Detecting rare visual relations using analogies 论文笔记
Background
- 论文动机:
- 各个实体的训练样本存在,但是它们的组合在训练过程中很稀少或者是未出现过的。对所有可能的关系三元组收集足够多的训练数据是非常困难的
- 论文贡献:
- 学习了结合subject、object以及predict individual embedding和表示关系三元组的visual phrase embedding的视觉关系表示方法。不同细粒度的表示,能够捕获更丰富的信息。
- 学习如何使用涉及相似object的关系之间的类比,将现有的训练三元组visual phrase embedding迁移至未见过的关系三元组。
- 我们在两个涉及rare and unseen具有挑战性的数据集上展示我们的方法的优势。
Model
第一部分
对subject (s)、object (o)、predicate (p)和visual phrase (vp)学习不同的visual-language embedding spaces。
假设训练数据存在N个候选边界框对。每一个候选边界框对由subject candidate bounding box proposal 和 object candidate bounding box 组成。令\mathcal{V}_{s} 、 \mathcal{V}_{o} 、\mathcal{V}_{p} 分别表示 subject、object和 predicate 的词汇表。则\mathcal{V}_{v p}=\mathcal{V}_{s} \times \mathcal{V}_{p} \times \mathcal{V}_{o} 表示三元组的词汇表。
三元组t可以表示为t = (s , p , o)。对于每对subject 和 object边界框,i \in [1 : N],被标记为一个向量(y^{i}_{t})_{t \in {\mathcal{V}_{v p}}}。其中,当i^{th}对框能够被关系三元组 t 描述时,y^{i}_{t} = 1,否则y^{i}_{t} = 0。subject、object和 predicate源于三元组标签。(怎么就源于三元组标签了,怎么通过三元组标签去表示subject, object 和 predicate 的标签?)
Learning representations of visual relations
在不同细粒度的 joint visual-semantic embedding spaces中,不同类型的embedding可以更好地表示视觉关系:
-
对于 unigram level,我们将 subject, object, predicate 表示在不同的 embedding space。
- visual embedding function的输入为由其视觉表示 \mathbf{x}_{i} \in \mathbb{R}^{d_{v}}编码的 object 候选对i。\mathbf{x}_{i}由CNN产生的视觉特征和相关候选 object 相关的空间信息构成。
- language embedding 将一个由语言表示\mathbf{q}_{t} \in \mathbb{R}^{d_{q}}编码三元组t作为输入。\mathbf{x}_{i}由预训练语言词向量得到。
-
对于 trigram level, 我们将整个三元组表示在 visual phrase embedding space。
-
网络将subject, object 和 predicate的视觉特征和语言特征投影到独立的空间。对于每一个输入类型b \in \{s, o, p, vp \},我们利用投影函数将视觉特征和语言特征嵌入到公共的d维空间中:
v^{b}_{i} = f^{b}_{v}(\mathbf{x}_{i}) (1)
w^{b}_{t} = f^{b}_{w}(\mathbf{q}_{t}) (2)
其中,v^{b}_{i}和w^{b}_{t}分别为视觉、语言表示输出。投影函数为多层感知机。(是每一种输入类型,有一个对应的投影函数,还是每一种细粒度对应一个投影函数?)
-
为了训练embedding function的参数,最小化 log-likelihood:
\begin{aligned} \mathcal{L}_{b} &=\sum_{i=1}^{N} \sum_{t \in \mathcal{V}_{b}} \mathbb{1}_{y_{i}^{i}=1} \log \left(\frac{1}{1+e^{-\boldsymbol{w}_{t}^{b^{T}} \boldsymbol{v}_{i}^{b}}}\right) \\ &+\sum_{i=1}^{N} \sum_{t \in \mathcal{V}_{b}} \mathbb{1}_{y_{t}^{i}=0} \log \left(\frac{1}{1+e^{\boldsymbol{w}_{t}^{b^{T}} \boldsymbol{v}_{i}^{b}}}\right) \end{aligned}(3)
其中,第一个吸引项使visual representation v_{i}^{b}与其正确的language representation w^{b}_{t}更接近。第二个排斥项使不匹配的 visual-languale对分离。如上图所示,对于每一种输入类型都存在一个损失函数。训练过程中,优化联合损失:
\begin{aligned} \mathcal{L}_{joint} &=\mathcal{L}_{s} + \mathcal{L}_{o} + \mathcal{L}_{p} + \mathcal{L}_{vp}\end{aligned}(4)
-
推理期间,利用公式(1)将测试图片嵌入为(v_{i}^{t})_{b}。类似地,利用公式(2)得到三元组t的编码形式(w_{t}^{b})_{b},作为language query。最后通过聚合不同嵌入类型的预测,计算triplet query t 与候选目标对 i 的相似性分数S:
S_{t, i}=\prod_{b \in\{s, p, o, v p\}} \frac{1}{1+e^{-\boldsymbol{w}_{t}^{b T} \boldsymbol{v}_{i}^{b}}} (5)
