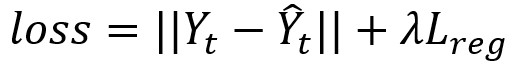Java爬取先知论坛文章
Java爬取先知论坛文章
0x00 前言
上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码。
0x01 代码实现
pom.xml加入依赖:
<dependencies>
<!-- //mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.3</version>
</dependency>
<!-- //mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
<!-- //mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
<!-- //mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<!-- //mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
实现代码
实现类:
package xianzhi;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.util.List;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Climbimpl implements Runnable {
private String url ;
private int pages;
private String filename;
Lock lock = new ReentrantLock();
public Climbimpl(String url, int pages,String filename) {
this.url = url;
this.pages = pages;
this.filename = filename;
}
public void run() {
File file = new File(this.filename);
boolean mkdir = file.mkdir();
if (mkdir){
System.out.println("目录已创建");
}
lock.lock();
// String url = "//xz.aliyun.com/";
for (int i = 1; i < this.pages; i++) {
try {
String requesturl = this.url+"?page="+i;
Document doc = null;
doc = Jsoup.parse(new URL(requesturl), 10000);
Elements element = doc.getElementsByClass("topic-title");
List<String> href = element.eachAttr("href");
for (String s : href) {
try{
Document requests = Jsoup.parse(new URL(this.url+s), 100000);
// String topic_content = requests.getElementById("topic_content").text();
String titile = requests.getElementsByClass("content-title").first().text();
System.out.println("已爬取"+titile+"->"+this.filename+titile+".html");
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(this.filename+titile+".html"));
bufferedOutputStream.write(requests.toString().getBytes());
bufferedOutputStream.flush();
bufferedOutputStream.close();
}catch (Exception e){
System.out.println("爬取"+this.url+s+"报错"+"报错信息"+e);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
lock.unlock();
}
}
main类:
package xianzhi;
public class TestClimb {
public static void main(String[] args) {
int Threadlist_num = 10; //线程数
String url = "//xz.aliyun.com/"; //设置url
int pages = 10; //读取页数
String path = "D:\\paramss\\"; //设置保存路径
Climbimpl climbimpl = new Climbimpl(url,pages,path);
for (int i = 0; i < Threadlist_num; i++) {
new Thread(climbimpl).start();
}
}
}
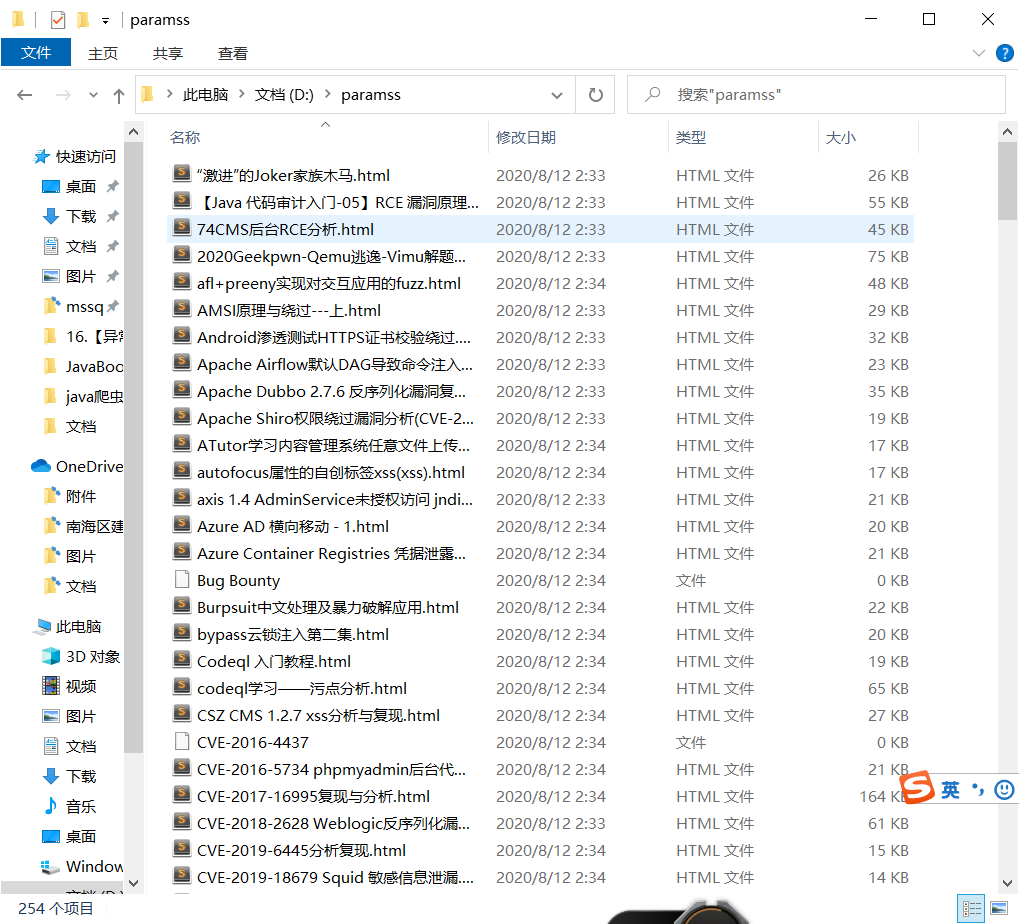
0x03 结尾
该爬虫总体的代码都比较简单。