TensorFlow读取数据的三种方法
- 2019 年 10 月 3 日
- 筆記
tensortlfow数据读取有三种方式
- placehold feed_dict:从内存中读取数据,占位符填充数据
- queue队列:从硬盘读取数据
- Dataset:同时支持内存和硬盘读取数据
placehold-feed_dict
先用placehold 占位数据,在Graph中读取数据,数据直接内嵌到Graph中,然后当Graph传入Session是,用feed_dict喂补数据。当数据量比较大的时候,Graph的传输会遇到效率底下问题,特别是数据转换。
import tensorflow as tf import librosa # 把数据加载在Graph中 x1 = librosa.load("temp_1.wav", sr=16000) x2 = librosa.load("temp_2.wav", sr=16000) y = tf.add(x1, x2) with tf.Session() as sess: print(sess.run(y))
queue队列
如果我们的数据读取算法没有设计多线程的话(即单线程),由于读取数据和处理数据在同一个进程是有先后关系的,意味着数据处理完后必须花时间读取数据,然后才能进行计算处理。这样的一来GPU并没有高效的专一做一件事情,从而大大的降低的效率,queue创建多线程彻底的解决了这个问题。
tensorflow中为了充分的利用时间,减少GPU等待的空闲时间,使用了两个线程(文件名队列和内存队列)分别执行数据读入和数据计算。文件名队列源源不断的将硬盘中的图片数据,内存队列负责给GPU送数据,所需数据直接从内存队列中获取。两个线程之间互不干扰,同时运行。
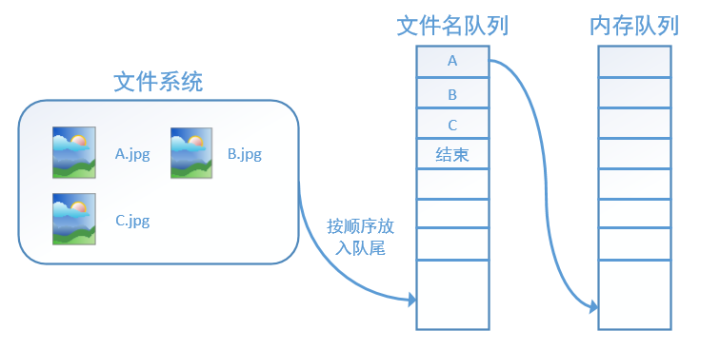
因此 tensorflow 在内存队列之前,还要使用tf.train.slice_input_producer函数,创建一个文件名队列,文件名队列存放的是参与训练的文件名,要训练N个epoch,则文件名队列中就含有N个批次的所有文件名。
tf.train.slice_in put_producer()
使用到 tf.train.slice_input_producer 函数创建文件名队列。在N个epoch的文件名最后是一个结束标志,当tf读到这个结束标志的时候,会抛出一个OutofRange 的异常,外部捕获到这个异常之后就可以结束程序了。
slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None, capacity=32, shared_name=None, name=None)
返回tensor生成器,作用是按照设定,每次从一个tensor_list中按顺序或者随机抽取出一个tensor放入文件名队列。
参数:
- tensor_list:tensor的列表,表中tensor的第一维度的值必须相等,即个数必须相等,有多少个图像,就应该有多少个对应的标签
- num_epochs: 迭代的次数,num_epochs=None,生成器可以无限次遍历tensor列表;num_epochs=N,生成器只能遍历tensor列表N次
- shuffle: bool,是否打乱样本的顺序。一般情况下,如果shuffle=True,生成的样本顺序就被打乱了,在批处理的时候不需要再次打乱样本,使用 tf.train.batch函数就可以了;如果shuffle=False,就需要在批处理时候使用 tf.train.shuffle_batch函数打乱样本
- seed: 生成随机数的种子,shuffle=True的情况下才有用
- capacity:队列容量的大小,为整数
- shared_name:可选参数,如果设置一个”shared_name”,则在不同的上下文Session中可以通过这个名字共享生成的tensor
- name:设置操作的名称
如果tensor_list=[data, lable],其中data.shape=(4000,10),label.shape=[4000,2],则生成器生成的第一个队列
input_quenue[0].shape=(10,)
input_quenue[1].shape=(2,)
要真正将文件放入文件名队列,还需要调用tf.train.start_queue_runners 函数来启动执行文件名队列填充的线程,之后计算单元才可以把数据读出来,否则文件名队列为空的,计算单元就会处于一直等待状态,导致系统阻塞。
import tensorflow as tf images = ["img1", "img2", "img3", "img4", "img5"] labels = [1, 2, 3, 4, 5] epoch_num = 8 # 文件名队列 input_queue = tf.train.slice_input_producer([images, labels], num_epochs=None, shuffle=False) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) coord = tf.train.Coordinator() # 创建一个协调器,管理线程 # 启动QueueRunner, 执行文件名队列的填充 threads = tf.train.start_queue_runners(sess=sess, coord=coord) for i in range(epoch_num): k = sess.run(input_queue) print(i, k) # 0[b'img1', 1] # 1[b'img2', 2] # 2[b'img3', 3] # 3[b'img4', 4] # 4[b'img5', 5] # 5[b'img1', 1] # 6[b'img2', 2] # 7[b'img3', 3] coord.request_stop() coord.join(threads)
tf.train.batch & tf.train.shuffle_batch()
tf.train.batch( tensors_list, batch_size, num_threads=1, capacity=32, enqueue_many=False, shapes=None, dynamic_pad=False, allow_smaller_final_batch=False, shared_name=None, name=None )
tf.train.batch & tf.train.shuffle_batch()这两个函数的参数是一样的,下面我以tf.train.batch讲解为例
tf.train.batch是一个tensor队列生成器,作用是按照给定的tensor顺序,把batch_size个tensor推送到文件队列,作为训练一个batch的数据,等待tensor出队执行计算。
- tensors:一个列表或字典的tensor用来进行入队
- batch_size: 每次从队列中获取出队数据的数量
- num_threads:用来控制入队tensors线程的数量,如果num_threads大于1,则batch操作将是非确定性的,输出的batch可能会乱序
