分布事务和分布式锁
分布式事务
1 两阶段提交
二阶段提交协议(Two-phase Commit,即 2PC)是常用的分布式事务解决方案,即将事务的提交过程分为两个阶段来进行处理:准备阶段和提交阶段
阶段 1:准备阶段
- 协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待所有参与者答复。
- 各参与者执行事务操作,将 undo 和 redo 信息记入事务日志中(但不提交事务)。
- 如参与者执行成功,给协调者反馈 yes,即可以提交;如执行失败,给协调者反馈 no,即不可提交
阶段 2:提交阶段
- 如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(rollback)消息;否则,发送提交(commit)消息。
- 参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源
2 三阶段提交
三阶段提交协议,是二阶段提交协议的改进版本,与二阶段提交不同的是,引入超时机制。同时在协调者和参与者中都引入超时机制
阶段 1:canCommit
- 协调者向参与者发送 commit 请求,参与者如果可以提交就返回 yes 响应(参与者不执行事务操作),否则返回 no 响应:
- 协调者向所有参与者发出包含事务内容的 canCommit 请求,询问是否可以提交事务,并等待所有参与者答复
- 参与者收到 canCommit 请求后,如果认为可以执行事务操作,则反馈 yes 并进入预备状态,否则反馈 no
阶段 2:preCommit
- 协调者根据阶段 1 canCommit 参与者的反应情况来决定是否可以进行基于事务的 preCommit 操作。根据响应情况,有以下两种可能
- 情况 1:阶段 1 所有参与者均反馈 yes,参与者预执行事务
- 协调者向所有参与者发出 preCommit 请求,进入准备阶段
- 参与者收到 preCommit 请求后,执行事务操作,将 undo 和 redo 信息记入事务日志中(但不提交事务)
- 各参与者向协调者反馈 ack 响应或 no 响应,并等待最终指令
- 情况 2:阶段 1 任何一个参与者反馈 no,或者等待协调者超时,无法收到所有参与者的反馈,即中断事务
- 协调者向所有参与者发出 abort 请求
- 无论收到协调者发出的 abort 请求,或者在等待协调者请求过程中出现超时,参与者均会中断事务
阶段 3:do Commit
- 该阶段进行真正的事务提交,分为以下三种情况
- 情况 1:阶段 2 所有参与者均反馈 ack 响应,执行真正的事务提交
- 如果协调者处于工作状态,则向所有参与者发出 do Commit 请求,参与者收到 do Commit 请求后,会正式执行事务提交,并释放整个事务期间占用的资源
- 各参与者向协调者反馈 ack 完成的消息,协调者收到所有参与者反馈的 ack 消息后,即完成事务提交
- 情况 2:阶段 2 任何一个参与者反馈 no,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务
- 如果协调者处于工作状态,向所有参与者发出 abort 请求,参与者使用阶段 1 中的 undo 信息执行回滚操作,并释放整个事务期间占用的资源
- 各参与者向协调者反馈 ack 完成的消息,协调者收到所有参与者反馈的 ack 消息后,即完成事务中断
- 情况 3:协调者与参与者网络出现问题
- 参与者在协调者发出 do Commit 或 abort 请求等待超时,仍会继续执行事务提交
3 TCC

- Try阶段:需要做资源的检查和预留。在扣钱场景下,Try 要做的事情是就是检查账户可用余额是否充足,再冻结账户的资金。Try 方法执行之后,账号余额虽然还是100,但是其中 30 元已经被冻结了,不能被其他事务使用
- Confirm阶段: 扣减 Try 阶段冻结的资金,Confirm 方法执行之后,账号在一阶段中冻结的 30 元已经被扣除,账号 A 余额变成 70 元
- Cancel阶段:回滚的话,就需要在 Cancel 方法内释放一阶段 Try 冻结的 30 元,使账号的回到初始状态,100 元全部可用
4 saga
Saga是一个长活事务,可被分解成可以交错运行的子事务集合,每个子事务有相应的执行模块和补偿模块,当saga事务中的任意一个本地事务出错了,可以通过调用相关事务对应的补偿方法恢复,达到事务的最终一致性。

