Scrapy框架
- 2022 年 9 月 25 日
- 筆記
- Python, Web后端, 爬虫
一、Scrapy 介绍
Scrapy是一个Python编写的开源和协作的框架。起初是用于网络页面抓取所设计的,使用它可以快速、简单、可扩展的方式从网站中提取所需的数据。
Scrapy也是通用的网络爬虫框架,爬虫界的django(设计原则很像),可用于数据挖掘、监测和自动化测试、也可以应用在获取api所返回数据。
Scrapy是基于twisted框架开发而来,twisted是事件驱动python网络框架,因此scrapy使用的是非阻塞(异步)的代码来实现并发,可以发一堆请求出去(异步,不用等待),谁先回来就处理谁(事件驱动,发生变化再处理)。整体架构如下图
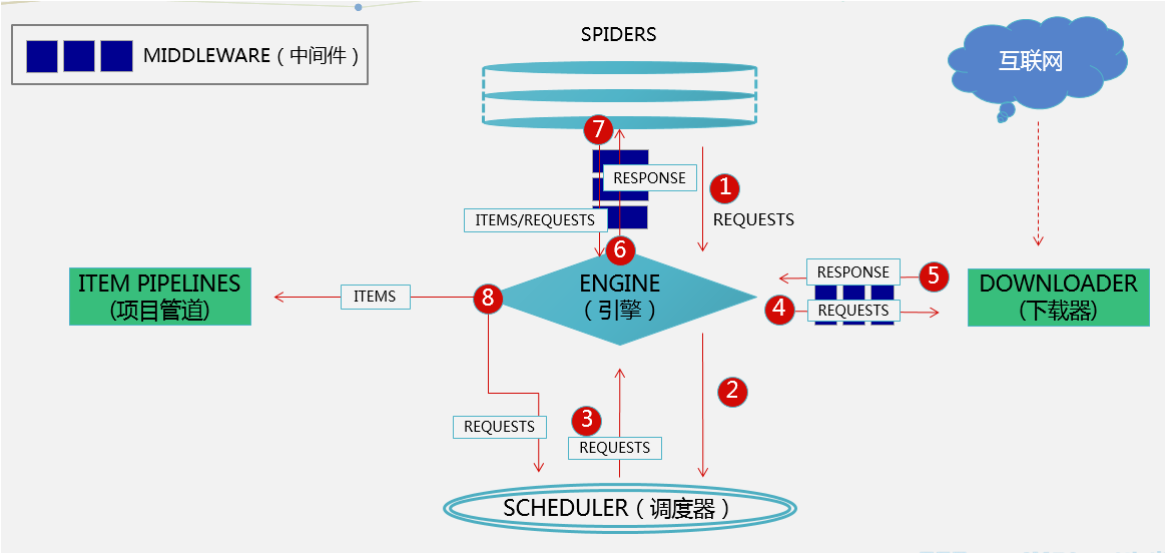
二、Scrapy 执行流程
五大组件
1、引擎(EGINE)
大总管,负责控制系统所有组件之间的数据流向,并在某些动作发生时触发事件
2、调度器(SCHEDULER)
由它来决定下一个要抓取的网址是什么,同时去除重复的网址(scrapy框架用的集合)
# 通过配置来实现这一堆请求按深度优先(一条url爬到底),还是广度优先(都先爬第一层,再往下爬)
# 先进先出(队列)-->第一层请求从调度器出去,爬虫解析后发出第二层请求,但要在队列等先进的其他第一层请求出去,因此需要把第一层先爬完,这是广度优先
# 后进先出(堆栈)-->出去的第一层经解析,发出第二层请求,进入调度器,它又先出去,一条线把它爬完,才能爬其他url请求,这是深度优先
3、下载器(DOWLOADER):用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 下载器前有一个下载中间件:用来拦截,这里就是包装requests对象的地方(加头、加代理)
4、爬虫(SPIDERS):开发人员自定义的类,用来解析responses,并且提取items对象(解析出来的内容),或者发送新的请求request(解析出要继续爬取的url)
5、项目管道(ITEM PIPLINES):在items被提取后负责处理它们,主要包括清洗(剔除掉不需要的数据)、验证、持久化(比如存到数据库、文件、redis)等操作
两大中间件
1、爬虫中间件:位于EGINE和SPIDERS之间,主要处理SPIDERS的输入(responses)和输出(requests),还包括items对象,处理的东西过多就需要先判断是哪个对象,用的很少
2、下载中间件:引擎和下载器之间,主要用来处理引擎传到下载器的请求request, 从下载器传到引擎的响应response;
可以处理加代理,加头,集成selenium; 它用的不是requests模块发请求,用的底层的urllib模块,因此不能执行js;
框架的灵活就在于,你可以在下载中间件自己集成selenium,拦截后走你的下载方式,拿到数据再包装成response对象返回;
# 开发者只需要在固定的位置写固定的代码即可(写的最多的spider)
三、安装
解决方法
1、pip3 install wheel
2、pip3 install lxml
3、pip3 install pyopenssl
4、下载并安装pywin32:它是windows上的exe执行文件
//sourceforge.net/projects/pywin32/files/pywin32/
5、下载twisted的wheel文件://www.lfd.uci.edu/~gohlke/pythonlibs/
6、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
7、pip3 install scrapy
-D:\Python39\Scripts\scrapy.exe 此文件用于创建项目(相当于安装完django有个django-admin.exe)
四、scrapy 创建项目,创建爬虫,运行爬虫
1 创建scrapy项目
scrapy startproject 项目名
eg: scrapy startproject firstscrapy (cmd先cd到项目创建的目录上再执行命令)
-项目创建后会生成firstscray文件夹,用pycharm打开,类似django项目的目录结构
2 创建爬虫
scrapy genspider 爬虫名 爬取地址
scrapy genspider chouti dig.chouti.com
一执行就会在spider文件夹下创建出一个py文件,名字叫chouti,爬虫就是一个个的py文件
