【主动学习】Variational Adversarial Active Learning
- 2019 年 10 月 12 日
- 筆記
本文记录了博主阅读ICCV2019一篇关于主动学习论文的笔记,第一篇博客,以后持续更新哈哈
论文题目:《Variational AdVersarial Active Learning》
原文地址:https://arxiv.org/pdf/1904.00370
开源地址:https://github.com/sinhasam/vaal
·摘要
主动学习旨在形成有效标记的算法,通过采样最有代表性的查询结果去使用标注专家标记。本文描述了一种基于池的半监督主动学习算法,以对抗的方式学习采样机制。通过使用一个变分自编码器学习一个潜码空间,然后使用对抗网络训练判别器区分数据是否被标记。VAE和判别器之间进行对抗学习:VAE的目标是让判别器预测所有的数据点都是来自于标记池的,判别器的目标是为了更好的区分是否是标记数据。对抗网络学习如何判断潜码空间的不相似性。作者在图像分类数据集(CIFAR10/100,Caltech-256,ImageNet)和分割数据集(Cityscapes,BDD100K)上进行评价。结果表明,本文对抗自编码器的方法可以学习一个有效的低维的潜码空间并提供一个计算高效的采样方法。
介绍
最近基于学习的计算机视觉方法取得的很大成功严重依赖于标注训练样本,可能需要花费很高的标注代价。为了解决这个问题,主动学习算法旨在增量的挑选注释的样本,使用尽可能少的标注样本得到更高的分类性能。主动学习需要的训练数据相对较少,可以用在图像分类和分割任务中。本文介绍了一个基于池的主动学习策略,通过使用变分自编码器从标记和未标记的数据中学习一个低维的潜码空间。
相关工作
主动学习:当前的方法主要分为基于池(查询获取)或查询合成方法。查询合成方法使用生成模型生成更具有信息的样本,然而查询获取使用不同的采样策略确定如何挑选最有信息量的样本,本文的方法就是基于查询获取的主动学习,主要介绍在这方面的相关工作。
基于池的方法分为三类:
1)基于不确定的方法:
2)基于表示的模型
3)二者相结合
变分自编码器:自编码器在特征空间和表示中广泛使用。
主动学习在语义分割方面的工作
Suggestive Annotation, Core-Sets,
方法概括
变分自编码器对抗学习的主动学习:
(XL,YL)表示标记池中的标记数据, (XU)表示未标记池中的数据。主动学习者的目标是训练最label-efficient的模型,通过迭代的查询一个固定的采样预算,从未标记池中挑选出最有代表性的b个样本,查询结束后使用oracle进行标注。
转导表示学习
