深度剖析目标检测算法YOLOV4
- 2020 年 12 月 10 日
- 筆記
- 机器学习(ML Machine Learning), 深度学习(DL Deep Learning)
深度剖析目标检测算法YOLOV4
目录
-
简述 yolo 的发展历程
-
介绍 yolov3 算法原理
-
介绍 yolov4 算法原理(相比于 yolov3,有哪些改进点)
-
YOLOV4 源代码日志解读
yolo 发展历程
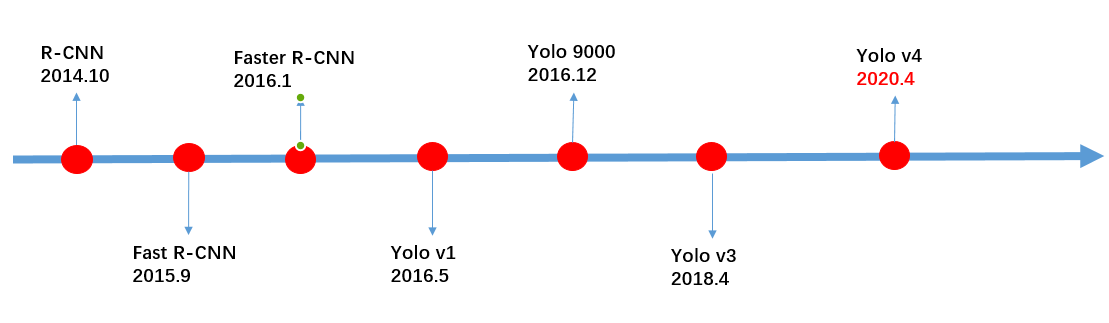
采用卷积神经的目标检测算法大致可以分为两个流派,一类是以 R-CNN 为代表的 two-stage,另一类是以 YOLO 为代表的 one-stage,
R-CNN 系列的原理:通过 ROI 提取出大约 2000 个候选框,然后每个候选框通过一个独立的 CNN 通道进行预测输出。
R-CNN 特点:准确度高,速度慢,所以速度成为它优化的主要方向。
YOLO 系列的原理:将输入图片作为一个整体,通过 CNN 通道进行预测输出。
YOLO 特点:速度快,准确度低,所以准确度成为它优化的主要方向。
经过一系列的优化与改进,特别是今年 4 月份推出的 YOLOV4,使得它在准确度方面得到了大幅度的提升,另外,它还能达到实时检测(在 GPU 加持的情况下)。
下图是 YOLOV4 源代码的页面,github: //github.com/AlexeyAB/darknet

它的 Star 达到 13400,可以说,知名度不是一般的高,在目标检测领域,好像只有 YOLOV3 超过它了,达到了 19000 ,是不是值得大家花点时间精力去探索一下呢 ?
这里需要说明一下的是 YOLOV3(美国大神),YOLOV4 (俄罗斯大神)作者不是同一个人,在 19 年的时候,YOLOV3 作者发表了一个声明:有些组织将他的算法用于
军事和窥探个人隐私方面,使得他在道德上很难接受,他将不再进行 CV 的研究与更新。当然,这是一个小插曲了,这里,我们看到,YOLOV4 作者更新是非常频繁的,
commits 达到了 2000 + 。下面我们看看官方给出的实验结果。

