这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频
之前介绍了如何构建一个推荐系统,今天给大家介绍如何基于用户的协同过滤来构建推荐的实战篇。
协同过滤技术在推荐系统中应用的比较广泛,它是一个快速发展的研究领域。它比较常用的两种方法是基于内存(Memory-Based)和基于模型(Model-Based)。
为了解决这些问题,可以通过建立协同过滤模型,利用购买数据向客户推荐产品。下面,我们通过基于用户的协同过滤(基于内存),通过实战来一步步实现其中的细节。基于用户的系统过滤体现在具有相似特征的人拥有相似的喜好。比如,用户A向用户B推荐了物品C,而B购买过很多类似C的物品,并且评价也高。那么,在未来,用户B也会有很大的可能会去购买物品C,并且用户B会基于相似度度量来推荐物品C。
这种方式识别与查询用户相似的用户,并估计期望的评分为这些相似用户评分的加权平均值。实战所使用的Python语言,这里需要依赖的库如下:
Python环境:
这里给非个性化协同过滤(不包含活跃用户的喜欢、不喜欢、以及历史评分),返回一个以用户U和物品I作为输入参数的分数。该函数输出一个分数,用于量化用户U喜欢 / 偏爱物品I的程度。这通常是通过对与用户相似的人的评分来完成的。涉及的公式如下:
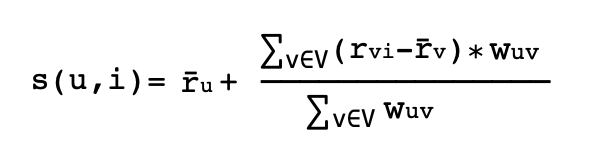
这里其中s为预测得分,u为用户,i为物品,r为用户给出的评分,w为权重。在这种情况下,我们的分数等于每个用户对该项目的评价减去该用户的平均评价再乘以某个权重的总和,这个权重表示该用户与其他用户有多少相似之处,或者对其他用户的预测有多少贡献。这是用户u和v之间的权重,分数在0到1之间,其中0是最低的,1是最高的。理论上看起来非常完美,那为啥需要从每个用户的评分中减去平均评分,为啥要使用加权平均而不是简单平均?这是因为我们所处理的用户类型,首先,人们通常在不同的尺度上打分,用户A可能是一个积极乐观的用户,会给用户A自己喜欢的电影平均高分(例如4分、或者5分)。而用户B是一个不乐观或者对评分标准比较高的用户,他可能对最喜欢的电影评分为2分到5分之间。用户B的2分对应到用户A的4分。改进之处是可以通过规范化用户评分来提高算法效率。一种方法是计算s(u,i)的分数,它是用户对每件物品的平均评价加上一些偏差。通过使用余弦相似度来计算上述公式中给出的权重,同时,按照上述方式对数据进行归一化,在pandas中进行一些数据分析。
import pandas as pd import numpy as np from sklearn.metrics.pairwise import cosine_similarity from sklearn.metrics import pairwise_distances
加载数据示例代码如下所示:
movies = pd.read_csv("data/movies.csv") Ratings = pd.read_csv("data/ratings.csv") Tags = pd.read_csv("data/tags.csv")