本文使用β变分自编码器进行表示学习,编码器使用高斯先验可以学习一个潜在分布的低维空间,解码器可以重建输入的数据。为了捕捉有标记的数据在表示学习过程中丢失的特征,作者提出使用转导学习。这个目标函数β-VAE最小化样本边缘分布的变分下界,具体形式如下:

其中q和p分别表示编码器和解码器,p(z)是一个先验,β是优化问题的拉格朗日参数,同时为了更好的进行梯度优化使用了重新参数化技巧。
对抗表示学习
VAE的表征学习是一个关于标记数据和未标记数据潜在编码特征的混合。一个理想的主动学习方法假设有一个完美的采样策略能够将最有信息量的未标记样本发送给Oracle。大多数的采样策略依赖模型的不确定性,例如:模型对预测越不确定,未标记样本包含的信息越多。恰恰相反,本文通过训练一个对抗网络对于采样机制去学习如何区分在潜在空间的编码特征。主动学习中,对抗网络中将输入映射到潜码空间并且给一个标签,若样本来自标记数据,则为1,如果为未标记数据,则为0。本文的关键是使用对抗的方式。然而VAE匹配标记和未标记的数据到相同的具有相似概率分布的潜码空间,骗过判别器去分类所有的输入是标记的。另一方面,判别器尝试高效建立标记数据和未标记数据的分布。公式化如下:
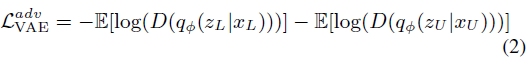
判别器的目标函数如下:

结合等式1和等式2,得到VAE的整个目标函数:
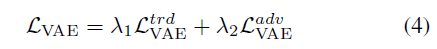
Lamda1和lamda2是两个超参数确定各个分量学习有效变分表示的效果
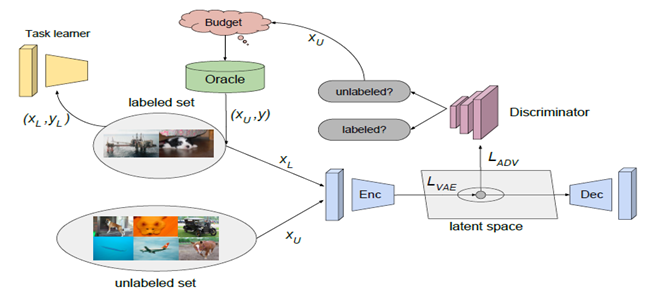
如上图所示,任务模块用T表示,学习主动学习者正在学习的任务。作者在图像分类和分割任务上做了对比试验,使用带有一个无权交叉熵损失函数的VGG16和DRN膨胀残差网络结构算法的流程如下:

采样策略和带噪声的Oracles
Oracle提供的标签的准确度取决于可利用的人类资源的素质。例如,医学图像注释被人类专家,专家是更准确的比非专家人员。本文的作者考虑了两种类型的Oracle:一个理想的Oracle,总是为主动学习者提供正确的标签,还有一个带有噪声的Oracle,非对抗的提供有错误的标签对于某些特定的类别,这可能发生由于一些类之间有很强的相似性,从而造成标注者是模糊的。为了呈现Oracle实际的效果,作者应用一个有针对性的噪声在一些容易混淆的类别上。VAAL采样策略的算法如下:使用与鉴别器的预测作为收集b个样本的分数,每个batch都挑选b个最低的自信度送给Oracle D判断出来越小的,越可能是未标记池中的数据。

实验
作者进行试验使用最初10%的标记数据的训练集,每个batch的b是整个训练集的5%。未标记数据的池中包含剩下的训练集。一旦被标记他们将被添加到初始的训练集并且在新的训练集上重复训练。我们认为Oracle是理想的(标注无误)