这里是以 COCO 作为测试数据集,相比于 YOLOV3,YOLOV4 在精度方面提升了 10%,FPS(frame per second) 提升了 12%。
顺便说一句,YOLOV3 的作者也是认可 YOLOV4 的改进的,在 YOLOV3 的官网 //github.com/pjreddie/darknet 也是给出了
YOLOV4 的链接。
yolov3 算法原理
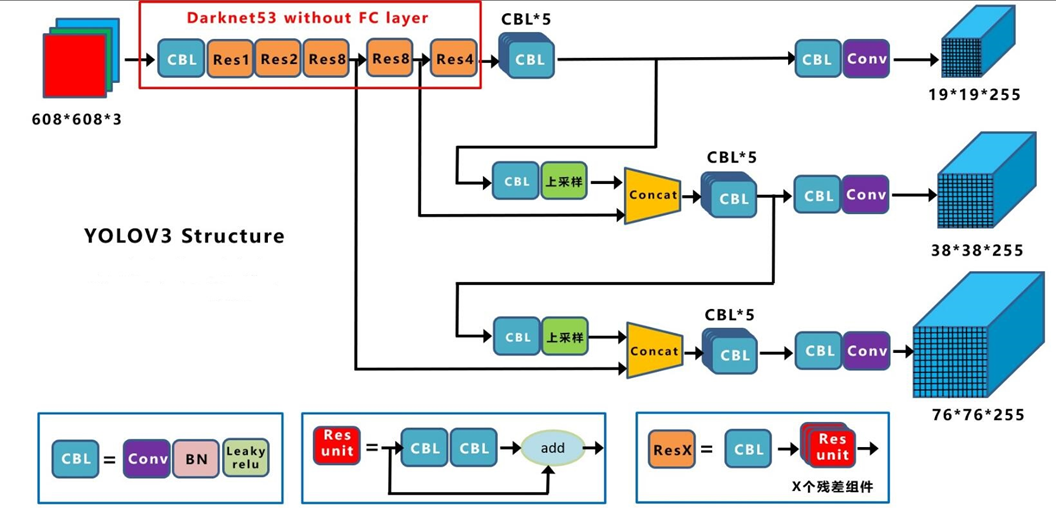
这里借用某位大神画的结构图,因为 YOLOV4 是在 YOLOV3 的基础上改进的,所以我们需要先介绍一下 YOLOV3,
这里可能需要一些神经网络的知识,比如卷积,池化,全连接,前向传播,反向传播,损失函数,梯度计算,权重参数更新,如果对
这些不是很清楚,可以看我之前的博客(卷积神经网络(CNN)详解与代码实现 //www.cnblogs.com/further-further-further/p/10430073.html)。
YOLOV3 原理我在上上一篇博客(深度剖析YOLO系列的原理 //www.cnblogs.com/further-further-further/p/12072225.html)有过介绍,
这里我就介绍一下大家容易忽略,或者是比较难理解的点:
- 输入图片尺寸可变
输入图片尺寸是 608 * 608,当然,这个尺寸是可以改变的,它只需要满足是 32 的倍数,因为在经过后面的网络结构的时候,图片尺寸缩小的最大倍数是 32 倍,
这可以从它的输出 19 * 19 看出来。
- 主干网络
采用的是 darknet 53 层网络结构,去掉了全连接层,53 – 1 = 52
52 = 1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)
为什么要去掉全连接层 ?
解答:全连接的本质是矩阵的乘法运算,会产生固定尺寸的输出,而 YOLOV3 是需要多尺寸的输出的,所以要去掉全连接层。
CBL :表示基础的卷积模块,是由一个 Conv 卷积层 + BN 批量归一化层 + relu 非线性激活函数层组成。
为什么在 CBL 里没有池化层 pooling ?
解答:池化层有两种实现方式,最大值池化和平均值池化,他们都有一个缺点,会造成信息的明显丢失(相比于卷积实现池化的功能来说,改变滑动窗口的步长) 。
Res Unit(残差单元) :表示将上一层的输出一分为二,一部分通过两个基础卷积模块得到输出,与另一部分进行求和,这样就能使得输出的残差不可能为 0,
从而有效的防止梯度消失或者梯度爆炸。
ResX : 是由不同的 Res Unit 组成。
多尺寸输出:用到 2 个上采样,注意 Concat 和 Add 的区别。
上采样原理:以特征图相邻像素值来预测中间位置的像素值,然后以这个值插入到中间位置,实现特征图尺寸的翻倍。
Concat : 特征图张量的拼接,拼接后尺寸不变,深度改变。
Add :特征图对应位置像素值的求和,求和后的尺寸和深度不发生改变。
- 输出
有三个输出,19 * 19 * 255,38 * 38 * 255,76 * 76 * 255
这三个输出有着怎样的物理含义 ?
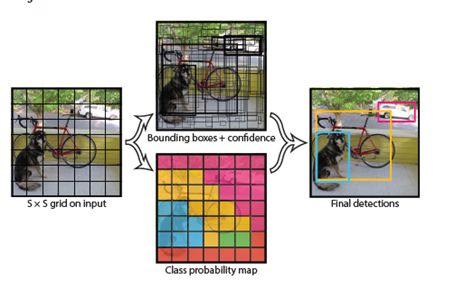
解答:将输入图片网格化,网格化后的大小是 19 *19, 38 * 38,76 * 76,每个网格化后的小方格,也就是一个 grid cell,将要
预测 3 个 bounding box,每个 bounding box = 1 个置信度 + 4 个位置信息 + 类别总数(COCO 数据集就是 80)
为什么每个 grid cell 要预测 3 个 bounding box ?
解答:这样来理解,比如说,一个人站在一辆车的前面,从远处看,这个人和这辆车中心点是完全重合的,但是我们能够看清楚
人和车,但是如果中心点重合的对象超过 3 个,那么我们很有可能对第 4 个,第 5 个以及后面的对象就完全看不清楚了,
所以,这里的 3 表示对象中心点重叠的最大值。
bounding box 如此之多,如何确定最佳的 bounding box ?
解答:采用的 NMS(Non Maximum Suppression)非极大值抑制算法来去除重叠。

