深入浅出 BPF TCP 拥塞算法实现原理
本文地址://www.ebpf.top/post/ebpf_struct_ops
1. 前言
eBPF 的飞轮仍然在快速转动,自从 Linux 内核 5.6 版本支持 eBPF 程序修改 TCP 拥塞算法能力,可通过在用户态修改内核中拥塞函数结构指针实现;在 5.13 版本中该功能又被进一步优化,增加了该类程序类型直接调用部分内核代码的能力,这避免了在 eBPF 程序中需要重复实现内核中使用的 TCP 拥塞算法相关的函数。
这两个功能的实现,为 Linux 从宏内核向智能化的微内核提供的演进,虽然当前只是聚焦在 TCP 拥塞算法的控制,但是这两个功能的实现却具有非常好的想象空间。这是因为 Linux 内核中的诸多功能都是基于结构体指针的方式,当我们具有在用户编写的 eBPF 程序完成内核结构体中函数的重定向,则可以实现内核的灵活扩展和功能的增强,再配合内核函数直接的调用能力,等同于为普通用户提供了定制内核的能力。尽管这只是 eBPF 一小步,后续却可能会称为内核生态的一大步。
本文先聚焦在 5.6 版本为 TCP 拥塞算法定制而提供的 STRUCT_OPS 的能力,对于该类型 eBPF 程序调用 Linux 内核函数的能力,我们会在下一篇进行详细介绍。
2. eBPF 赋能 TCP 拥塞控制算法
为了支持通过 eBPF 程序可以修改 TCP 拥塞控制算法的能力,来自于 Facebook 的工程师 Martin KaFai Lau 于 2020-01-08 号提交了一个有 11 个小 Patch 组成的 提交 。实现为 eBPF 增加了 BPF_MAP_TYPE_STRUCT_OPS 新的 map 结构类型和 BPF_PROG_TYPE_STRUCT_OPS 的程序类型,当前阶段只支持对于内核中 TCP 拥塞结构 tcp_congestion_ops 的修改。
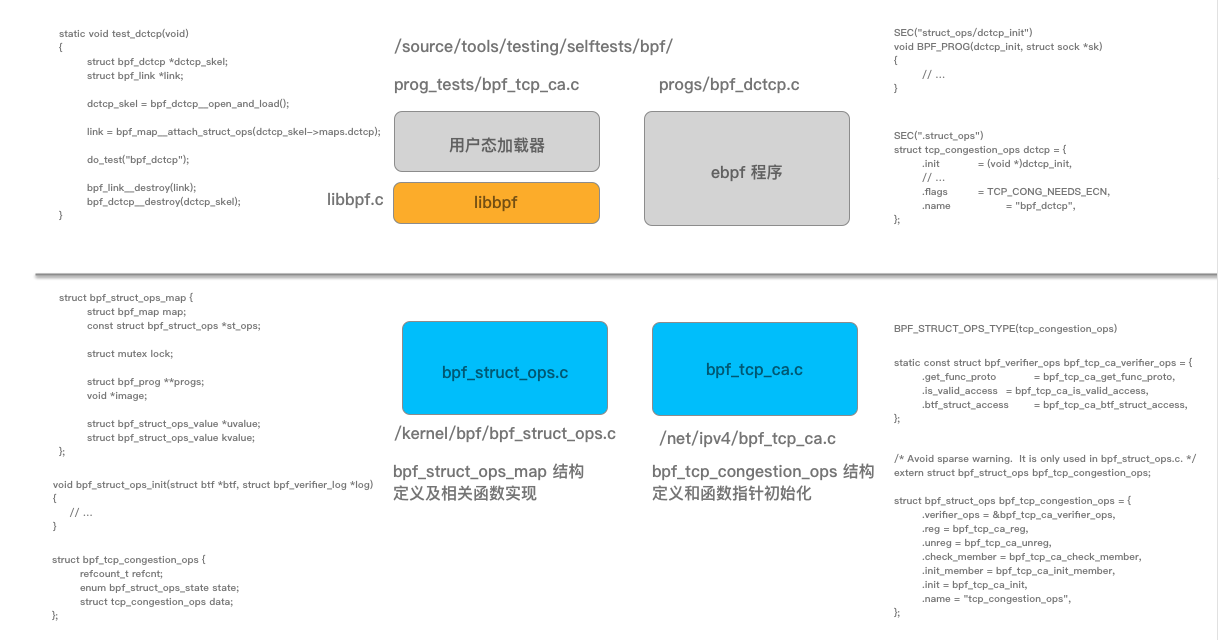
图 1 整体实现的相关结构和代码片段
首先我们从如何使用样例程序入手(完整代码实现参见 这里 ),这里我们省略与功能介绍不相干的内容:
SEC("struct_ops/dctcp_init")
void BPF_PROG(dctcp_init, struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
struct dctcp *ca = inet_csk_ca(sk);
ca->prior_rcv_nxt = tp->rcv_nxt;
ca->dctcp_alpha = min(dctcp_alpha_on_init, DCTCP_MAX_ALPHA);
ca->loss_cwnd = 0;
ca->ce_state = 0;
dctcp_reset(tp, ca);
}
SEC("struct_ops/dctcp_ssthresh")
__u32 BPF_PROG(dctcp_ssthresh, struct sock *sk)
{
struct dctcp *ca = inet_csk_ca(sk);
struct tcp_sock *tp = tcp_sk(sk);
ca->loss_cwnd = tp->snd_cwnd;
return max(tp->snd_cwnd - ((tp->snd_cwnd * ca->dctcp_alpha) >> 11U), 2U);
}
// ....