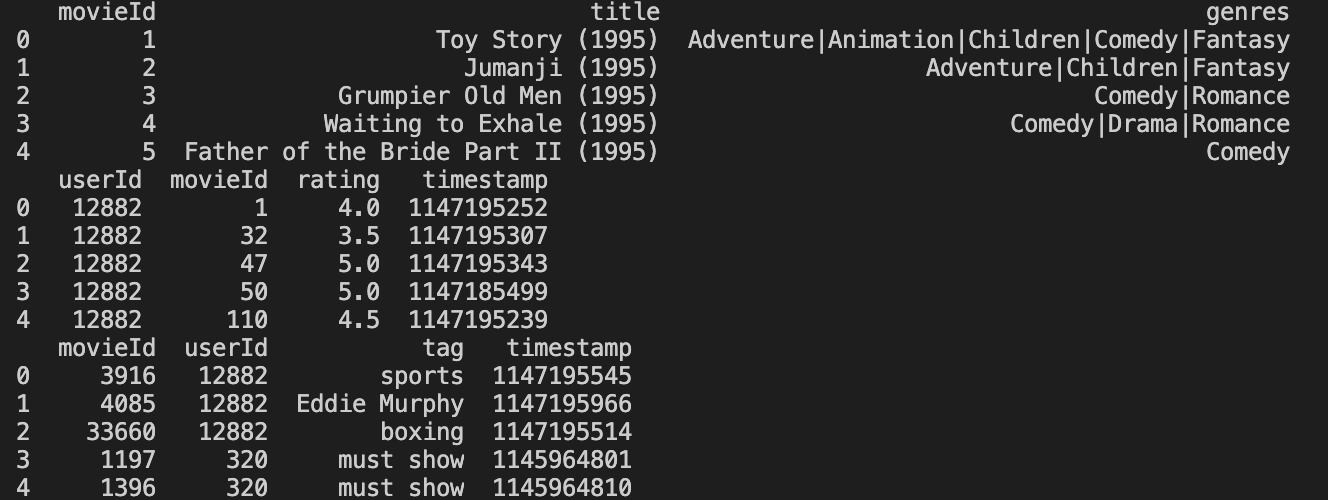
结果预览如下:
print(movies.head()) print(Ratings.head()) print(Tags.head())
构建数据:
Mean = Ratings.groupby(by="userId", as_index=False)['rating'].mean() Rating_avg = pd.merge(Ratings, Mean, on='userId') Rating_avg['adg_rating'] = Rating_avg['rating_x'] - Rating_avg['rating_y'] print(Rating_avg.head())
结果如下:

对于上面的公式,我们需要找到有相似想法的用户。找到一个喜欢和不喜欢的用户听起来很有意思,但是我们如何找到相似性呢?那么这里我们就需要用到余弦相似度,看看用户有多相似。它通常是根据用户过去的评分来计算的。
这里使用到Python的的sklearn的cosine_similarity函数来计算相似性,并做一些数据预处理和数据清洗。实例代码如下:
check = pd.pivot_table(Rating_avg,values='rating_x',index='userId',columns='movieId') print(check.head()) final = pd.pivot_table(Rating_avg,values='adg_rating',index='userId',columns='movieId') print(final.head())
结果如下:
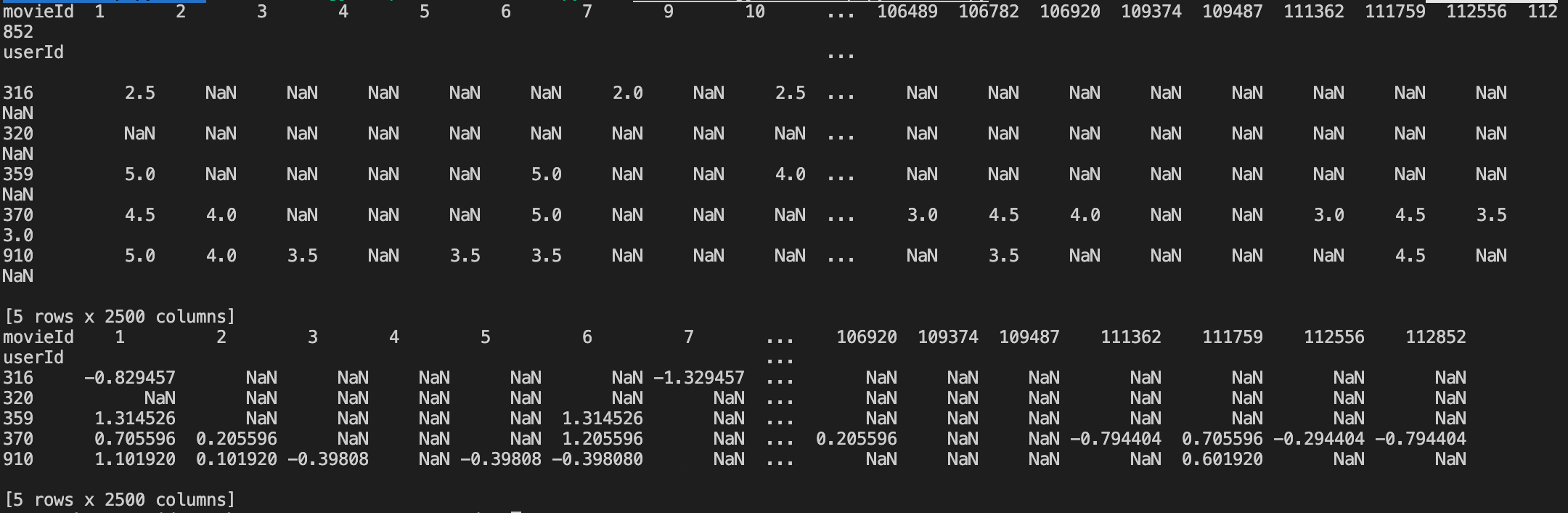
上图中包含了很多NaN的值,这是因为每个用户都没有看过所有的电影,所以这种类型的矩阵被称为稀疏矩阵。类似矩阵分解的方法被用来处理这种稀疏性,接下来,我们来对这些NaN值做相关替换。
这里通常有两种方式:
代码如下:
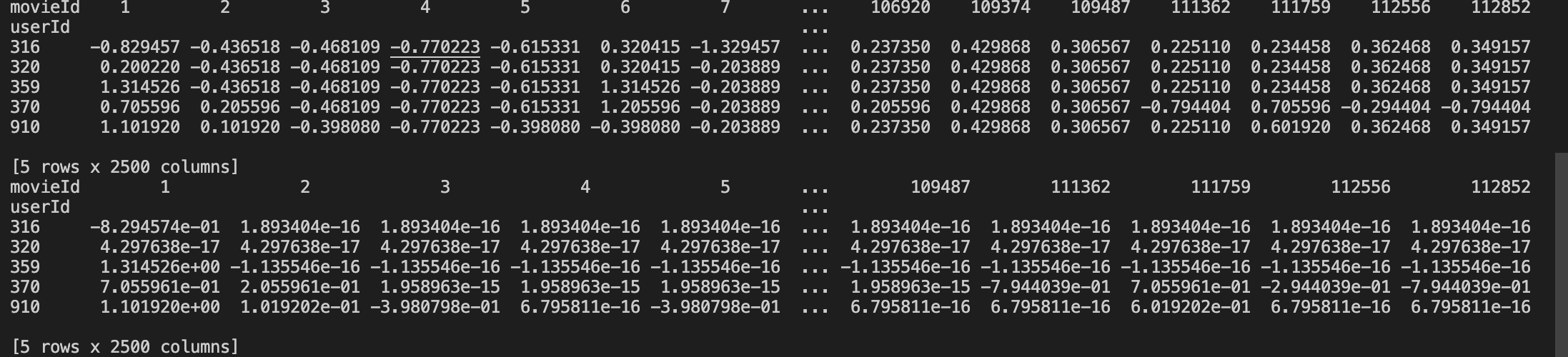
# Replacing NaN by Movie Average final_movie = final.fillna(final.mean(axis=0)) print(final_movie.head()) # Replacing NaN by user Average final_user = final.apply(lambda row: row.fillna(row.mean()), axis=1) print(final_user.head())
结果如下:
接着,我们开始计算用户之间的相似性,代码如下:
# user similarity on replacing NAN by item(movie) avg cosine = cosine_similarity(final_movie) np.fill_diagonal(cosine, 0) similarity_with_movie = pd.DataFrame(cosine, index=final_movie.index) similarity_with_movie.columns = final_user.index # print(similarity_with_movie.head()) # user similarity on replacing NAN by user avg b = cosine_similarity(final_user) np.fill_diagonal(b, 0 ) similarity_with_user = pd.DataFrame(b,index=final_user.index) similarity_with_user.columns=final_user.index # print(similarity_with_user.head())
结果如下:
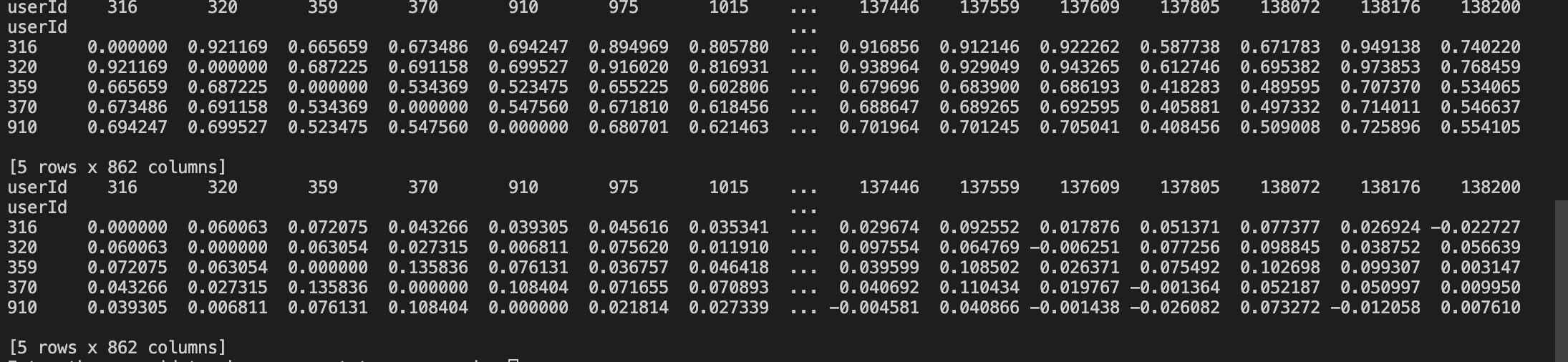
然后,我们来检验一下我们的相似度是否有效,代码如下:
def get_user_similar_movies( user1, user2 ): common_movies = Rating_avg[Rating_avg.userId == user1].merge( Rating_avg[Rating_avg.userId == user2], on = "movieId", how = "inner" ) return common_movies.merge( movies, on = 'movieId' ) a = get_user_similar_movies(370,86309) a = a.loc[ : , ['rating_x_x','rating_x_y','title']] print(a.head())
结果如下:

从上图中,我们可以看出产生的相似度几乎是相同的,符合真实性。
在2.3中计算了所有用户的相似度,但是在大数据领域,推荐系统与大数据相结合是至关重要的。以电影推荐为例子,构建一个矩阵(862 * 862),这个与实际的用户数据(百万、千万或者更多)相比,这是一个很小的矩阵。因此在计算任何物品的分数时,如果总是查看所有其他用户将不是一个好的解决方案或者方法。因此,采用相邻用户的思路,对于特定用户,只取K个类似用户的集合。
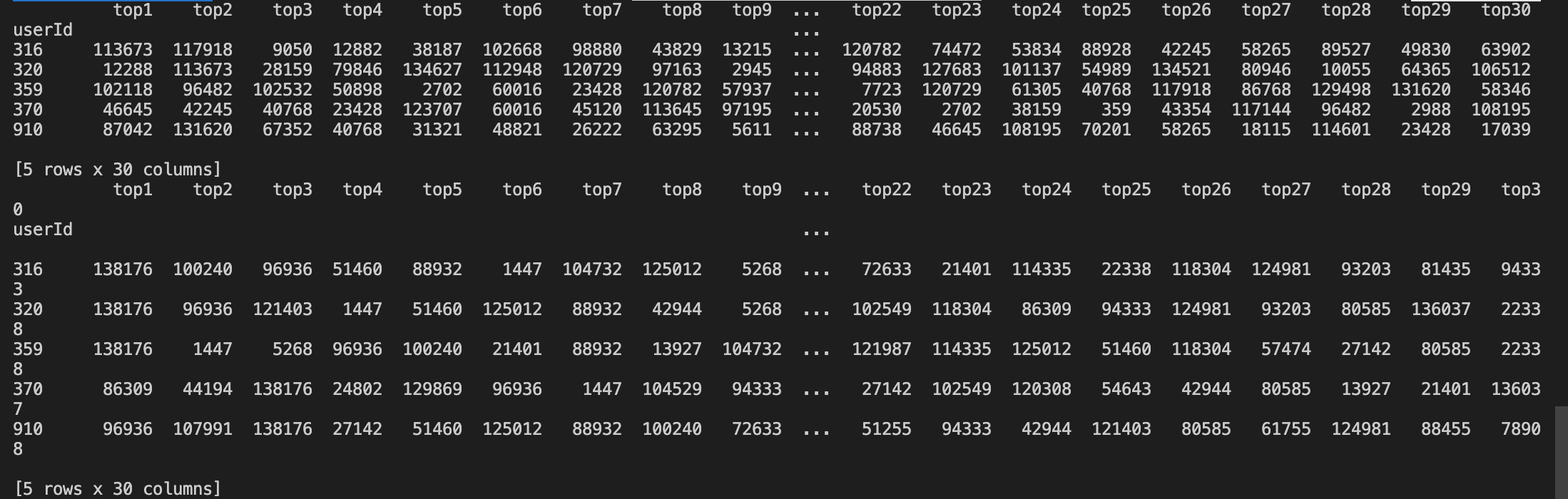
下面,我们对K取值30,所有的用户都有30个相邻用户,代码如下:
def find_n_neighbours(df,n): order = np.argsort(df.values, axis=1)[:, :n] df = df.apply(lambda x: pd.Series(x.sort_values(ascending=False) .iloc[:n].index, index=['top{}'.format(i) for i in range(1, n+1)]), axis=1) return df # top 30 neighbours for each user sim_user_30_u = find_n_neighbours(similarity_with_user,30) print(sim_user_30_u.head()) sim_user_30_m = find_n_neighbours(similarity_with_movie,30) print(sim_user_30_m.head())