NMS 算法原理:> 将预测输出的 bounding boxes 放入到左边的列表中,以置信度来进行降序排列,找到置信度最大的 bounding box ,
比如说这里的 dog1,将 dog1 移出左边列表到右边列表中;
> 遍历左边列表,求出每个 bounding box 与 dog1 的交并比(IoU = Intersection over Union 两个框的交集/并集),
当然,要提前设定一个阈值(一般是 0.5),大于 0.5表示左边 bounding box 与 dog1 有高度的重叠,将这个 bounding box 去掉;
> 重复之前的操作,直至左边列表为空,右边列表得到的 bounding box 就是最佳的结果;
检测匹配问题,为什么 19 * 19 => 大对象 ? 38 * 38 => 中等对象 ? 76 * 76 => 小对象 ?
解答:输入图片尺寸是固定的,比如说这里的 608 * 608,将它网格化,网格化就有三种情况:19 * 19,38 * 38,76 * 76,那么是不是 19 * 19 网格化后
的小方格的宽和高要比其他两种要大,这也就意味着它的感受视野是最大的,所以它就能检测出大对象,而其他两个的对应关系也是相同的道理。
yolov4 算法原理
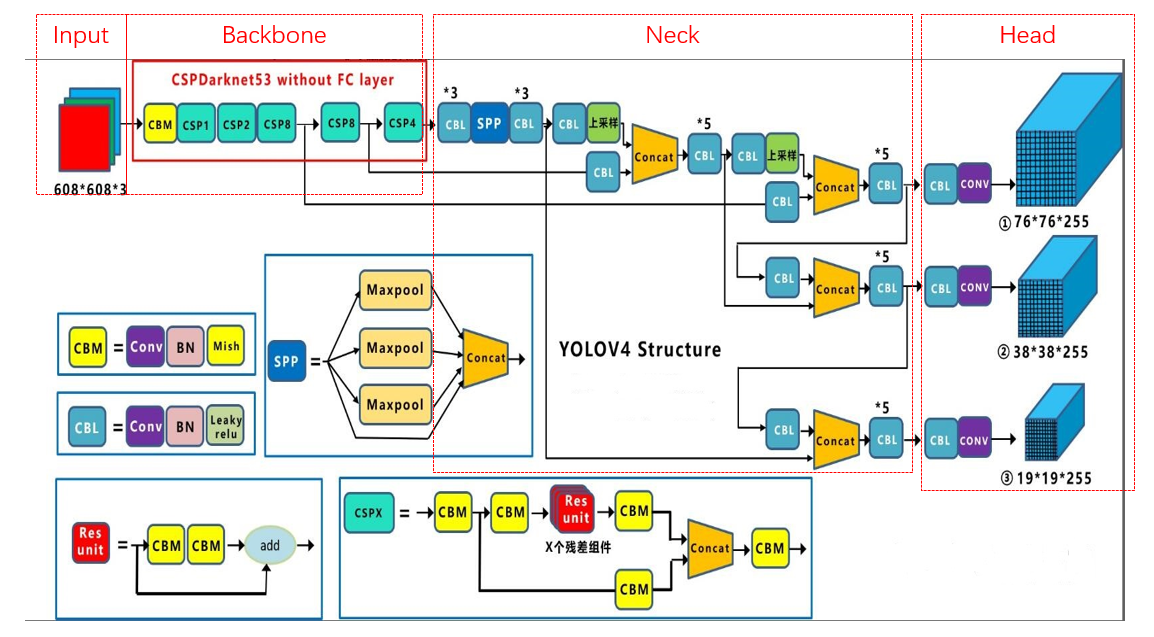
还是借用某位大神画的结构图,记不清名字了,是在抱歉。
乍一看,是不是跟 YOLOV3 长得很像,只不过比 YOLOV3 更复杂了一些,这里 YOLOV4 的作者将结构划分为以下四个部分:
Input,Backbone,Neck,Head,下面就来看看每个部分都做了哪些改进。
- Input 改进点
采用 Mosaic 实现数据增强。
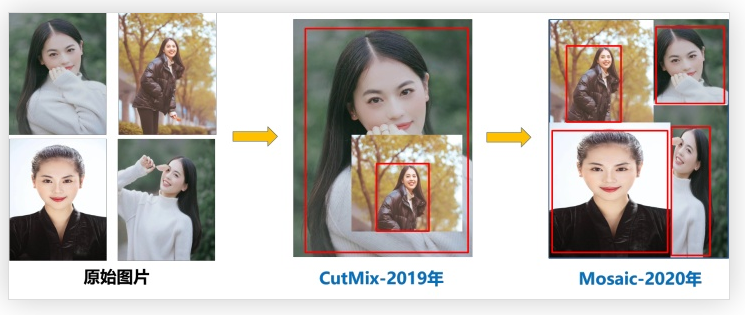
Mosaic 算法原理:在输入图片集中随机选取 4 张图片进行随机缩放,随机裁剪,随机扭曲,然后将他们拼接起来,
其目的就是丰富样本数据集。
- Backbone 改进点
采用 CSPNet(Cross Stage Partial Network)网络结构,它其实是在残差网络的基础上发展起来的。

