python之词云与‘结巴’
- 2019 年 10 月 8 日
- 筆記
在python中,你的数据收集到了之后除了可以直接打开来看,做成表格看以外,还可以做词云。
第一次使用词云,需要先安装wordcloud的库
第一种:pip install wordcloud
第二种:pycharm-在setting中的project interpreter中右边的+号点击进去,然后输入wordcloud就可以安装了。

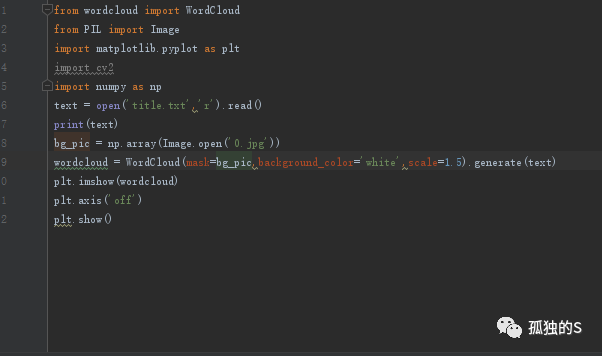
简单的一个wordcloud例子
大概过程就是:
导入库
打开文本文件,或者直接调用文本数据
然后设置底图
然后调用wordcloud中的WordCloud函数传入数据,设置数据。
显示出来
效果图:

词云中选用的数据是之前爬取知乎的python问题的题目。
底图是这个路飞的形状,然后数据也很好的契合到这个轮廓里面,如果的底图没有分明的轮廓,像这种图片有个白底的那样子的话,那个数据可能就会全覆盖了。
这里要安装的库有numpy,PIL,以及wordcloud和matplotlib,
因为这个wordcloud的generate是不支持中文格式的,于是引用一下windows的字体一下。

结果就成这样了。
引用的代码
wordcloud = WordCloud(
mask=bg_pic,background_color='white',scale=4,
font_path='C:WindowsFontssimhei.ttf').generate(text)
差不多就是最后一句了,这里是黑体,如果你要想要其他属性,可以进入这个目录:C:WindowsFonts,(这里是windows10,其他版本的目前没去测试)右键你要的字体然后看属性

然后就可以复制他的这个名字去调用了。
在这里,他的底图的调用有两种不同的情况
第一种,用cv2来获取图片
bg_pic = cv2.imread('0.jpg')
第二种,用PIL的Image模块来获取图片
bg_pic = np.array(Image.open('0.jpg'))
两种方法都是一样的,一开始我误解以为有不一样的效果,其实都一样。
jieba分词:
jieba是一款python中文组件
下面是一个简单例子:

安装
在pycharm貌似安装不了,但是可以直接用pip install jieba来安装。
然后import jieba 就可以使用了。
分词的方法就在上面的例子,很简单,不过不能直接print jieba.cut(text),需要用。join()来获取分完的结果。
jieba分词有三个特点:
精确模式:将句子最精确的切开,适合文本分析
全模式: 把句子中所有的可以成词的词语都扫描出来,速度很快,但是不能解决歧义
搜索引擎模式:
在精确模式的基础对长的词再次切分。适用于搜索引擎的分词。
这里就是简单介绍一下结巴分词和wordcloud,如果你想更深的去了解的话可以去网上找专门的介绍文档,或者教程。
