通过手写服务器的方式,立体学习Http
前言
Http我们都已经耳熟能详了,而关于Http学习的文章网上有很多,各个知识点的讲解也可说是深入浅出。然而,学习过后,我们对Http还是一知半解。问题出在了哪?
Http是一个客户机与服务器之间的通信的协议,真的想学习Http,就必须把客户机和服务器也学了,也就是说,必须立体的学习,不然我们永远都是一知半解。
现在,我们手工搭建一个服务器,立体的学习下Http,将我们以为的知识点连成线。
定义
学习前,简单的了解下定义:
Http是超文本传输协议,用于保证客户机与服务器之间的通信。在客户机和服务器之间进行请求-响应时,两种最常被用到的方法是:GET 和 POST。
-
GET – 从指定的资源请求数据。
-
POST – 向指定的资源提交要被处理的数据(向指定资源“追加/添加”数据。)
搭建Http服务器
首先我们通过HttpListener来搭建一个简易的Http服务器,代码如下:
class Program
{
static HttpListener httpListener;
static volatile bool isRun = true;
static void Main(string[] args)
{
Listener(5180);
}
public static void Listener(int port)
{
//创建HTTP监听
httpListener = new HttpListener();
//监听的路径
httpListener.Prefixes.Add($"//localhost:{port}/");
httpListener.Prefixes.Add($"//127.0.0.1:{port}/");
//设置匿名访问
httpListener.AuthenticationSchemes = AuthenticationSchemes.Anonymous;
//开始监听
httpListener.Start();
while (isRun)
{
//等待传入的请求接受到请求时返回,它将阻塞线程,直到请求到达
var context = httpListener.GetContext();
//取得请求的对象
HttpListenerRequest request = context.Request;
Console.WriteLine($"请求模式:{request.HttpMethod}");
var reader = new StreamReader(request.InputStream, Encoding.UTF8);
var msgSource = reader.ReadToEnd();//读取传过来的信息+
Console.WriteLine($"msgSource:{msgSource}");
var msg = Uri.UnescapeDataString(msgSource);
Console.WriteLine($"请求msg:{msg}");
string responseString = "返回值";
// 取得回应对象
HttpListenerResponse response = context.Response;
// 设置回应头部内容,长度,编码
response.ContentEncoding = Encoding.UTF8;
response.ContentType = "text/plain; charset=utf-8";
response.Headers.Add("Access-Control-Allow-Origin", "*");
response.Headers.Add("Cache-Control", "no-cache");
byte[] buff = Encoding.UTF8.GetBytes(responseString);
// 输出回应内容
System.IO.Stream output = response.OutputStream;
output.Write(buff, 0, buff.Length);
// 必须关闭输出流
output.Close();
}
}
}
服务器搭建已经搭建完成了,现在,我们通过代码从新学习一下Http定义。
代码学习
首先我们看到,httpListener.GetContext()阻塞了线程;只有请求到达时,线程才会继续运行,请求到达时,我们将会得到一个HttpListenerRequest的请求对象。
HttpListenerRequest对象包含了请求的地址栏参数QueryString、Cookies、请求头Header等等信息。
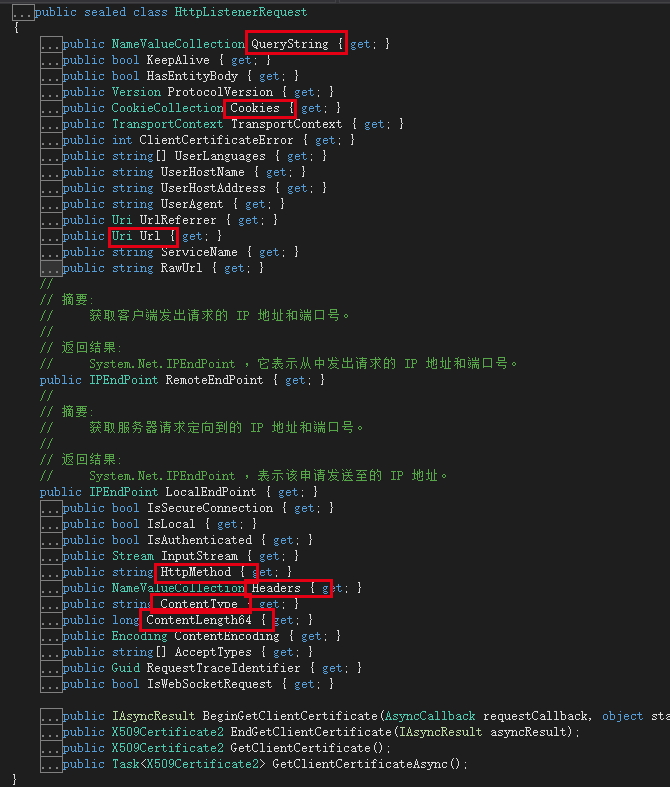
Get请求
Get请求很简单,Get请求的数据就写在地址栏,所以我们直接可以使用HttpListenerRequest对象的QueryString来读取到,如下:
HttpListenerRequest request = context.Request; //取得请求的对象
Console.WriteLine($"请求模式:{request.HttpMethod}");
var abc = request.QueryString["abc"];
Console.WriteLine($"Get请求abc的值:{abc}");
运行Host项目,测试如下图所示:
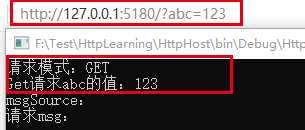
Post请求
学习了上面的代码,我想一定有人对下面这句话感到疑惑。
var reader = new StreamReader(request.InputStream, Encoding.UTF8);
为什么请求已经到了,还要去读请求中的InputStream属性呢?
