快速构建基于Lambda框架大数据业务架构的TBDS Demo指南
- 2019 年 11 月 4 日
- 筆記
1 前言
本文介绍了如何快速的构建一个基于Lambda框架的大数据业务场景的TBDS Demo,用于展示如何利用其对应的工具在腾讯大数据平台上搭建出实时计算、多维分析、离线计算的lambda框架demo。
典型基于Lambda框架的大数据业务架构,如下图所示:

关于TBDS
腾讯大数据处理套件(Tencent Big Data Suite,TBDS)是基于腾讯多年海量数据处理经验,对外提供的可靠、安全、易用的大数据处理平台。更多资讯请点击链接。
1.1 读者对象
本文适用的读者对象为:
- 解决方案架构师
- 产品架构师
- 交付工程师
1.2 Demo组成
本文提供的指南,是用来快速构建一个基于Lambda架构的Demo,主要包含以下三部分:
- 基于Oceanus的实时计算Demo
- 基于Hermes的多维分析Demo
- 基于工作流的任务调度Demo
数据流转图如下所示:

1.3 文档目的
本文旨在达到以下2个目的:
- 在产品售卖的售前阶段,用于向客户展示产品特性;
- 在产品使用的培训期间,用于快速构建开发环境,标准化讲解流程。
1.4 前提条件
对于使用此Demo的人员,基本的要求是:
- 理解实时计算、多维分析、任务调度的概念;
- 掌握Oceanus、Hermes、工作流的基本原理/使用方式。
1.5 工具获取
目前Demo已实现脚本化一键式执行,脚本封装于tbds_lambda_demo工具中,可在本文附件中获取。
工具需要在TBDS集群的Portal主节点上运行,上传并解压工具到Portal主节点的任意目录,例如/opt:
mv tbds_lambda_demo.zip /opt unzip /opt/tbds_lambda_demo.zip
1.6 结构说明
工具的目录结构说明如下
|-- tbds_lambda_demo # 工具主目录 | |-- bin # 存放脚本的目录 | | |-- check_kafka_topic_data.sh # 检查kafka topic数据的脚本 | | |-- check_realtime_calculate_result.sh # 检查实时计算结果的脚本 | | |-- get_access_key.py # 生成Portal认证信息的脚本 | | |-- hermes_demo_test.sh # hermes demo脚本 | | |-- how_to_use_utils_example.sh # 解释如何使用utils脚本的脚本 | | |-- init_hbase.sh # 初始化hbase的脚本 | | |-- init_kafka.sh # 初始化kafka的脚本 | | |-- init_mysql.sh # 初始化mysql的脚本 | | |-- init_oceanus_mysql.sh # 初始化oceanus mysql的脚本 | | |-- init_oceanus.sh # 初始化oceanus的脚本 | | |-- prepare_kafka.sh # 准备kafka数据的脚本 | | |-- realtime_data_collector.sh # 实时数据收集的脚本 | | |-- realtime_data_generator.sh # 实时数据生成的脚本 | | |-- send_message.sh # 发送消息的脚本 | | |-- utils.sh # 通用函数的脚本 | | |-- workflow_demo_clean_all.sh # 工作流环境清理全局脚本 | | |-- workflow_demo_clean_sth.sh # 工作流环境清理脚本 | | |-- workflow_demo_functions.sh # 工作流相关函数的脚本 | | |-- workflow_demo_init_all.sh # 工作流环境初始化全局脚本 | | |-- workflow_demo_init_sth.sh # 工作流环境初始化脚本 | |-- conf # 配置目录 | | |-- clean_hive_wf.sql # 清理工作流hive表的SQL文件 | | |-- clean_mysql_wf.sql # 清理工作流mysql表的SQL文件 | | |-- client_plain.properties # kafka身份认证信息文件 | | |-- hermes_demo_test.conf # hermes demo配置文件 | | |-- init_hbase.cmd # 初始化hbase配置文件 | | |-- init_hive_db_wf.sql # 初始化工作流hive数据库的sql文件 | | |-- init_hive_tables_wf.sql # 初始化工作流hive数据表的sql文件 | | |-- init_mysql.sql # 初始化mysql的sql文件 | | |-- init_mysql_wf.sql # 初始化工作流mysql的sql文件 | | |-- init_oceanus_jobs.sql # 初始化oceanus job的sql文件 | | |-- init_oceanus_jobs.sql_bak # 初始化oceanus job的sql文件 | | |-- init_oceanus_jobs.sql_clean # 初始化oceanus job的sql文件 | | |-- init_oceanus_jobs_template.sql # 初始化oceanus job的sql文件 | | |-- tbds.api.json # 生成Portal认证信息的文件 | | |-- tools.conf # 实时demo配置文件 | | |-- wf_demo.conf # 工作流demo配置文件 | | |-- wf_demo_hermes_test.conf # hermes demo配置文件 | | |-- wf_demo_hive_cal.sql # 工作流hive sql文件 | | |-- wf_demo_hive_query.sql # 工作流hive sql文件 | | |-- workflow_hermesdemo.xml # 工作流定义文件 | | |-- workflow_latest.xml # 工作流定义文件 | |-- prepare_data # 示例数据文件夹 | | |-- age_info.dat # 表age_info数据文件 | | |-- city_id.dat # 表city_id数据文件 | | |-- city_info.dat # 表city_info数据文件 | | |-- contact.dat # 表contact数据文件 | | |-- country_info.dat # 表country_info数据文件 | | |-- dimension_table_data.sql # 维表数据文件 | | |-- education.dat # 表education数据文件 | | |-- gender_id.dat # 表gender_id数据文件 | | |-- gender_info.dat # 表gender_info数据文件 | | |-- id_name.txt # id、name数据文件 | | |-- marriage.dat # 表marriage数据文件 | | |-- occupation.dat # 表occupation数据文件 | | |-- only_id.txt # id数据文件 | | |-- only_name.txt # name数据文件
2 准备工作
2.1 事项说明
在运行TBDS Lambda Demo之前,需要先准备完成下述事项。
2.1.1 创建用户、项目、密钥等
- 创建Portal用户
lambda_demo_user; - 创建Portal项目
lambda_demo_project; - 将用户
lambda_demo_user添加为项目lambda_demo_project的成员,角色为系统管理员、项目管理员、项目开发、项目运维; - 为用户
lambda_demo_user创建一个hadoop模块的密钥。
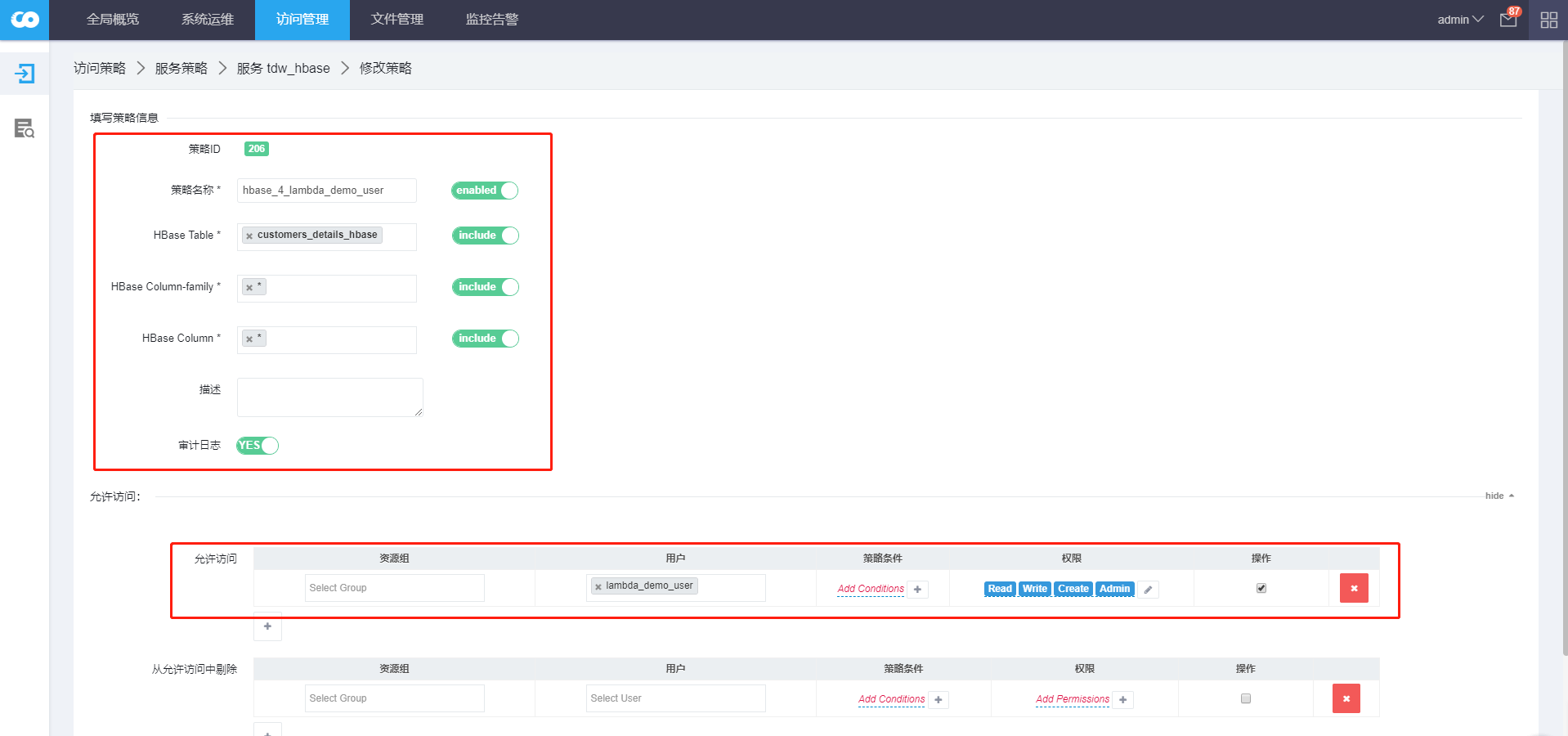
2.1.2 创建策略
- 创建HBase表访问策略
- 策略名:
hbase_4_lambda_demo_user - 表:
customers_details_hbase - 表的列族:
* - 表的列:
* - 策略动作:允许访问
- 用户:
lambda_demo_user - 权限:
read/write/create/admin
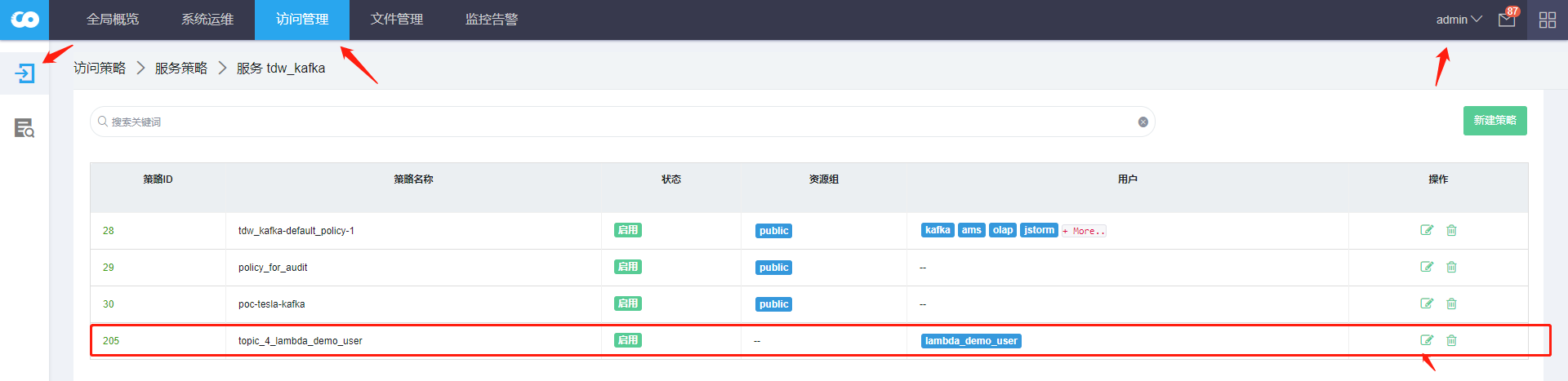
- 策略名:
- 创建Kafka Topic访问策略
- 策略名:
topic_4_lambda_demo_user - Topic名:
customers_balance_details_topic、customers_info_details_topic - 策略动作:允许访问
- 用户:
lambda_demo_user - 权限:
publish/consume/configure/describe/create/delete/kafka admin
2.2 初始化
准备事项的工作已完全实现脚本化,通过执行以下脚本进行初始化工作,即可一键完成以上步骤。