每个Saga由一系列sub-transaction Ti 组成
- 每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果
- 可以看到,和TCC 相比,Saga没有“预留”动作,它的 Ti 就是直接提交到库。
- saga 不保证 acid,只保持服务的基本可用和数据的最终一致性,事务隔离性差,要保证数据不被脏读需要在业务上进行相应的逻辑处理。可以再业务层加入锁隔离相关联的操作
- Saga的执行顺序有两种:
- T1, T2, T3, …, Tn
- T1, T2, …, Tj, Cj,…, C2, C1,其中
0<j<n
- Saga定义了两种恢复策略:
- backward recovery,向后恢复,补偿所有已完成的事务,如果任一子事务失败。即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。
- forward recovery,向前恢复,重试失败的事务,假设每个子事务最终都会成功。适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, …, Tj(失败), Tj(重试),…, Tn,其中j是发生错误的sub-transaction。该情况下不需要 Ci。
5 seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用 的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事 务模式,为用户打造一站式的分布式解决方案(AT模式是阿里首推的模式)
AT模式(阿里分布式框架seata)
一阶段:提交
- 在一阶段,Seata 会拦截“业务 SQL”,首先解析SQL语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性
二阶段提交或回滚
- 二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可
- 二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据
- 回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理
6 事务消息
- 本地消息事务表 + 消息队列
- 1 在同一个事务中完成订单数据和单独的消息表入库
- 通过 cancal 将增量消息放入消息队列
- 主动线程轮询查询增量消息放入消息队列,增量可以通过缓存已发送过的消息表最大ID筛选
- 2 消费者消费过后,标记事务消息的成功与失败
- 1 在同一个事务中完成订单数据和单独的消息表入库
- 本地消息事务表 + 消息队列 + kafka 事务API。initTransactions 和 commitTransaction 范围需要大于包括数据库的事务操作范围
- 在同一个数据库事务中完成订单数据和单独的消息表入库(处理中)
- 数据库事务提交后,成功再提交 kafka 事务 commitTransaction。失败则 abortTransaction
- 事务消息的补偿,为防止队列消息投递失败。定期查询状态是处理中的事务表消息,重新投递
- 消费者消费过后,标记事务消息的成功与失败
// 初始化事务,需要注意确保transation.id属性被分配
void initTransactions();
// 开启事务
void beginTransaction() throws ProducerFencedException;
// 为Consumer提供的在事务内Commit Offsets的操作
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException;
// 提交事务
void commitTransaction() throws ProducerFencedException;
// 放弃事务,类似于回滚事务的操作
void abortTransaction() throws ProducerFencedException;
- RocketMQ事务消息也是类似kafka,但是更加完善,采用了2PC(两阶段提交)+ 补偿机制(事务状态回查)的思想来实现了提交事务消息,同时增加一个补偿逻辑来处理二阶段超时或者失败的消息
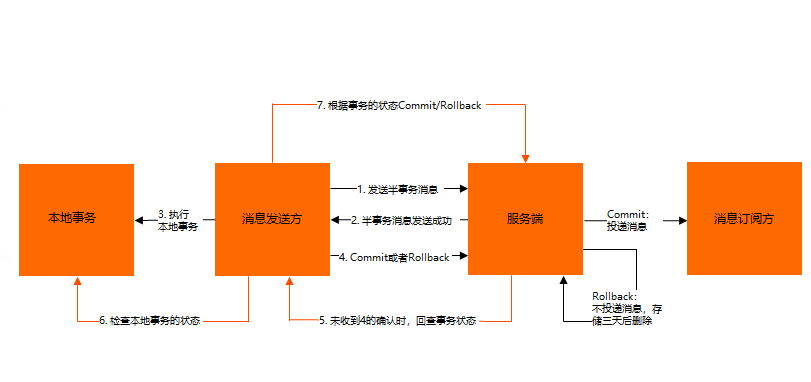