- capacity: 设置队列中元素的最大数量
- enqueue_many: 在第一个参数tensors中的tensor是否是单个样本
- shapes: 可选,每个样本的shape,默认是tensors的shape
- dynamic_pad: Boolean值;允许输入变量的shape,出队后会自动填补维度,来保持与batch内的shapes相同
- allow_smaller_final_batch: 设置为True,表示在tensor队列中剩下的tensor数量不够一个batch_size的情况下,允许最后一个batch的数量少于batch_size进行出队, 设置为False,小于batch_size的样本不会做出队处理
- shared_name: 可选参数,设置生成的tensor序列在不同的Session中的共享名称;
- name: 操作的名称;
以下举例: 一共有5个样本,设置迭代次数是2次,每个batch中含有3个样本,不打乱样本顺序:
import tensorflow as tf import numpy as np sample_num = 5 # 样本个数 epoch_num = 2 # 设置迭代次数 batch_size = 3 # 设置一个批次中包含样本个数 batch_total = int(sample_num / batch_size) + 1 # 计算每一轮epoch中含有的batch个数 # 生成4个数据和标签 def generate_data(sample_num=sample_num): labels = np.asarray(range(0, sample_num)) images = np.random.random([sample_num, 224, 224, 3]) print("image size {}, label size: {}".format(images.shape, labels.shape)) # image size (5, 224, 224, 3), label size: (5,) return images, labels def get_batch_data(batch_size=batch_size): images, label = generate_data() images = tf.cast(images, tf.float32) # 数据类型转换为tf.float32 label = tf.cast(label, tf.int32) # 数据类型转换为tf.int32 # 从tensor列表中按顺序或随机抽取一个tensor,主要代码 input_queue = tf.train.slice_input_producer([images, label], shuffle=False) image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64) return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess: coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess, coord) try: for i in range(epoch_num): # 每一轮迭代 print(" ** ** ** ** ** ** ") for j in range(batch_total): # 遍历每一个batch # 获取每一个batch中batch_size个样本和标签 image_batch_v, label_batch_v = sess.run([image_batch, label_batch]) # for k in print(image_batch_v.shape, label_batch_v) # ** ** ** ** ** ** # (3, 224, 224, 3) [0 1 2] # (3, 224, 224, 3) [3 4 0] # ** ** ** ** ** ** # (3, 224, 224, 3) [1 2 3] # (3, 224, 224, 3) [4 0 1] except tf.errors.OutOfRangeError: print("done") finally: coord.request_stop() coord.join(threads)
与tf.train.batch函数相对的还有一个tf.train.shuffle_batch函数,两个函数作用一样,都是生成一定数量的tensor,组成训练一个batch需要的数据集,区别是tf.train.shuffle_batch会打乱样本顺序。
下面这段代码和上面想表达的相同,但是如果tf.train.slice_input_producer中设置了epoch,则后面训练的时候,不需要for循环epoch,只需要设置coord.should_stop。
import numpy as np import tensorflow as tf def next_batch(): datasets = np.asarray(range(0, 20)) input_queue = tf.train.slice_input_producer([datasets], shuffle=False, num_epochs=1) data_batchs = tf.train.batch(input_queue, batch_size=5, num_threads=1, capacity=20, allow_smaller_final_batch=False) return data_batchs if __name__ == "__main__": data_batchs = next_batch() sess = tf.Session() sess.run(tf.initialize_local_variables()) coord = tf.train.Coordinator() # 创建一个协调器,管理线程 threads = tf.train.start_queue_runners(sess, coord) # 启动线程 try: while not coord.should_stop(): data = sess.run([data_batchs]) print(data) # [array([0, 1, 2, 3, 4])] # [array([5, 6, 7, 8, 9])] # [array([10, 11, 12, 13, 14])] # [array([15, 16, 17, 18, 19])] # complete except tf.errors.OutOfRangeError: print("complete") finally: coord.request_stop() coord.join(threads) sess.close()
注意:tf.train.batch这个函数的实现是使用queue,需要使用tf.initialize_local_variables(),如果使用tf.global_varialbes_initialize()时,会报: Attempting to use uninitialized value 。并不是tf.initialize_local_variables()替换了tf.global_varialbes_initialize(),而是他们有不同的功能,并要的时候都要使用