结果如下:
实现代码如下所示:
def User_item_score(user,item): a = sim_user_30_m[sim_user_30_m.index==user].values b = a.squeeze().tolist() c = final_movie.loc[:,item] d = c[c.index.isin(b)] f = d[d.notnull()] avg_user = Mean.loc[Mean['userId'] == user,'rating'].values[0] index = f.index.values.squeeze().tolist() corr = similarity_with_movie.loc[user,index] fin = pd.concat([f, corr], axis=1) fin.columns = ['adg_score','correlation'] fin['score']=fin.apply(lambda x:x['adg_score'] * x['correlation'],axis=1) nume = fin['score'].sum() deno = fin['correlation'].sum() final_score = avg_user + (nume/deno) return final_score score = User_item_score(320,7371) print("score (u,i) is",score)
结果如下:

这里我们算出来的预测分数是4.25,因此可以认为用户(370),可能喜欢ID(7371)的电影。接下来,我们给用户(370)做电影推荐,实现代码如下:
Rating_avg = Rating_avg.astype({"movieId": str})
Movie_user = Rating_avg.groupby(by = 'userId')['movieId'].apply(lambda x:','.join(x))
def User_item_score1(user):
Movie_seen_by_user = check.columns[check[check.index==user].notna().any()].tolist()
a = sim_user_30_m[sim_user_30_m.index==user].values
b = a.squeeze().tolist()
d = Movie_user[Movie_user.index.isin(b)]
l = ','.join(d.values)