SEC(".struct_ops")
struct tcp_congestion_ops dctcp_nouse = {
.init = (void *)dctcp_init,
.set_state = (void *)dctcp_state,
.flags = TCP_CONG_NEEDS_ECN,
.name = "bpf_dctcp_nouse",
};
SEC(".struct_ops")
struct tcp_congestion_ops dctcp = { // bpf 程序定义的结构与内核中使用的结构不一定相同
// 可为必要字段的组合
.init = (void *)dctcp_init,
.in_ack_event = (void *)dctcp_update_alpha,
.cwnd_event = (void *)dctcp_cwnd_event,
.ssthresh = (void *)dctcp_ssthresh,
.cong_avoid = (void *)tcp_reno_cong_avoid,
.undo_cwnd = (void *)dctcp_cwnd_undo,
.set_state = (void *)dctcp_state,
.flags = TCP_CONG_NEEDS_ECN,
.name = "bpf_dctcp",
};
这里注意到两点:
- tcp_congestion_ops 结构体并非内核头文件里的对应结构体,它只包含了内核对应结构体里 TCP CC 算法用到的字段,它是内核对应同名结构体的子集。
- 有些结构体(如 tcp_sock)会看到 preserve_access_index 属性表示 eBPF 字节码在载入的时候,会对这个结构体里的字段进行重定向,满足当前内核版本的同名结构体字段的偏移。
其中需要注意的是在 BPF 程序中定义的 tcp_congestion_ops 结构(也被称为 bpf-prg btf 类型),该类型可以与内核中定义的结构体完全一致(被称为 btf_vmlinux btf 类型),也可为内核结构中的部分必要字段,结构体定义的顺序可以不需内核中的结构体一致,但是名字,类型或者函数声明必须一致(比如参数和返回值)。因此可能需要从 bpf-prg btf 类型到 btf_vmlinux btf 类型的一个翻译过程,这个转换过程使用到的主要是 BTF 技术,目前主要是通过成员名称、btf 类型和大小等信息进行查找匹配,如果不匹配 libbpf 则会返回错误。整个转换过程与 Go 语言类型中的反射机制类似,主要实现在函数 bpf_map__init_kern_struct_ops 中(见原理章节详细介绍)。
在 eBPF 程序中增加 section 名字声明为 .struct_ops,用于 BPF 实现中识别要实现的 struct_ops 结构,例如当前实现的 tcp_congestion_ops 结构。
在 SEC(“.struct_ops”) 下支持同时定义多个 struct_ops 结构。每个 struct_ops 都被定义为 SEC(“.struct_ops”) 下的一个全局变量。libbpf 为每个变量创建了一个 map,map 的名字为定义变量的名字,本例中为 bpf_dctcp_nouse 和 dctcp。
用户态完整代码参见 这里 ,生成的脚手架相关代码参见 这里 ,与 dctcp 相关的核心程序代码如下:
static void test_dctcp(void)
{
struct bpf_dctcp *dctcp_skel;
struct bpf_link *link;
// 脚手架生成的函数
dctcp_skel = bpf_dctcp__open_and_load();
if (CHECK(!dctcp_skel, "bpf_dctcp__open_and_load", "failed\n"))
return;
// bpf_map__attach_struct_ops 增加了注册一个 struct_ops map 到内核子系统
// 这里为我们上面定义的 struct tcp_congestion_ops dctcp 变量
link = bpf_map__attach_struct_ops(dctcp_skel->maps.dctcp);
if (CHECK(IS_ERR(link), "bpf_map__attach_struct_ops", "err:%ld\n",
PTR_ERR(link))) {
bpf_dctcp__destroy(dctcp_skel);
return;
}
do_test("bpf_dctcp");
# 销毁相关的数据结构
bpf_link__destroy(link);
bpf_dctcp__destroy(dctcp_skel);
}
详细流程解释如下:
-
在 bpf_object__open 阶段,libbpf 将寻找 SEC(“.struct_ops”) 部分,并找出 struct_ops 所实现的 btf 类型。 需要注意的是,这里的 btf-type 指的是 bpf_prog.o 的 btf 中的一个类型。 “struct bpf_map” 像其他 map 类型一样, 通过 bpf_object__add_map() 进行添加。 然后 libbpf 会收集(通过 SHT_REL)bpf progs 的位置(使用 SEC(“struct_ops/xyz”) 定义的函数),这些位置是 func ptrs 所指向的地方。 在 open 阶段并不需要 btf_vmlinux。