执行命令-->生成py文件-->里面包含了初始代码,因此直接拷贝py文件改下里面的代码(爬虫名、地址),就相当于创建一个新的爬虫,新的py文件,django的app也可以这样操作
3 运行爬虫
方式一:通过命令启动爬虫
scrapy crawl chouti
scrapy crawl chouti --nolog
方式二:支持右键执行爬虫
from scrapy.cmdline import execute
execute(['scrapy','crawl','chouti','--nolog']) --->右键运行main.py文件
execute(['scrapy','crawl','baidu'])
注意:框架用了异常捕获,如果不带日志,有异常不会抛到控制台
scrapy框架爬网页会先去读robots.txt协议,如果网站不让爬,它就不爬了
可以在settings.py中,ROBOTSTXT_OBEY = True 改为False,不遵循它的协议
五、scrapy项目目录
firstscrapy
firstscrapy
-spiders
-baidu.py
-chouti.py
-middlewares.py
-pipelines.py
-main.py
-items.py
-settings.py
scrapy.cfg
六、settings介绍
1 默认情况,scrapy会去遵循爬虫协议
2 修改配置文件参数,强行爬取,不遵循协议 ROBOTSTXT_OBEY = False
3 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
4 LOG_LEVEL='ERROR' 日志等级配置为error,info信息不打印,可以带上日志运行
七、scrapy的数据解析(重点)
1 spiders爬虫
爬虫解析示例
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['//dig.chouti.com/']
def parse(self, response, *args, **kwargs):
print(response.text)
---------------------------------------
如果解析出一个网址,想继续爬取这个网址,需要调用Requset类传入url,生成requests对象并返回,它会继续走scrapy框架的流程
from scrapy.http import Request
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['//dig.chouti.com/']
def parse(self, response, *args, **kwargs):
print(response.text)
return Request('http:www.chouti.com/article.html/')
2 解析方案一:自己用第三方解析,用bs4,lxml
bs4解析
from bs4 import BeautifulSoup
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['//dig.chouti.com/']
def parse(self, response, *args, **kwargs):
print(response.text)
soup=BeautifulSoup(response.text, 'lxml')
div_list=soup.find_all(class_='link-title')
for div in div_list:
print(div.text)
3 解析方案二:scrapy框架自带的解析
css或xpath解析
xpath解析:
response.xpath('//a[contains(@class,"link-title")]')
response.xpath('//a[contains(@class,"link-title")]').extract()
response.xpath('//a[contains(@class,"link-title")]/text()').extract()
response.xpath('//a[contains(@class,"link-title")]/@href').extract()
css解析:
response.css('.link-title')
response.css('.link-title').extract()
response.css('.link-title::text').extract()
response.css('.link-title::attr(href)').extract()