batch的使用方法,实现感知机。


import tensorflow as tf import scipy.io as sio def get_Batch(data, label, batch_size): print(data.shape, label.shape) input_queue = tf.train.slice_input_producer([data, label], num_epochs=1, shuffle=True, capacity=32) x_batch, y_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=32, allow_smaller_final_batch=False) return x_batch, y_batch data = sio.loadmat('data.mat') train_x = data['train_x'] train_y = data['train_y'] test_x = data['test_x'] test_y = data['test_y'] x = tf.placeholder(tf.float32, [None, 10]) y = tf.placeholder(tf.float32, [None, 2]) w = tf.Variable(tf.truncated_normal([10, 2], stddev=0.1)) b = tf.Variable(tf.truncated_normal([2], stddev=0.1)) pred = tf.nn.softmax(tf.matmul(x, w) + b) loss = tf.reduce_mean(-tf.reduce_sum(y * tf.log(pred), reduction_indices=[1])) optimizer = tf.train.AdamOptimizer(2e-5).minimize(loss) correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(pred, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name='evaluation') x_batch, y_batch = get_Batch(train_x, train_y, 1000) # 训练 with tf.Session() as sess: # 初始化参数 sess.run(tf.global_variables_initializer()) sess.run(tf.local_variables_initializer()) # 开启协调器 coord = tf.train.Coordinator() # 使用start_queue_runners 启动队列填充 threads = tf.train.start_queue_runners(sess, coord) epoch = 0 try: while not coord.should_stop(): # 获取训练用的每一个batch中batch_size个样本和标签 data, label = sess.run([x_batch, y_batch]) sess.run(optimizer, feed_dict={x: data, y: label}) train_accuracy = accuracy.eval({x: data, y: label}) test_accuracy = accuracy.eval({x: test_x, y: test_y}) print("Epoch %d, Training accuracy %g, Testing accuracy %g" % (epoch, train_accuracy, test_accuracy)) epoch = epoch + 1 except tf.errors.OutOfRangeError: # num_epochs 次数用完会抛出此异常 print("---Train end---") finally: # 协调器coord发出所有线程终止信号 coord.request_stop() print('---Programm end---') coord.join(threads) # 把开启的线程加入主线程,等待threads结束
View Code
tf.data.Dataset
官方推荐用tf.data.Dateset,看到这个是不是有点心累,哈哈哈。
Tensorflow中之前主要用的数据读取方式主要有:
1、建立placeholder,然后使用feed_dict将数据feed进placeholder进行使用。使用这种方法十分灵活,可以一下子将所有数据读入内存,然后分batch进行feed;也可以建立一个Python的generator,一个batch一个batch的将数据读入,并将其feed进placeholder。这种方法很直观,用起来也比较方便灵活jian,但是这种方法的效率较低,难以满足高速计算的需求。
2、使用TensorFlow的QueueRunner,通过一系列的Tensor操作,将磁盘上的数据分批次读入并送入模型进行使用。这种方法效率很高,但因为其牵涉到Tensor操作,不够直观,也不方便调试,所有有时候会显得比较困难。使用这种方法时,常用的一些操作包括tf.TextLineReader,tf.FixedLengthRecordReader以及tf.decode_raw等等。如果需要循环,条件操作,还需要使用TensorFlow的tf.while_loop,tf.case等操作。
3、上面的方法我觉得已经要被tensorflow放弃了,现在官方推荐用tf.data.Dataset模块,使其数据读入的操作变得更为方便,而支持多线程(进程)的操作,也在效率上获得了一定程度的提高。
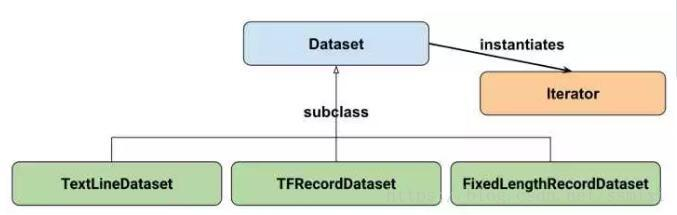
tf.data.Dataset.from_tensor_slices
创建了一个dataset,这个dataset中含有5个元素[1.0, 2.0, 3.0, 4.0, 5.0],为了将5个元素取出,方法是从Dataset中示例化一个iterator,然后对iterator进行迭代。
import tensorflow as tf import numpy as np dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0])) iterator = dataset.make_one_shot_iterator() # 从dataset中实例化一个iterator,只能从头到尾取一次,指名了顺序 one_element = iterator.get_next() # 从iterator中取一个元素 with tf.Session() as sess: try: for i in range(5): print(sess.run(one_element)) except tf.errors.OutOfRangeError: # iterator迭代完会抛出此异常 print("数据迭代完了")