-
在 bpf_object__load 阶段,map 结构中的字段(赖于 btf_vmlinux) 通过
bpf_map__init_kern_struct_ops()初始化。在加载阶段,libbpf 还会设置 prog->type、prog->attach_btf_id 和 prog->expected_attach_type 属性。 因此,程序的属性并不依赖于它的 section 名称。目前,bpf_prog btf-type ==> btf_vmlinux btf-type 匹配过程很简单:成员名匹配 + btf-kind 匹配 + 大小匹配。
如果这些匹配条件失败,libbpf 将拒绝。目前的目标支持是 “struct tcp_congestion_ops”,其中它的大部分成员都是函数指针。
bpf_prog 的 btf-type 的成员排序可以不同于 btf_vmlinux 的 btf-type。然后,所有 obj->maps 像往常一样被创建(在 bpf_object__create_maps())。一旦 map 被创建,并且 prog 的属性都被设置好了,libbpf 就会继续执行。libbpf 将继续加载所有的程序。
-
bpf_map__attach_struct_ops() 是用来注册一个 struct_ops map 到内核子系统中。
关于支持 TCP 拥塞控制算法的完整 PR 代码参见 这里 。
3. 脚手架代码相关实现
关于生成脚手架的样例过程如下:(脚手架的提交 commit 参见 这里 ,可以在 这里 搜索相关关键词查看)。
$ cd tools/bpf/runqslower && make V=1 # 整个过程如下
$ .output/sbin/bpftool btf dump file /sys/kernel/btf/vmlinux format c > .output/vmlinux.h
clang -g -O2 -target bpf -I.output -I.output -I/home/vagrant/linux-5.8/tools/lib -I/home/vagrant/linux-5.8/tools/include/uapi \
-c runqslower.bpf.c -o .output/runqslower.bpf.o && \
$ llvm-strip -g .output/runqslower.bpf.o
$ .output/sbin/bpftool gen skeleton .output/runqslower.bpf.o > .output/runqslower.skel.h
$ cc -g -Wall -I.output -I.output -I/home/vagrant/linux-5.8/tools/lib -I/home/vagrant/linux-5.8/tools/include/uapi -c runqslower.c -o .output/runqslower.o
$ cc -g -Wall .output/runqslower.o .output/libbpf.a -lelf -lz -o .output/runqslower
4. bpf struct_ops 底层实现原理
在上述的过程中对于用户态代码与内核中的主要实现流程已经给与了说明,如果你对内核底层实现原理不感兴趣,可以跳过该部分。
4.1 内核中的 ops 结构(bpf_tcp_ca.c)
如图 1 所示,为了实现该功能,需要在内核代码中提供基础能力支撑,内核中结构对应的操作对象结构(ops 结构)为 bpf_tcp_congestion_ops,定义在 /net/ipv4/bpf_tcp_ca.c 文件中,实现参见 这里 :
/* Avoid sparse warning. It is only used in bpf_struct_ops.c. */
extern struct bpf_struct_ops bpf_tcp_congestion_ops;
struct bpf_struct_ops bpf_tcp_congestion_ops = {
.verifier_ops = &bpf_tcp_ca_verifier_ops,
.reg = bpf_tcp_ca_reg,
.unreg = bpf_tcp_ca_unreg,
.check_member = bpf_tcp_ca_check_member,
.init_member = bpf_tcp_ca_init_member,
.init = bpf_tcp_ca_init,
.name = "tcp_congestion_ops",
};
bpf_tcp_congestion_ops 结构中的各个函数说明如下:
- init() 函数将被首先调用,以进行任何需要的全局设置;