具体改进点:
> 用 Concat 代替 Add,提取更丰富的特征。
之前介绍过 Concat 操作后,特征图的尺寸不变,深度会增加,而 Add 操作后尺寸和深度都不改变,从这个意义上说,用 Concat 代替 Add,就能够提取更丰富的特征。
> 引入 transition layer (1 * 1conv + 2 * 2pooling),提取特征,降低计算量,提升速度。
为什么引入 1 * 1conv,能够降低计算量,提升速度 ?

解答:这里我举一个实例来说明,输入图片大小是 56 * 56 * 256,要求得到输出大小是 28 * 28 * 512,这里就有两种实现方式:
一次卷积方式,它的卷积核参数个数是 117 万;另一种是二次卷积方式,引入了 1 * 1 卷积,它的卷积核参数个数是 62 万,
相比于一次卷积方式,它的卷积核参数个数降低了一倍。
> 将 Base layer 分为两部分进行融合,提取更丰富的特征。
将 Base layer 一分为二,一部分通过类似残差网络得到的输出与另一部分进行 Concat 操作,将操作后的结果通过 Transition Layer。
- Backbone 改进点
用 dropblock 取代 dropout

dropout 作用:防止过拟合,
dropout 缺点:每次训练时随机去掉的神经元可以通过相邻的神经元来预测,因为随着网络层数的增加,神经元之间的相关性是越来越强。
dropblock:每次训练时随机去掉一整片区域,这样就能组合更多不一样的网络,从而表现出更好的泛化作用。
- Neck 改进点
FPN(Feature pyramid networks) + PANet(Path Aggregation Network)
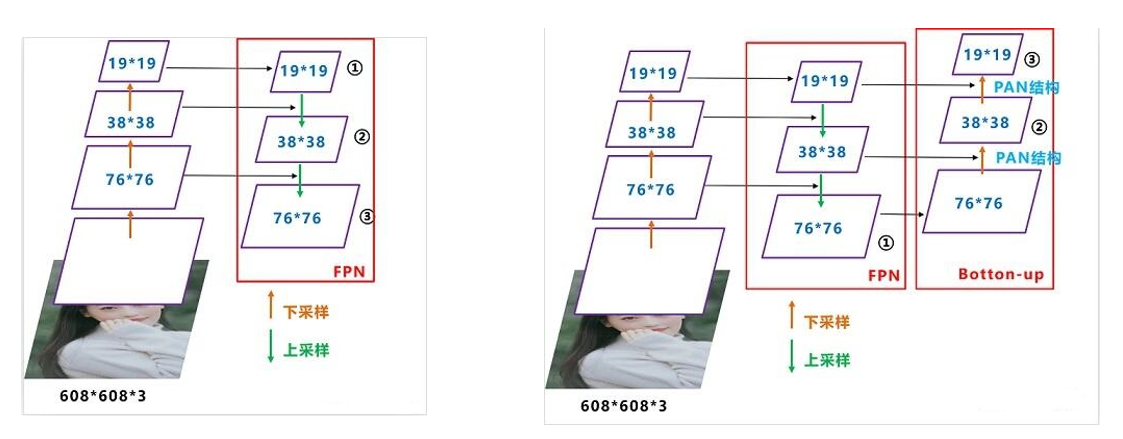
它其实是在 YOLOV3 的基础上增加了一个自底向上的 PANet 结构,特征图的尺寸是通过下采样得到的,而下采样是通过卷积的方式实现的(改变滑动窗口的步长)。
- Head 改进点
用 CIoU Loss 取代 Iou Loss

IoU loss 中 IoU 交并比,两个框的交集/并集,有两个缺点:
> 无法反应两个的距离
例如 状态 1,两个框不相交,无论怎样移动两个框,IoU = 0。
> 无法区分两者相交的情况
例如 状态 2 和 3,两个框相交的情况完全不一样,但是 IoU 相同。

CIoU Loss 的思想:第一步,在两个框最外层再画一个最小的矩形框,求出这个框的对角线的距离,这个距离就能衡量两个框的距离;
第二步,求出两个框中心点的欧式距离,这欧式距离就能衡量两者的相交情况。