- 正常事务消息的发送及提交
- a、 生产者发送half消息到Broker服务端(半消息)半消息是一种特殊的消息类型,该状态的消息暂时不能被Consumer消费
- b、Broker服务端将消息持久化之后,给生产者响应消息写入结果(ACK响应);
- c、生产者根据发送结果执行本地事务逻辑(如果写入失败,此时half消息对业务不可见,本地逻辑不执行);
- d、生产者根据本地事务执行结果向Broker服务端提交二次确认(Commit 或是 Rollback),Broker服务端收到 Commit 状态则将半事务消息标记为可投递,订阅方最终将收到该消息;Broker服务端收到 Rollback 状态则删除半事务消息,订阅方将不会接收该消息
- 事务消息的补偿流程
- a、在网络闪断或者是应用重启的情况下,可能导致生产者发送的二次确认消息未能到达Broker服务端,经过固定时间后,Broker服务端将会对没有Commit/Rollback的事务消息(pending状态的消息)进行“回查”;
- b、生产者收到回查消息后,检查回查消息对应的本地事务执行的最终结果;
- c、生产者根据本地事务状态,再次提交二次确认给Broker,然后Broker重新对半事务消息Commit或者Rollback
- 正常事务消息的发送及提交

分布式锁
1 redis 的实现方案
- 1:set ex | px nx
- 锁可以自动过期
- 加锁和加失效时间两是原子性操作
- 缺点:如果需要回滚删除锁,易出现 bug 引起误删其他线程加上的锁
- 缺点:锁过期释放了,业务还没执行完,无法延迟过期时间
- 2:set ex | px nx 。value 是当前线程独有的唯一随机值,需要校验 value 再删除
- 锁可以自动过期
- 加锁和加失效时间是原子性的操作
- 可防止锁被别的线程误删
- 缺点:锁过期释放了,业务还没执行完,无法延迟过期时间
- 3: redission
- Redisson 可以解决 锁过期释放,业务没执行完的问题
- 只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题
- 4:Redlock
- redis 如果是单 master 的,线程 A 在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程 B 就可以获取同个key的锁啦,但线程 A 也已经拿到锁了,锁的安全性就没了
- 多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步
- 然后在多台 Redis master 同时请求加锁,但加锁 redis 机器超过一半。并且加锁使用的时间小于锁的有效期,则加锁成功。
2 数据库的实现方案
- 单点故障:数据库可以多搞个数据库备份
- 没有失效时间:每次加锁时,插入一个期待的有效时间
- A:定时任务,隔一段时间清理时间失效锁
- B:下次加锁时则先判断当前时间是否大于锁的有效时间,以此判断锁是否失效
- 不可重入:在数据加锁时加入一个幂等唯一值字段,下次获取时,先判断这个字段是否一致,一致则说明是当前操作重入操作
3 zookeeper
- zookeeper 临时顺序节点:临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉(可解决分布式锁的自动失效)。另外,在临时节点下面不能创建子节点
- zookeeper 监视器:zookeeper创建一个节点时,会注册一个该节点的监视器,当节点状态发生改变时,watch会被触发,zooKeeper将会向客户端发送一条通知
- zookeeper 分布式锁原理
- 创建临时有序节点,每个线程均能创建节点成功,但是其序号不同,只有序号最小的可以拥有锁,其它线程只需要监听比自己序号小的节点状态即可
- 1: 在指定的节点下创建一个锁目录lock
- 2: 线程 X 进来获取锁在lock目录下,并创建临时有序节点
- 3: 线程 X 获取lock目录下所有子节点,并获取比自己小的兄弟节点,如果不存在比自己小的节点,说明当前线程序号最小,顺利获取锁
- 4: 此时线程Y进来创建临时节点并获取兄弟节点,判断自己是否为最小序号节点,发现不是,于是设置监听(watch)比自己小的节点(这里是为了发生上面说的羊群效应)
- 5: 线程X执行完逻辑,删除自己的节点,线程Y监听到节点有变化,进一步判断自己是已经是最小节点,顺利获取锁