- init_member() 则验证该结构中任何字段的确切值。特别是,init_member() 可以验证非函数字段(例如,标志字段);
- check_member() 确定目标结构的特定成员是否允许在 BPF 中实现;
- reg() 函数在检查通过后实际注册了替换结构;在拥塞控制的情况下,它将把 tcp_congestion_ops 结构(带有用于函数指针的适当的 BPF 蹦床(trampolines ))安装在网络堆栈将使用它的地方;
- unreg() 撤销注册;
- verifier_ops 结构有一些函数,用于验证各个替换函数是否可以安全执行;
其中 verfier_ops 结构主要用于验证器(verfier)的判断,其中定义的函数如下:
static const struct bpf_verifier_ops bpf_tcp_ca_verifier_ops = {
.get_func_proto = bpf_tcp_ca_get_func_proto,// 验证器使用的函数原型,用于验证是否允许在 eBPF 程序中的
// BPF_CALL 内核内的辅助函数,并在验证后调整 BPF_CALL 指令中的 imm32 域。
.is_valid_access = bpf_tcp_ca_is_valid_access, // 是否是合法的访问
.btf_struct_access = bpf_tcp_ca_btf_struct_access, // 用于判断 btf 中结构体是否可以被访问
};
最后,在 kernel/bpf/bpf_struct_ops_types.h 中添加一行:
BPF_STRUCT_OPS_TYPE(tcp_congestion_ops)
4.2 内核 ops 对象结构定义和管理(bpf_struct_ops.c)
在 bpf_struct_ops.c 文件中,通过包含 “bpf_struct_ops_types.h” 文件 4 次,并分别设置 BPF_STRUCT_OPS_TYPE 宏,实现了 map 中 value 值结构的定义和内核定义 ops 对象数组的管理功能,同时也包括对应数据结构 BTF 中的定义。
/* bpf_struct_ops_##_name (e.g. bpf_struct_ops_tcp_congestion_ops) is
* the map's value exposed to the userspace and its btf-type-id is
* stored at the map->btf_vmlinux_value_type_id.
*
*/
#define BPF_STRUCT_OPS_TYPE(_name) \
extern struct bpf_struct_ops bpf_##_name; \
\
struct bpf_struct_ops_##_name { \
BPF_STRUCT_OPS_COMMON_VALUE; \
struct _name data ____cacheline_aligned_in_smp; \
};
#include "bpf_struct_ops_types.h" // ① 用于生成 bpf_struct_ops_tcp_congestion_ops 结构
#undef BPF_STRUCT_OPS_TYPE
enum {
#define BPF_STRUCT_OPS_TYPE(_name) BPF_STRUCT_OPS_TYPE_##_name,
#include "bpf_struct_ops_types.h" // ② 生成一个 enum 成员
#undef BPF_STRUCT_OPS_TYPE
__NR_BPF_STRUCT_OPS_TYPE,
};
static struct bpf_struct_ops * const bpf_struct_ops[] = {
#define BPF_STRUCT_OPS_TYPE(_name) \
[BPF_STRUCT_OPS_TYPE_##_name] = &bpf_##_name,
#include "bpf_struct_ops_types.h" // ③ 生成一个数组中的成员 [BPF_STRUCT_OPS_TYPE_tcp_congestion_ops]
// = &bpf_tcp_congestion_ops
#undef BPF_STRUCT_OPS_TYPE
};
void bpf_struct_ops_init(struct btf *btf, struct bpf_verifier_log *log)
{
/* Ensure BTF type is emitted for "struct bpf_struct_ops_##_name" */
#define BPF_STRUCT_OPS_TYPE(_name) BTF_TYPE_EMIT(struct bpf_struct_ops_##_name);
#include "bpf_struct_ops_types.h" // ④ BTF_TYPE_EMIT(struct bpf_struct_ops_tcp_congestion_ops btf 注册
#undef BPF_STRUCT_OPS_TYPE
// ...