CIoU Loss 数学表达式如上,它能有效的解决 IoU Loss 存在的问题。
YOLOV4 源代码日志解读

- 网络层数:
YOLOV4 总共层数有 161 层,YOLOV3 是 106 层,网络层数增加是非常明显的。
从这个图可以看出,YOLOV4 采用了大量的 1 * 1 卷积,之前介绍过,采用 1 * 1 卷积,是能降低计算量,提升速度的。
- 每列含义
layer : 每层操作名称
filters :卷积核的深度
size/strd(dil):卷积核的尺寸/滑动窗口的步长
input:输入图片的大小
output:输出图片的大小
- 代表性层的含义(需要注意的是,这里隐藏了一个前提条件 padding = 1)
> 第 0 层 conv 卷积操作,表示 608 * 608 * 3 & 3 * 3 * 32 => 608 * 608 * 32,这里 32(输出特征图尺寸深度)
是由卷积核的深度决定的。
> 第 1 层 conv 还是卷积操作,表示 608 * 608 * 32 & 3 * 3 * 64 => 304 * 304 * 64,大家发现没有,输出特征图的尺寸
相比于输入特征图的尺寸,降低了一倍,这是因为滑动窗口的步长变成了 2 。
> 第 7 层 Shortcut,它其实等价于 Add 操作,也就是第 6 层的输出与第 4 层的输出进行卷积,
304 * 304 * 64 & 304 * 304 * 64 => 304 * 304 * 64,输出特征图的尺寸和深度都没有改变。
> 第 9 层 route 操作,它其实等价于 Concat 操作,也就是第 8 层的输出与第 2 层的输出进行卷积,
304 * 304 * 64 & 304 * 304 * 64 => 304 * 304 * 128,输出特征图尺寸不变,深度增加,为两个输入特征图深度之和。
相信大家理解了这些层的含义之后,对于后面的其他层的理解,就比较容易了,下面看看它最后的输出:
76 * 76 * 255, 38 * 38 * 255,19 * 19 * 255,这跟之前介绍 YOLOV4 结构图的输出是相一致的。
引用
//pjreddie.com/media/files/papers/YOLOv3.pdf
//arxiv.org/pdf/2004.10934.pdf
//arxiv.org/pdf/1911.11929v1.pdf
//arxiv.org/pdf/1803.01534.pdf
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。