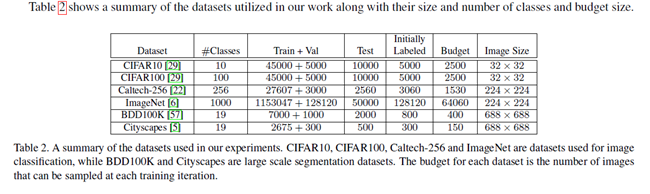
数据集:作者评价本文的方法在两个普通的视觉任务,图像分类中,使用CIFAR10和CIFAR100,都包含6万张32*32的图像,并且Caltech-256有30607张224*224的图像,包含256个类别。为了更好的验证VAAL的可扩展性,作者也在ImageNet上进行了实验,一共拥有1000类。在语义分割任务,在BDD100K和CityScapes中进行实验,都拥有19类。BDD100K是自动驾驶视频的数据集拥有10K图像。本文中用到的数据集统计如下图所示:
性能评价:图像分类中使用准确率,图像分割中使用平均交并比。T训练用训练集所有数目的10%,15%,20%,25%,30%,35%,40%。除了ImageNet上的实验,其它所有的实验都是平均运行5次。ImageNet上的实验是使用训练集的10%,15%,20%,25%,30%重复训练两次平均的结果。
性能比较
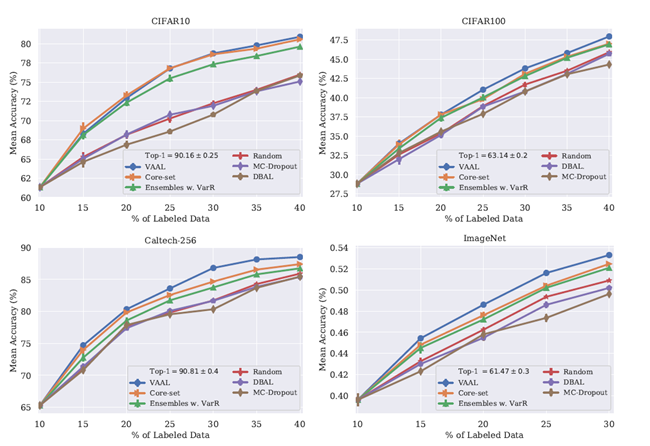
在分类任务上的结果
Baselines:在图像分类任务上与Core-set,Monte-Carlo Dropout和Ensembles using Variation Ratios进行比较。也展示了深度贝叶斯AL的表现性能并且使用其所提出的最大熵策略测量不确定性。我们展示了结果在未标记的池中随机均匀采样。这个方法仍然是一个比较有竞争力的baseline在主动学习中,此外,使用在整个数据集上的平均准确率作为上限,不符合主动学习情境。
在分割任务上的结果
Baselines:Core-set,MC-Dropout,QBC,SA(suggest annotation)
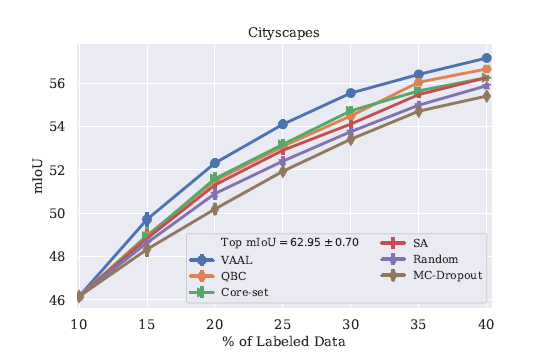
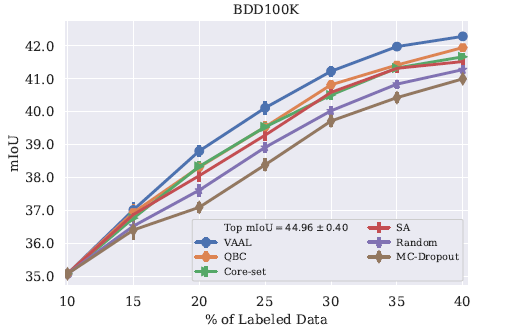
分析VAAL:
消融实验

如上图所示表示在BDD100K上进行消融实验,验证VAAL中关键模块的贡献,包括VAE,D。消融实验主要考虑:a)消除VAE;b)固定VAE,同时使用D;c)消除D
在a)中,通过仅仅使用判别器在图像空间训练区分标记和未标记数据来探索VAE在表示学习中的效果,如图所示,结果表明判别器仅仅记住了数据,并且产生了最低的性能。同时它表明VAE不仅仅是学习一个丰富的潜码空间,而且也会与判别器进行博弈,避免过拟合。
在b)中,作者为了训练D添加一个VAE在低维空间中编码和解码。然而,不训练VAE只是作为一个自编码器。这个结果是更好的比单独的D在图像空间上训练。但是仍然是更差的比随机采样,表明判别器失败学习未标记池的样本表示。
