谷粒商城–分布式高级篇P102~P128
谷粒商城–分布式高级篇P102~P128
由于学习的时间也比较少,只有周六周末才有时间出来学习总结,所以一篇一篇慢慢更新吧,本次总结内容为Elasticsearch(相关内容:kibana,es,nginx,ik分词器)
【谷粒商城–分布式基础篇P1~P27】: //blog.csdn.net/Empire_ing/article/details/118860147
【谷粒商城–分布式基础篇P28~P101】//mp.weixin.qq.com/s/5kvXjLNyVn-GBhNMWyJdpg
@
🔥1.ElasticSearch与kibana
内容概况:es、kibana、ik相关软件于centos中docker的下载与配置使用。本次安装最大感悟就是docker太好用了,真的好强。
之前也写过一篇关于es文章实例:
SpringBoot整合es实现高亮搜索://www.cnblogs.com/meditation5201314/p/14801585.html
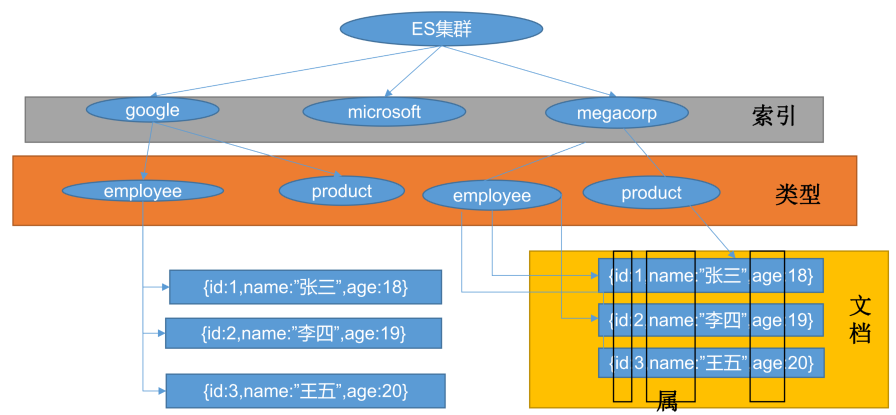
1.1.基本概念
索引index:类似于数据库
类型type:类似于库中的表
文档document:类似于表的每一行
方法/属性:类似于每一行的字段
1.2 安装es与kibana
1. ES访问地址://公网IP:9200/
# 1、下载包
docker pull elasticsearch:7.4.2
# 2、配置es文件映射
# 将docker里的目录挂载到linux的/mydata目录中
# 修改/mydata就可以改掉docker里的
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
# es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
# 递归更改权限,es需要访问
chmod -R 777 /mydata/elasticsearch/
# 3、启动es
# 9200是用户交互端口 9300是集群心跳端口 -e指定是单阶段运行 -e指定占用的内存大小,生产时可以设置32G
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
# 4、设置开机启动elasticsearch
docker update elasticsearch --restart=always
- kibana下载、配置、启动
Kibana访问地址://公网IP:5601/
# 1、下载包
docker pull kibana:7.4.2
# 2、启动es(这里填自己的IP地址)
docker run --name kibana -e ELASTICSEARCH_HOSTS=//公网IP:9200 -p 5601:5601 -d kibana:7.4.2
# 3、设置开机启动kibana
docker update kibana --restart=always
访问地址:
查看es的node节点://公网IP:9200/_cat/nodes
查看es的helth健康状态://公网IP:9200/_cat/health
查看es的master主节点://公网IP:9200/_cat/master
查看es的索引主节点://公网IP:9200/_cat/indices
1.3 Nginx安装
docker run -p80:80 --name nginx -d nginx:1.10
mkdir -p /mydata/nginx/html
mkdir -p /mydata/nginx/logs
mkdir -p /mydata/nginx/conf
docker container cp nginx:/etc/nginx/* /mydata/nginx/conf/
#由于拷贝完成后会在config中存在一个nginx文件夹,所以需要将它的内容移动到conf中
mv /mydata/nginx/conf/nginx/* /mydata/nginx/conf/
rm -rf /mydata/nginx/conf/nginx
docker stop nginx
docker rm nginx
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf/:/etc/nginx \
-d nginx:1.10
docker update nginx --restart=always
1.4 Ik中文分词器
在elasticsearch/plugins目录下下载解压ik分词器后重启即可
#下载ik分词器
wget //github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
#解压并重命名ik
unzip elasticsearch-analysis-ik-7.4.2.zip -d ik
chmod -R 777 plugins/ik
rm -rf elasticsearch-analysis-ik-7.4.2.zip #这里要保证plugins目录下纯净,否则启动会报错
docker restart elasticsearch
🔥2.SpringBoot整合Es
2.1.环境配置
- ELK版本对应并去掉springboot中自带的es包
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
- Config配置
package com.empirefree.gulimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @program: gulimall-search
* @description:
* @author: huyuqiao
* @create: 2021/08/01 13:54
*/
@Configuration
public class GulimallElasticSearchConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient restHighLevelClient(){
RestClientBuilder restClientBuilder = null;
restClientBuilder = RestClient.builder(new HttpHost("公网IP", 9200, "http"));
RestHighLevelClient client = new RestHighLevelClient(restClientBuilder);
return client;
}
}
2.2.搜索实现
用过两款,一种是狂神的整合es高亮,一种是现在的,做的一些平均值,有点难理解,但是还是先贴出来
@Test
public void testEs() throws IOException {
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("newbank");
// 1.指定检索条件 DSL
SearchSourceBuilder builder = new SearchSourceBuilder();
// 1.1 构造检索条件
builder.query(QueryBuilders.matchQuery("address","mill"));
// 1.2 按照年龄值聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
builder.aggregation(ageAgg);
// 1.3 计算平均薪资
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
builder.aggregation(balanceAvg);
System.out.println("检索条件:" + builder.toString());
searchRequest.source(builder);
// 2.执行检索
SearchResponse search = restHighLevelClient.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 3.分析结果
// Map map = JSON.parseObject(search.toString(), Map.class);
// System.out.println(map);
// 3.1 索取所有记录
SearchHits hits = search.getHits();
// 详细记录
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
// String index = hit.getIndex();
// String id = hit.getId();
String source = hit.getSourceAsString();
Account account = JSON.parseObject(source, Account.class);
System.out.println(account);
}
// 获取分析数据
Aggregations aggregations = search.getAggregations();
// List<Aggregation> list = aggregations.asList();
// for (Aggregation aggregation : list) {
// Terms agg = aggregations.get(aggregation.getName());
// System.out.println(agg.getBuckets());
// }
Terms agg = aggregations.get("ageAgg");
for (Terms.Bucket bucket : agg.getBuckets()) {
System.out.println("年龄: " + bucket.getKeyAsString() + "-->" + bucket.getDocCount() + "人");
}
Avg avg = aggregations.get("balanceAvg");
System.out.println("平均薪资: " + avg.getValue());
}
书山有路勤为径,学海无涯苦作舟。程序员不仅要懂代码,更要懂生活,关注我,一起进步。