其中,b\in\{s, p, o, v p\}。
-
因为我们观察到每种类型的嵌入会捕捉不同观察到的视觉实体信息。如下图所示,在 p 空间中,视觉实体
person ride horse和person ride car因为相同的预测ride会被映射为同一点。比较而言,在 vp 空间中,这两个实体会被映射为不同的点。这使得 vp 空间能够很好地处理语言的多义词(”ride”涉及的object不同时,会有不同的视觉表现,因此不能映射到同一点上)和同义词(”person jump horse” 和 “person ride horse”应该被映射到靠近的点上,尽管它们预测的结果不同)。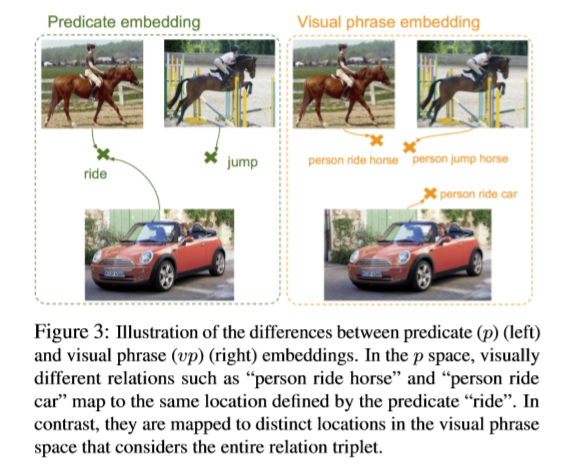

第二部分
Transferring embeddings to unseen triplets by analogy transformations
我们希望能够显式地通过类比推理,在测试期间,**将知识从训练过程中出现的三元组知识迁移至未出现的三元组。**推理过程分为两步:
-
如何从一个 visual phrase embedding 类比转换到另一个。
-
为了将源三元组的t=(s, r, o)的 visual phrase embedding转换成目标三元组t^{\prime}=\left(s^{\prime}, r^{\prime}, o^{\prime}\right)的 visual phrase embedding :
\boldsymbol{w}_{t^{\prime}}^{v p}=\boldsymbol{w}_{t}^{v p}+\Gamma\left(t, t^{\prime}\right) (6)
其中,\Gamma可以视为修正项,表示如何在联合 visual-language空间中将\boldsymbol{w}_{t}^{v p}转换为\boldsymbol{w}_{t^{\prime}}^{v p},以计算与源三元组t类似的目标关系三元组t^{\prime}。
-
为了使 t 和 t^{\prime}的visual phrase embedding 通过\Gamma产生联系。将三元组分解为subject s, predicate p 和 object o。则公式(6)被改写为:
\boldsymbol{w}_{t^{\prime}}^{v p}=\boldsymbol{w}_{t}^{v p}+\Gamma\left[\begin{array}{c}\boldsymbol{w}_{t^{\prime}}^{s}-\boldsymbol{w}_{t}^{s} \\ \boldsymbol{w}_{t^{\prime}}^{p}-\boldsymbol{w}_{t}^{p} \\ \boldsymbol{w}_{t^{\prime}}^{o}-\boldsymbol{w}_{t}^{o}\end{array}\right] (7)
其中,\boldsymbol{w}^{s}, \boldsymbol{w}^{p}和\boldsymbol{w}^{o}分别为对应的embedding。
直觉上,我们希望\Gamma能够对 object 的变化进行编码。采用简单的线性变换:
\Gamma_{A}\left(t, t^{\prime}\right)=A\left[\begin{array}{c}w_{t^{\prime}}^{s}-w_{t}^{s} \\ w_{t^{\prime}}^{p}-w_{t}^{p} \\ w_{t^{\prime}}^{o}-w_{t}^{o}\end{array}\right] (8)
其中,A \in \mathbb{R}^{d \times 3d}
-
通过最小化如下回归损失学习 \Gamma 中的 A :
\mathcal{L}_{\text {transfer}}(A)=\sum_{i=1}^{N} \sum_{t^{\prime} \in \mathcal{V}_{v p}} \mathbb{1}_{y_{t}^{i}=1} \sum_{t \in \mathcal{N}_{t^{\prime}}}\left\|\boldsymbol{w}_{t^{\prime}}^{v p}-\tilde{\boldsymbol{w}}_{t}^{v p}(A)\right\|_{2} (9)
其中,\tilde{\boldsymbol{w}}_{t}^{v p}(A) 为训练目标三元组t^{\prime}的 viusal phrase embedding。\tilde{\boldsymbol{w}}_{t}^{v p}(A)=\boldsymbol{w}_{t}^{v p}+\Gamma_{A}\left(t, t^{\prime}\right) 为适合类比转换的三元组转换后的 visual phrase embedding。源三元组与目标三元组的 subject, object 和 predicate 只有一个不同。
-
-
确定哪一个 visual phrase 适合去进行推理。
-
测试期间,通过聚合相似的出现过的三元组t \in \mathcal{N}_{u}计算未出现过的三元组的 visual phrase embedding:
\hat{\boldsymbol{w}}_{u}^{v p}=\sum_{t \in \mathcal{N}_{u}} G(t, u) \tilde{\boldsymbol{w}}_{t}^{v p} (10)
其中,\tilde{\boldsymbol{w}}_{t}^{v p}=\boldsymbol{w}_{t}^{v p}+\Gamma\left(t, u\right)。具体可以分为两步:
-
通过 \Gamma 进行转换。
-
利用权重函数G进行聚合。G 根据每个三元组与u的相似性计算权重。对三元组进行分解,分别计算每种类型的相似性(因为 subject, object, predicate相较于 visual phrase space 而言限制较小):
G(t, u)=\sum_{b \in\{s, p, o\}} \alpha_{b} w_{t}^{b^{T}} w_{u}^{b} (11)
利用点积计算相似性。\alpha_{b}为超参数。实际情况中,只保留k = 4个相似性最高的三元组通过公式(10)进行聚合。
-
-