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5, 2)))
数据的第一维度是个数,这个函数会切分第一维度,最后生成的dataset中含有5个元素,每个元素的形状是(2,)
dataset = tf.data.Dataset.from_tensor_slices( { "a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]), "b": np.random.uniform(size=(5, 2)) })
tf.data.Dataset.from_tensor_slices的参数,可以是列表也可以是字典,{“image”: “image_tensor”, “label”: “label_tensor”}
Trainformation
Dataset支持一类特殊的操作Trainformation,即一个Dataset通过Trainformation变成一个新的Dataset,可以理解为数据变换,对Dataset中的元素做变换(打乱、生成epoch…等操作)。
常用的Trainformation有:
- map
- batch
- shuffle
- repeat
1、dataset.map
这个函数很重要也经常用到,他接收一个函数,Dataset中的每一个元素都会被当做这个函数的输入,并将函数返回值作为新的Dataset,
例如:对dataset中每一个元素的值加1
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0])) dataset = dataset.map(lambda x: x + 1) # 2.0, 3.0, 4.0, 5.0, 6.0
2、dataset.batch
batch就是将多个元素组合成batch,如下面的程序将dataset中的每个元素组成了大小为6的batch:
# 创建0-10的数据集,每个6个数取一个batch。 dataset = tf.data.Dataset.range(10).batch(6) iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() with tf.Session() as sess: for i in range(2): value = sess.run(next_element) print(value) # [0 1 2 3 4 5] # [6 7 8 9]
tensorflow很好的帮我们自动处理最后的一个batch,但是,上面的for循环次数超过2,会报错,超过范围了,没值可取。
4、datasets.repeat
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch,当for循环取值超过一个epoch的时候,会开始下一个epoch。
dataset = tf.data.Dataset.range(10).batch(6) dataset = dataset.repeat(2) iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() with tf.Session() as sess: for i in range(4): value = sess.run(next_element) print(value) # [0 1 2 3 4 5] # [6 7 8 9] # [0 1 2 3 4 5] # [6 7 8 9]
repeat只是将数据集重复了指定的次数,但是如果for循环大于4还是会报错,所以简单的方法是repeat不设次数,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常:dataset = dataset.repeat()
dataset = tf.data.Dataset.range(10).batch(6) dataset = dataset.repeat() iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() with tf.Session() as sess: for i in range(6): value = sess.run(next_element) print(value) # [0 1 2 3 4 5] # [6 7 8 9] # [0 1 2 3 4 5] # [6 7 8 9] # [0 1 2 3 4 5] # [6 7 8 9]
3、dataset.shuffle
打乱dataset中的元素,它有一个参数buffer_size表示打乱顺序,buffer_size=1表示不打乱顺序,buffer_size越大,打乱程度越大,不设置会报错:
dataset = dataset.shuffle(buffer_size=10000)
shuffle打乱顺序很重要,建议先打乱顺序,再batch取值,因为如果是先执行batch操作的话,那么此时就只是对batch进行shuffle,而batch里面的数据顺序依旧是有序的,那么随机程度会减弱。
建议:dataset = tf.data.Dataset.range(10).shuffle(10).batch(6)
读入磁盘图片与对应label
我们可以来考虑一个简单,但同时也非常常用的例子:读入磁盘中的图片和图片相应的label,并将其打乱,组成batch_size=32的训练样本。在训练时重复10个epoch。
# 函数的功能时将filename对应的图片文件读进来,并缩放到统一的大小 def _parse_function(filename, label): image_string = tf.read_file(filename) image_decoded = tf.image.decode_image(image_string) image_resized = tf.image.resize_images(image_decoded, [28, 28]) return image_resized, label # 图片文件的列表 filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...]) # label[i]就是图片filenames[i]的label labels = tf.constant([0, 37, ...]) # filename是图片的文件名,label是图片对应的标签 dataset = tf.data.Dataset.from_tensor_slices((filenames, labels)) # 将filename对应的图片读入,并缩放为28x28的大小, dataset = dataset.map(_parse_function) # 在每个epoch内将图片打乱组成大小为32的batch,并重复10次。 # image_resized_batch(32, 28, 28, 3),label_batch(32, ) dataset = dataset.shuffle(buffer_size=1000).batch(32).repeat(10)
Dataset的其他创建方法