Movie_seen_by_similar_users = l.split(',')
Movies_under_consideration = list(set(Movie_seen_by_similar_users)-set(list(map(str, Movie_seen_by_user))))
Movies_under_consideration = list(map(int, Movies_under_consideration))
score = []
for item in Movies_under_consideration:
c = final_movie.loc[:,item]
d = c[c.index.isin(b)]
f = d[d.notnull()]
avg_user = Mean.loc[Mean['userId'] == user,'rating'].values[0]
index = f.index.values.squeeze().tolist()
corr = similarity_with_movie.loc[user,index]
fin = pd.concat([f, corr], axis=1)
fin.columns = ['adg_score','correlation']
fin['score']=fin.apply(lambda x:x['adg_score'] * x['correlation'],axis=1)
nume = fin['score'].sum()
deno = fin['correlation'].sum()
final_score = avg_user + (nume/deno)
score.append(final_score)
data = pd.DataFrame({'movieId':Movies_under_consideration,'score':score})
top_5_recommendation = data.sort_values(by='score',ascending=False).head(5)
Movie_Name = top_5_recommendation.merge(movies, how='inner', on='movieId')
Movie_Names = Movie_Name.title.values.tolist()
return Movie_Names
user = int(input("Enter the user id to whom you want to recommend : "))
predicted_movies = User_item_score1(user)
print(" ")
print("The Recommendations for User Id : 370")
print(" ")
for i in predicted_movies:
print(i)
结果如下:

基于用户的协同过滤,流程简述如下:
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频