我们重新看下Post的定义:向指定的资源提交要被处理的数据(向指定资源“追加/添加”数据。)。
定义太不好理解,我们翻译一下;Post的请求是先发起,一个TCP连接,然后再将数据,写入请求的InputStream属性中。
现在我们编写一个Http的Post请求,加深理解。
public static void Post(string url, string param, Action<string> callback)
{
new Task(() =>
{
try
{
//转换输入参数的编码类型,获取bytep[]数组
byte[] byteArray = Encoding.UTF8.GetBytes(param);
//初始化新的webRequst
//1. 创建httpWebRequest对象
HttpWebRequest webRequest = (HttpWebRequest)WebRequest.Create(new Uri(url));
//2. 初始化HttpWebRequest对象
webRequest.Method = "POST";
webRequest.ContentType = "application/x-www-form-urlencoded";
webRequest.ContentLength = byteArray.Length;
//3. 附加要POST给服务器的数据到HttpWebRequest对象(附加POST数据的过程比较特殊,它并没有提供一个属性给用户存取,需要写入HttpWebRequest对象提供的一个stream里面。)
Stream newStream = webRequest.GetRequestStream();//创建一个Stream,赋值是写入HttpWebRequest对象提供的一个stream里面
newStream.Write(byteArray, 0, byteArray.Length);
newStream.Close();
//4. 读取服务器的返回信息
using (HttpWebResponse response = (HttpWebResponse)webRequest.GetResponse())
{
using (StreamReader stream = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string ret = stream.ReadToEnd();
callback(ret);
}
}
}
catch (Exception ex)
{
callback("异常:" + ex.Message);
}
}).Start();
}
可以看到,请求时,就是从指定IP地址中创建一个WebRequest对象(通过WebRequest.Create创建),然后再获取对象的请求流—GetRequestStream(),即服务端的InputStream,再向其流里写人数据。
现在我们编写一个Winform项目,测试一下Post请求,结果如下:
扩展1:Http本质上是TCP,也就是说Get请求,不去读取InputStream里的值,是被框架处理的结果呈现,如果框架处理了Get请求的InputStream,那么Get请求就也可以像Post那样,获取请求中的InputStream,然后向流里写入数据。这就是为什么有的框架Get请求也可以发送Json对象的原因。
扩展2:Post请求需要读取InputStream,也就是说,每次的Post都需要实例化一个Tcp对象去处理流,而Get请求不去读InputStream,就不用实例化Tcp了,也就是说Get请求的内存消耗更少,同理,上文提到的Get请求发送Json对象,就等于把Get请求变成了Post请求,即,大量消耗了内存,所以,如果网站需要性能好一点的话,就尽量不考虑使用这样的框架。
扩展3:在Post请求中,我们把写入InputStream的数据称为Content,而在HttpListenerRequest类的截图中,我们可以看到这三个属性ContentLength64,ContentType,ContentEncoding,他们代表着,Content的长度、类型、编码,也就是说,如果我们手写Post请求,这三个值一定要服务器解析时配置的值对上,当然,他们也都是有默认值的。通常服务器都会支持多种ContentType类型,如application/x-www-form-urlencoded或application/json,具体各种类型的数据格式,大家可以自行了解。
扩展4:MVC和WebApi都是在Http解析后执行的,也就是或,服务器先解析了Http,然后才根据请求的Url解析跳转到指定Controler和Action,然后再实例化Controler和Action时,在把相应的参数传递过去。
请求乱码
在客户端Http发起请求时,英文字母,数字会原样发送,而中文和其他字符,则直接把字符串用BASE64加密,如:%E5%95%8A%20%E4%B8%8D。这种行为,我们称之为字符串转义。
同理,在服务器端,我们需要将请求的字符串解析回来,如Uri.UnescapeDataString(msgSource)。
那为什么会有乱码?
我们会发现,乱码出现的地方都是中文和特殊字符,那么结合上文所述,我们就知道乱码出现的原因了。
两种情况,一种是框架没有做解析,或者解析失败,直接把客户端的转义后的请求发给了你;另一种是客户端和服务器的解析类型没对上,进行了错误的解析。
不过,通常情况下,服务器会替我们做好解码的工作。
跨域
上文中,我们看到在输出返回数据的时候,我们为HttpListenerResponse对象的Headers属性增加了个键值对,如下:
response.Headers.Add("Access-Control-Allow-Origin", "*");
没错,这个是跨域的配置,我们在Response输出时,进行了Access-Control-Allow-Origin配置,这样,浏览器在接受到我们的返回消息时,就不会阻止它们显示了。
结语
立体的学习了Http后,我们才能更好,更快的学习Http协议,一些以前我们很难理解的解释,也可以慢慢想通了,比如Connection: keep-alive,我们现在就能更好的理解了,它就是Http请求后,不去释放Tcp对象,这样,它下一次传输数据就不用新建内存了。
—————————————————————————————————-
到此HTTP的立体学习已经介绍完了,代码已经传到Github上了,欢迎大家下载。
代码已经传到Github上了,欢迎大家下载。
Github地址://github.com/kiba518/HttpLearning
—————————————————————————————————-
注:此文章为原创,任何形式的转载都请联系作者获得授权并注明出处!
若您觉得这篇文章还不错,请点击下方的【推荐】,非常感谢!
//www.cnblogs.com/kiba/p/13258817.html



