
缓存空对象会有两个问题:第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间,比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
(2) 布隆过滤器拦截
布隆过滤器:实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。可以告诉你某样东西一定不存在或者可能存在。
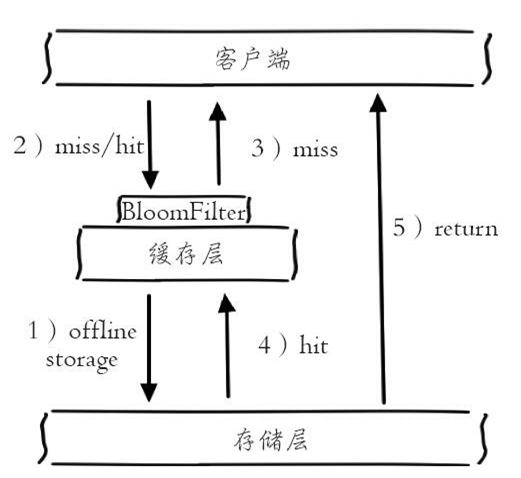
如图所示,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。例如:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。
(3) 两种方案比对
|
解决缓存穿透 |
适用场景 |
维护成本 |
|
缓存空对象 |
l 数据命中不高 l 数据频繁变化实时性高 |
l 代码维护简单 l 需要过多的缓存空间 l 数据不一致 |
|
布隆过滤器 |
l 数据命中不高 l 数据相对固定实时性低 |
l 代码维护复杂 l 缓存空间占用少 |
3.2 缓存雪崩
如图描述了什么是缓存雪崩:由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。
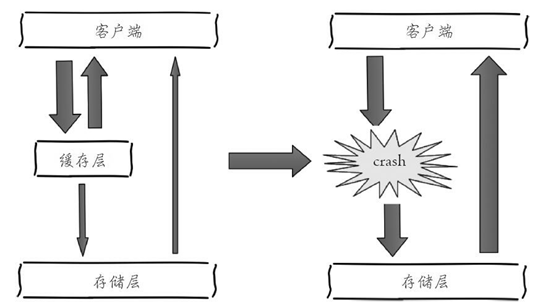
预防和解决缓存雪崩问题,可以从以下三个方面进行着手。
(1) 保证缓存层服务高可用性。如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如前面介绍过的Redis Sentinel和Redis Cluster都实现了高可用。
(2) 依赖隔离组件为后端限流并降级。无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞在这个资源上,造成整个系统不可用。降级机制在高并发系统中是非常普遍的。实际项目中,我们需要对重要的资源(例如Redis、MySQL、HBase、外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池、开启资源池、资源池阀值管理,这些做起来还是相当复杂的。这里推荐使用Java依赖隔离工具Hystrix,他是解决依赖隔离的利器。
(3) 提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
3.3 缓存击穿(热点数据集中失效)
3.3.1 问题描述
当一个key是热点key,并发量很大,而且重建缓存不能在短时间完成,在缓存失效的一瞬间,就会有大量的线程来重建缓存,造成后端负载加大,甚至让应用崩溃,这就叫缓存击穿。如下图:
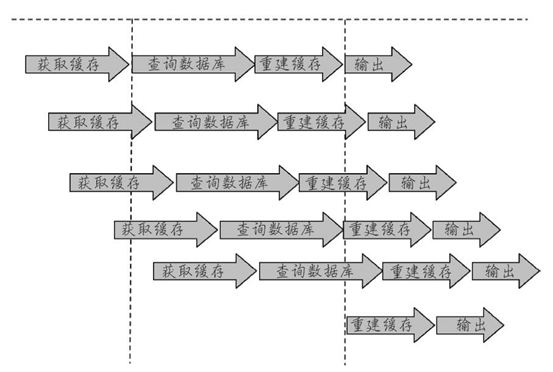
3.3.2 解决方案
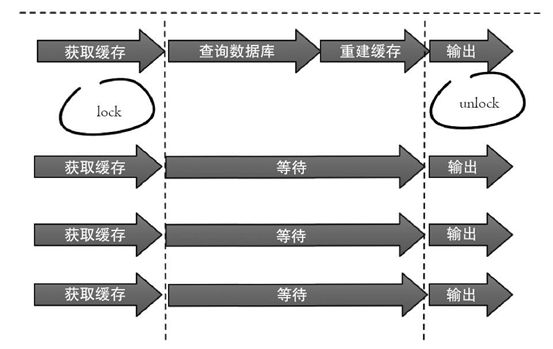
(1) 互斥锁
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如图所示。
(2) 永远不过期
“永远不过期”包含两层意思:
l 从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
l 从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
整个过程如图所示:
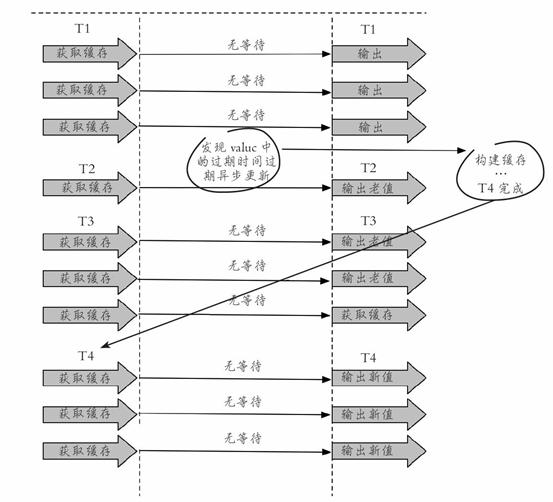
此方法有效杜绝了热点key产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。
(3) 两种方案对比
|
解决方案 |
优点 |
缺点 |
|
互斥锁 |
l 思路简单 l 保持一致性 |
l 代码复杂度大 l 存在死锁风险 l 存在线程阻塞风险 |
|
永远不过期 |
基本杜绝热点key问题 |
l 不保证一致性 l 逻辑过期时间增加代码维护成本和内存成本 |

