Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering 论文笔记
Background
- 论文动机
- 现有的FVQA解决方案的局限性在于,它们无法精确选择地共同嵌入各种信息,这会引入意料之外的噪音(unexpected noises)来推断最终答案。
- 如何从视觉,语义和知识的角度收集面向问题的信息补充证据对于实现一般的VQA至关重要。
- 论文贡献
- 通过包含基于视觉,语义和知识模态的多层信息的异构图理解图像。同时考虑了这三种模式。
- 提出了一种模态感知异构图卷积网络,以捕获来自不同模态的面向问题的证据。特别是,我们利用每个卷积层中的注意力运算为给定问题选择最相关的证据,而卷积运算负责自适应特征聚合。
- 方法的良好可解释性,并提供了案例研究。模型通过注意力权重和门控数值的可视化,自动判断哪种模态(视觉,语义或事实)和实体对回答问题的贡献更大。
Model

==Visual Graph Construction== (视觉图构建)

构建全连接的视觉图(可能是为了尽可能找到所有的关系??)
使用Faster-RCNN识别出一组图像目标集合\mathcal{O}=\left\{o_{i}\right\}_{i=1}^{K},其中K=36,每一个目标对象都与以下向量有关:
- 视觉特征向量的维度\boldsymbol{v}_{i} \in \mathbb{R}^{d_{v}},d_{v}=2048;
- 空间特征向量\boldsymbol{b}_{i} \in \mathbb{R}^{d_{b}},d_{b}=4,\boldsymbol{b}_{i}=\left[x_{i}, y_{i}, w_{i}, h_{i}\right];
- 相应的标签向量;
在\mathcal{O}上构造图\mathcal{G}^{V}=\left(\mathcal{V}^{V}, \mathcal{E}^{V}\right),其中\mathcal{V}^{V}=\left\{v_{i}^{V}\right\}_{i=1}^{K}是节点集合(node set)
同时我们也对 edge feature(代表两个对象之间的相对空间关系)进行编码\boldsymbol{r}_{i j}^{V}=\left[\frac{x_{j}-x_{i}}{w_{i}}, \frac{y_{j}-y_{i}}{h_{i}}, \frac{w_{j}}{w_{i}}, \frac{h_{j}}{h_{i}}, \frac{w_{j} h_{j}}{w_{i} h_{i}}\right]
==Semantic Graph Construction==(语义图构建)
除了视觉信息外,自然语言(文本信息)可以对目标对象和其之间的关系进行高级抽象(可以提供了高层的语义信息)。这样做的目的就是将图像中的视觉对象和question and fact 中所提到的概念联系起来。
在这里我们使用dense captions生成D个图像局部(local-level)的描述,包括单个目标对象的属性描述或者目标间的关系描述,Z=\left\{z_{i}\right\}_{i=1}^{D},每个描述z_i对应着图像中的一小部分区域。没有用全局的image caption模型是因为可能会损失掉一些细粒度地信息。
得到了关于图像的文本描述之后,就是如何将这些文本建成图,这里使用的是SPICE。SPICE是在image caption任务中用于验证生成的caption的准确率。它会对生成的caption转化成一个graph(下图左边),然后对原来的caption也转化成graph(下图右边),然后计算图的匹配程度来对生成的caption进行打分。

生成语义图\mathcal{G}^{S}=\left(\mathcal{V}^{S}, \mathcal{E}^{S}\right),其中,v_{i}^{S} \in \mathcal{V}^{S},v_{i}^{S}从生成captions中提取到的目标对象的name或者是attribute;e_{i j}^{S} \in \mathcal{E}^{S}是v_{i}^{S},v_{j}^{S}之间的关系;我们使用averaged Glove表示。图的表示保留了概念之间的关系信息,并在图域中统一表示,更好地进行跨模态的显式推理。

==Fact Graph Construction==(事实图构建)