除了tf.data.Dataset.from_tensor_slices外,目前Dataset API还提供了另外三种创建Dataset的方式:
- tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
- tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
- tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
iterator
在非Eager模式下,最简单的创建Iterator的方法就是通过dataset.make_one_shot_iterator()来创建一个one_shot_iterator。除了这种iterator外,还有三个更复杂的Iterator,即:
- make_initializable_iterator
- make_reinitializable_iterator
- make_feedable_iterator
initializable_iterator必须要在使用前通过sess.run()来初始化。使用initializable iterator,可以将placeholder-feed_dict代入Iterator中,这可以方便我们通过参数快速定义新的Iterator。一个简单的initializable_iterator使用示例:
limit = tf.placeholder(dtype=tf.int32, shape=[]) # 此时的limit相当于一个“可变参数”,它规定了Dataset中数的“上限”。 dataset = tf.data.Dataset.from_tensor_slices(tf.range(start=0, limit=limit)) iterator = dataset.make_initializable_iterator() next_element = iterator.get_next() with tf.Session() as sess: # 初始化并feed initializable_iterator sess.run(iterator.initializer, feed_dict={limit: 10}) for i in range(10): value = sess.run(next_element) assert i == value
initializable_iterator还有一个功能:读入较大的数组。
在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中。当array很大时,会导致计算图变得很大,给传输、保存带来不便。这时,我们可以用一个placeholder取代这里的array,并使用initializable_iterator,只在需要时将array传进去,这样就可以避免把大数组保存在图里,示例代码为(来自官方例程):
# 读取numpy数据 with np.load("/var/data/training_data.npy") as data: features = data["features"] labels = data["labels"] # 查看图像和标签维度是否保持一致 assert features.shape[0] == labels.shape[0] # 创建placeholder features_placeholder = tf.placeholder(features.dtype, features.shape) labels_placeholder = tf.placeholder(labels.dtype, labels.shape) # 创建dataset dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder)) # 批量读取,打散数据,repeat() dataset = dataset.shuffle(20).batch(5).repeat() # [Other transformations on `dataset`...] dataset_other = ... iterator = dataset.make_initializable_iterator() data_element = iterator.get_nex() sess = tf.Session() # 注意迭代器要在循环语句之前初始化 sess.run(iterator.initializer, feed_dict={features_placeholder: features, labels_placeholder: labels}) for e in range(EPOCHS): for step in range(num_batches): x_batch, y_batch = sess.run(data_element) y_pred = model(x_batch) ... ... sess.close()
自定义方法
上面几种方法,都是官方可调用的方法,如果大家想自定义可以参考我的代码,这段代码是从tensorflow教程中偷来的。代码太长我的折叠起来了哈,这段代码大家可以直接拿去用(亲测可用)。
import numpy as np from tensorflow.contrib.learn.python.learn.datasets import base from tensorflow.python.framework import dtypes class DataSet(object): def __init__(self, datapoints, labels, fake_data=False, one_hot=False, dtype=dtypes.float32): """Construct a DataSet. one_hot arg is used only if fake_data is true. `dtype` can be either `uint8` to leave the input as `[0, 255]`, or `float32` to rescale into `[0, 1]`. """ dtype = dtypes.as_dtype(dtype).base_dtype if dtype not in (dtypes.uint8, dtypes.float32): raise TypeError('Invalid image dtype %r, expected uint8 or float32' % dtype) if labels is None: labels = np.zeros((len(datapoints),)) if fake_data: self._num_examples = 10000 self.one_hot = one_hot else: assert datapoints.shape[0] == labels.shape[0], ( 'datapoints.shape: %s labels.shape: %s' % (datapoints.shape, labels.shape)) self._num_examples = datapoints.shape[0] self._datapoints = datapoints self._labels = labels self._epochs_completed = 0 self._index_in_epoch = 0 @property def datapoints(self): return self._datapoints @property def labels(self): return self._labels @property def num_examples(self): return self._num_examples @property def epochs_completed(self): return self._epochs_completed def next_batch(self, batch_size, fake_data=False, shuffle=True): """Return the next `batch_size` examples from this data set.""" if fake_data: fake_image = [1] * 784 if self.one_hot: fake_label = [1] + [0] * 9 else: fake_label = 0 return [fake_image for _ in range(batch_size)], [ fake_label for _ in range(batch_size) ] start = self._index_in_epoch # Shuffle for the first epoch if self._epochs_completed == 0 and start == 0 and shuffle: perm0 = np.arange(self._num_examples) np.random.shuffle(perm0) self._datapoints = self.datapoints[perm0] self._labels = self.labels[perm0] # Go to the next epoch if start + batch_size > self._num_examples: # 如果初始epoch+batch_size(0+128)>样本总数 # Finished epoch self._epochs_completed += 1 # Get the rest examples in this epoch rest_num_examples = self._num_examples - start datapoints_rest_part = self._datapoints[start:self._num_examples] labels_rest_part = self._labels[start:self._num_examples] # Shuffle the data if shuffle: perm = np.arange(self._num_examples) np.random.shuffle(perm) self._datapoints = self.datapoints[perm] self._labels = self.labels[perm] # Start next epoch start = 0 self._index_in_epoch = batch_size - rest_num_examples end = self._index_in_epoch datapoints_new_part = self._datapoints[start:end] labels_new_part = self._labels[start:end] return np.concatenate((datapoints_rest_part, datapoints_new_part), axis=0), np.concatenate( (labels_rest_part, labels_new_part), axis=0) else: self._index_in_epoch += batch_size end = self._index_in_epoch return self._datapoints[start:end], self._labels[start:end]
View Code
想要真正弄懂建议自己写一个,虽然上面那个已经写的非常完美了。
- 要求1:每一个epoch之后都要shuff数据,
- 要求2:训练数据集不用去batch_size的整数。
打乱顺序
def shuffle_set(train_image, train_label, test_image, test_label): train_row = range(len(train_label)) random.shuffle(train_row) train_image = train_image[train_row] train_label = train_label[train_row] test_row = range(len(test_label)) random.shuffle(test_row) test_image = test_image[test_row] test_label = test_label[test_row] return train_image, train_label, test_image, test_label
取下一个batch
def get_batch(image, label, batch_size, now_batch, total_batch): if now_batch < total_batch-1: image_batch = image[now_batch*batch_size:(now_batch+1)*batch_size] label_batch = label[now_batch*batch_size:(now_batch+1)*batch_size] else: image_batch = image[now_batch*batch_size:] label_batch = label[now_batch*batch_size:] return image_batch, label_batch
epoch、 iteration和batchsize的区别:epoch是周期的意思,代表要重复训练epoch次,每个epoch包括样本数/batch个iteration
总结
本文主要介绍了tensortlfow三种读取数据方式的,placehold-feed_dict,queue队列还介绍了Dataset API的基本架构:Dataset类和Iterator类,以及它们的基础使用方法。
在非Eager模式下,Dataset中读出的一个元素一般对应一个batch的Tensor,我们可以使用这个Tensor在计算图中构建模型。
在Eager模式下,Dataset建立Iterator的方式有所不同,此时通过读出的数据就是含有值的Tensor,方便调试。