}
编译完整展开后相关的结构:
extern struct bpf_struct_ops bpf_tcp_congestion_ops;
struct bpf_struct_ops_tcp_congestion_ops { // ① 作为 map 类型的 value 对象存储
refcount_t refcnt;
enum bpf_struct_ops_state state
struct tcp_congestion_ops data ____cacheline_aligned_in_smp; // 内核中的 tcp_congestion_ops 对象
};
enum {
BPF_STRUCT_OPS_TYPE_tcp_congestion_ops // ② 序号声明
__NR_BPF_STRUCT_OPS_TYPE,
};
static struct bpf_struct_ops * const bpf_struct_ops[] = { // ③ 作为数组变量
// 其中 bpf_tcp_congestion_ops 即为 /net/ipv4/bpf_tcp_ca.c 文件中定义的变量(包含了各种操作的函数指针)
[BPF_STRUCT_OPS_TYPE_tcp_congestion_ops] = &bpf_tcp_congestion_ops,
};
void bpf_struct_ops_init(struct btf *btf, struct bpf_verifier_log *log)
{
// #define BTF_TYPE_EMIT(type) ((void)(type *)0)
((void)(struct bpf_struct_ops_tcp_congestion_ops *)0); // ④ BTF 类型注册
// ...
}
至此内核完成了 ops 结构的类型的生成、注册和 ops 对象数组的管理。
4.3 map 中内核结构值初始化
该过程涉及将 bpf 程序中定义变量初始化 kernl 内核变量,该过程在 libbpf 库中的 bpf_map__init_kern_struct_ops 函数中实现。 函数原型为:
/* Init the map's fields that depend on kern_btf */
static int bpf_map__init_kern_struct_ops(struct bpf_map *map,
const struct btf *btf,
const struct btf *kern_btf)
使用 bpf 程序结构初始化 map 结构变量的主要流程如下:
- bpf 程序加载过程中会识别出来定义的 BPF_MAP_TYPE_STRUCT_OPS map 对象;
- 获取到 struct ops 定义的变量类型(如 struct tcp_congestion_ops dctcp)中的 tcp_congestion_ops 类型,使用获取到 tname/type/type_id 设置到 map 结构中的 st_ops 对象中;
- 通过上一步骤设置的 tname 属性在内核的 btf 信息表中查找内核中 tcp_congestion_ops 类型的 type_id 和 type 等信息,同时也获取到 map 对象中 value 值类型 bpf_struct_ops_tcp_congestion_ops 的 vtype_id 和 vtype 类型;
- 至此已经拿到了 bpf 程序中定义的变量及 bpf_prog btf-type tcp_congestion_ops, 内核中定义的类型 tcp_congestion_ops 以及 map 值类型的 bpf_struct_ops_tcp_congestion_ops 等信息;
- 接下来的事情就是通过特定的 btf 信息规则(名称、调用参数、返回类型等)将 bpf_prog btf-type 变量初始化到 bpf_struct_ops_tcp_congestion_ops 变量中,将内核中的变量初始化以后,放入到 st_ops->kern_vdata 结构中(bpf_map__attach_struct_ops() 函数会使用 st_ops->kern_vdata 更新 map 的值,map 的 key 固定为 0 值(表示第一个位置);
- 然后设置 map 结构中的 btf_vmlinux_value_type_id 为 vtype_id 共后续检查和使用, map->btf_vmlinux_value_type_id = kern_vtype_id;
5. 总结
从表面上看,拥塞控制是 BPF 的一项重要的新功能,但是从底层的实现我们可以看到,这个功能的实现远比该功能更加通用,相信在不久的将来还有会更加丰富的实现,在软件中定义内核功能的实现会带给我们不一样的体验。
具体来说,该基础功能可以用来让一个 BPF 程序取代内核中的任何使用函数指针的 ” 操作结构 “,而且内核代码的很大一部分是通过至少一个这样的结构调用的。如果我们可以替换全部或部分 security_hook_heads 结构,我们就可以以任意的方式修改安全策略,例如类似于 KRSI 的建议。替换一个 file_operations 结构可以重新连接内核的 I/O 子系统的任何部分。
现在还没有人提出要做这些事情,但是这种能力肯定会吸引感兴趣的用户。有一天,几乎所有的内核功能都可以被用户空间的 BPF 代码钩住或替换。在这样的世界里,用户将有很大的权力来改变他们系统的运行方式,但是我们认为的 “Linux 内核 ” 将变得更加无定形,因为诸多功能可能会取决于哪些代码从用户空间加载。