为了找到合适的支撑事实,首先按照论文《Out of the box: Reasoning with graph convolution nets for factual visual question answering》中提出的基于评分的方法,从知识库中检索相关的候选事实。对于每一个事实<e1,r,e2>,图像的视觉概念o1,o2,…o36,我们首先计算e1,e2和o1,o2,…o36之间的余弦相似度,其中e1,e2和o1,o2,…o36都用GloVe来表示。把所有的值求平均就得到当前事实<e1,r,e2>的分数,然后把所有的事实按照分数从高到底排序,取前100个事实,记做f_{100};
接着对f_{100}进一步的过滤。同时我们训练了一个问题的类别分类器,输入问题,就会预测对应事实的关系r_i,然后取前三个预测到的关系进一步过滤候选事实,得到f_{rel}。在f_{rel}的基础上构建事实图\mathcal{G}^{F}=\left(\mathcal{V}^{F}, \mathcal{E}^{F}\right)。其中e1,e2是图中的节点,r是图中的边。节点和边的特征都使用GloVe词向量来表示。这样通过联合考虑事实图中的所有实体,可以有效地利用事实之间的拓扑结构。(The topological structure among facts can be effectively exploited by jointly considering all the entities in the fact graph.)
==Intra-Modal Knowledge Selection==(模态内知识选择)

因为图的每一层都包含与问题相关的特定于模态的知识,因此我们首先通过Visual-to-Visual Convolution, Semantic-to-Semantic Convolution和Fact-to-Fact Convolution从视觉图,语义图和事实图中独立选择有价值的线索。我们使用使用注意力机制突出与问题最为相关的节点和边,然后通过模态内的图卷积对节点表示进行更新。
==These three convolutions share the common operations.==
-
Question-guided Node Attention
首先我们根据问题q(由LSTM编码得到)对每个节点进行了attention操作。这样每个节点就会计算得到一个权重\alpha,与问题更相关的节点,它的权重就会越高。

-
Question-guided Edge Attention
接下来根据问题对每条边进行了attention操作。具体以每个节点v_i为中心节点,计算每个邻居节点和它以及问题的重要程度,q’包含了中心节点和问题的特征,v’_j包含了邻居节点和边的特征。(为什么要这么设置呢?)


-
Intra-Modal Graph Convolution
在得到节点和边的重要程度之后进行模态内的图卷积操作,先对邻居节点进行求和,然后再和本身的特征进行融合,根据节点和边的重要程度进行了加强。

将上述的模态内知识选择过程分别作用在三个图上,得到更新后的节点表示,分别记为:






==Cross-Modal Knowledge Reasoning==(跨模态知识推理)
为了正确回答问题,需要充分考虑来自视觉,语义和事实信息之间的互补信息。由于答案来自事实图中的一个实体(为什么呢?),因此我们通过跨模态卷heih积(包括visual-to-fact convolution和semantic- to-fact convolution)从视觉图和语义图到事实图收集互补信息。最后,对互补信息进行融合,应用图卷积操作形成全局决策。
-
Visual-to-Fact Convolution
对于事实图中的每个节点v_{j}^F,计算视觉图中每个节点v_{j}^V和它的相似度分数,越互补的节点它的相似度分数就越高,然后根据分数对视觉图加权求和得到视觉的互补信息。
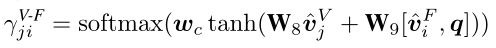

-
Semantic-to-Fact Convolution
同理可以得到语义的互补信息。再得到语义的互补信息和视觉的互补信息后,使用Gate方式对视觉语义的互补信息和实体特征进行融合。


-
Fact-to-Fact Aggregation
给定事实图中的一组候选实体,我们旨在全局比较所有实体并选择一个最佳实体作为答案。现在,事实图中每个实体从三种模态中收集了问题导向以及相互互补的信息。为了联合评估每个实体的可能性,我们进行类似于3.2节中介绍的基于注意力的图卷积网络,用来汇总事实图中的信息并获得更新后的实体表示。
我们迭代地进行模态内的知识选择和模态间的知识推理过程,经过T步,获得了最终的实体表示。
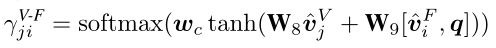



Learning(==待讨论==)
每个实体只有两种结果,是或不是答案。因此我们将事实图中每个实体的表示和问题的嵌入拼接,然后输入到一个二分类中,输出概率最高的实体当做预测的答案。


Experiments
-
数据集
FVQA
-
实验结果和消融

-
可视化推理过程
节点中的值对应模态内知识选择的α,边上的值对应β,虚线上的值对应跨模态卷积的γ,热力条是通过最后融合时的gate值得到的。