在c)中,作者验证判别器的效果,通过仅仅使用VAE训练,使用Wasserstein距离基于标记数据集的聚类中心测量不确定度;;两个分布的Wassertein距离公式如下:

在这个实验的效果比随机采样效果好,清楚的表明了在潜码空间测量不确定性的有效性。然而,VAAL通过在判别器和VAE之间的对抗学习清楚的学习了不确定性,效果远超过这三个方案
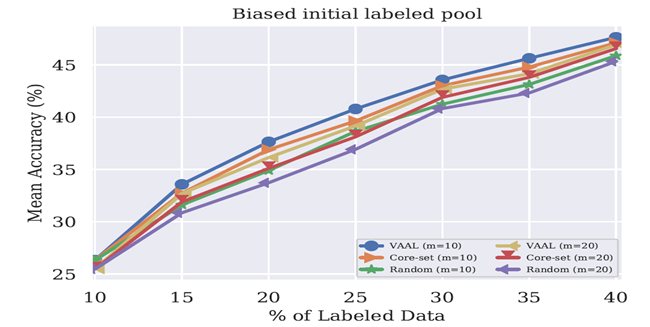
VAAL的鲁棒性
初始标记池中有偏差的标签效果:作者为了调查在初始标记池中偏置如何影响VAAL的性能,在CIFAR100上进行了实验。直觉上,偏置可以影响训练,因为他造成了最初的标记样本是没有代表性的,不足以代表潜在数据的分布,是不充足去涵盖潜码空间的大多数区域。作者模拟了一个可能的情况:对于m个随机选择的类,标记池中不提供这样标签的数据。与在所有的类别中随机采样进行对比。作者研究了m=10和m=20是如何影响模型的效果。如下如所示。
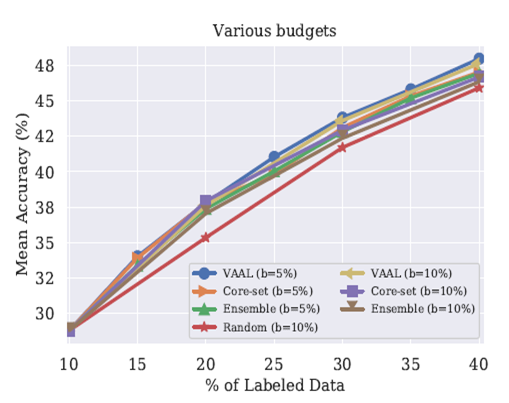
预算大小对性能的影响
如下图所示,与大多数Baseline比较的结果在CIFAR100上。主要比较了b=5%和b=10%的效果。
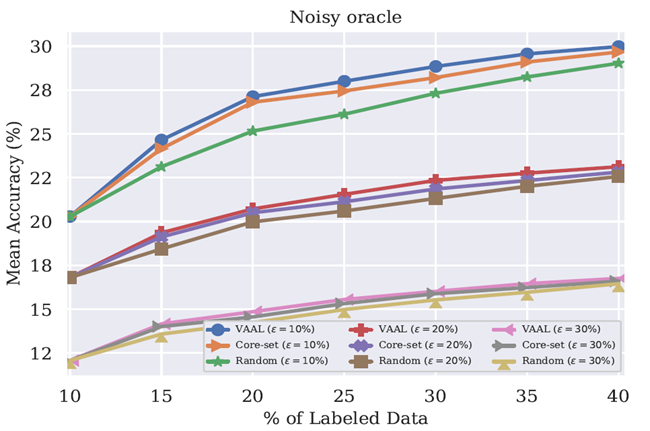
有噪音的Oracle
在这个分析中作者调查了由于不准确的Oracle导致有噪声的数据存在是如何影响VAAL的结果。作者认为错误的标签是因为一些类之间不容易区分,而不是对抗攻击。作者模仿在明确的类别上噪声,等同于人类错误的标记了一些容易混淆的类别。使用CIFAR100分析,由于100个类的层次结构,100个类别被分组成了20个超类。每个图像有一个超类和一个子类。作者通过随机的改变标签的真实值对于10%,20%,30%的训练集在相同的超类下有一定的错误标签。下图展示了有噪声的标记是如何影响算法的性能的。
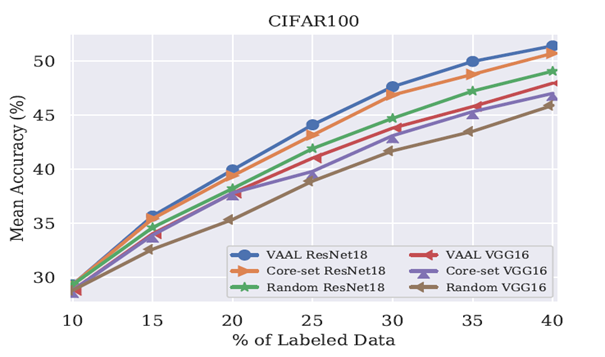
T中网络结构的选择
在分类的任务中,为了确保VAAL对VGG16的结构不敏感,作者也是用ResNet18进行实验。如图6所示。
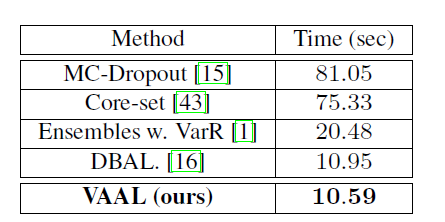
采样时间的分析
主动学习者的采样策略必须以快速的时间选择样本,考虑到随机采样仍然是一个有效的Baseline,它挑选样本的时间应该与随机采样比较接近。下面的表格展示了VAAL与Baseline的对比在CFFAR10上。
总结
这篇文章主要提出了一个批处理的主动学习算法,通过VAE与判别器之间的对抗学习来学习标记数据和未标记数据的潜码表示。同时,这篇文章做了大量的实验(我认为中oral的一部分原因)来验证VAAL的性能。