2.2.1 创建用户、项目、密钥等
cd tbds_lambda_demo/bin ./workflow_demo_clean_sth.sh user_project_key ./workflow_demo_init_sth.sh user_project_key

2.2.2 创建策略
cd tbds_lambda_demo/bin ./workflow_demo_clean_sth.sh ranger ./workflow_demo_init_sth.sh ranger

2.3 查看结果
以admin用户登陆Portal页面,查看项目、用户、密钥、策略等是否已正确创建和配置。
2.3.1 查看项目
确认lambda_demo_project项目已创建。

2.3.2 查看用户
确认lambda_demo_user用户已创建,并关联到lambda_demo_project项目。


2.3.3 查看密钥
确认用户lambda_demo_user用户的hadoop模块密钥已创建并开启。

2.3.4 查看策略
确保hbase_4_lambda_demo_user和topic_4_lambda_demo_user策略已正确创建和配置。


3. 基于Oceanus的实时计算Demo
3.1 设计原理
理解实时业务逻辑与设计,本Demo使用Oceanus来完成实时数据的聚合与ETL业务:
- Aggregation业务逻辑:每10秒钟将收到的数据进行累加,以“计算”时间为准,而不是数据时间;
- ETL业务逻辑:实时的将收到的每一条数据加上id所对应的name后同时写入到kafka的topic和hbase表中。


3.2 前提条件
请确保以下前提条件得以满足:
- 在portal主节点上执行demo的脚本;
- portal节点上安装了以下客户端:
- hbase client
- kafka client
3.3 生成demo
实时流业务Demo初始化步骤如下:
1.进入bin目录中初始化数据:
cd tbds_lambda_demo/bin ./init_oceanus.sh
2.执行如下脚本模拟实时数据生成:
./realtime_date_generator.sh <send_interval> <total_send_messages>
其中:
send_interval:生成的每一条数据发送的间隔,例如2s代表每2秒发送一条数据;total_send_messages:总共发送数据的条目数量,例如1000代表总共发送1000条数据。
例如:
./realtime_data_generator.sh 2s 1000
正常运行样例如下:

通过该界面,可直观的观察到实时产生的数据。
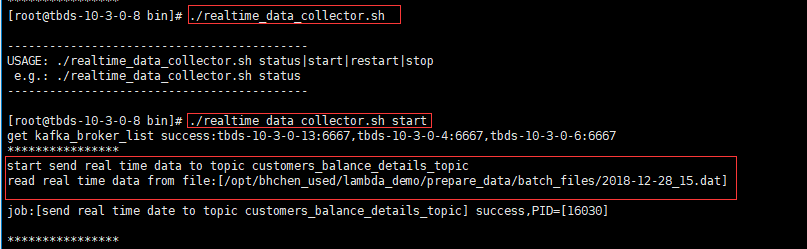
3.执行如下脚本采集实时数据至kafka topic:
./realtime_data_collector.sh start
正常运行的截图如下:
4.以lambda_demo_user用户登录portal,并进入到“实时计算”模块,查看其中实时计算任务,示例如下:

任务说明:
910009:用SQL实现的oceanus应用,业务逻辑为每10秒钟做一次聚合运算,并将聚合运算结果存到MYSQL数据库中;910010:用画布实现的与910009同样功能的应用,因此910009与910010只能启动其中一个;910011:用画布实现的实时数据ETL逻辑,并将结果写入到hbase表和kafka的topic中。具体业务逻辑比较简单,点开应用可获取到详细信息。
注意:测试时请启动910011和910009(或910010)。
3.4 查看结果
查看实时计算结果脚本名称为check_realtime_calculate_result.sh,脚本用法如下:
cd tbds_lambda_demo/bin ./check_realtime_calculate_result.sh kafka|hbase|mysql

3.4.1 MySQL结果
查看10秒聚合一次的结果:
cd tbds_lambda_demo/bin ./check_realtime_calculate_result.sh mysql
正常运行截图如下:
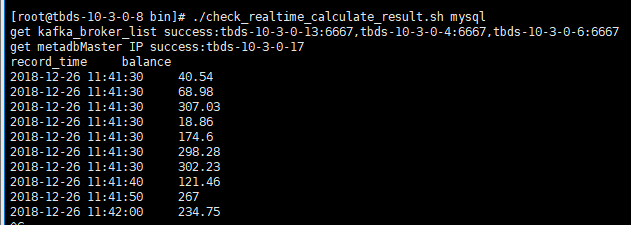
打印规则为2s中获取一次最新的数据,输出最新的10条。
3.4.2 Kafka结果
查看实时处理后写入kafka topic的结果
cd tbds_lambda_demo/bin ./check_realtime_calculate_result.sh kafka
正常运行截图如下:

输出规则为实时刷新。
3.4.3 HBase结果
查看实时处理后写入hbase中的结果:
cd tbds_lambda_demo/bin ./check_realtime_calculate_result.sh hbase
正常运行截图如下:

打印规则为2s中获取一次最新的数据,输出最新的10条。
4 基于Hermes的多维分析Demo
4.1 设计原理
后台模拟实时生成客户的数据至kafka,然后在TBDS的实时计算任务处理后再把结果落地到kafka的另外一个topic,hermes侧再把新的kafka数据采集到hermes中,最终用户在hermes中对数据进行查询使用。
4.2 配置文件
配置conf/tools.conf中的两个参数,使用默认配置亦可。其中:
detail_topic:一定要和Oceanus Demo中的910011任务最终落地到kafka新topic名一致;hermes_table_name:kafka中的数据会导入此表中,表名自行定义(确保表名不要和已有的表重名,后面开始测试会先删除此表)。
4.3 生成demo
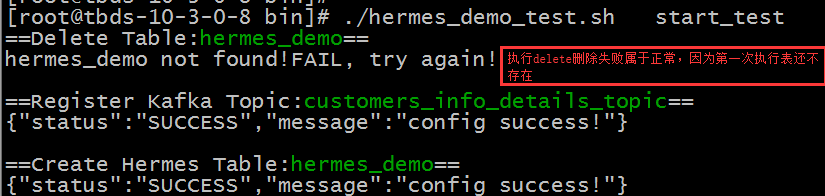
执行以下脚本:
./hermes_demo_test.sh start_test
执行后,脚本会先将测试表删除,再在hermes中注册topic信息,最后创建hemers测试表,结果输出如下,确保register和create结果是成功的。
4.4 其他功能
hermes_demo_test.sh脚本中封装了一些其他功能,可单独执行调用hermes的接口进行调试,脚本中涉及到的kafka topic即为tools.conf中配置的detail_topic,hermes表也是tools.conf中配置的hermes_table_name。
使用方法:
hermes_demo_test.sh <parameter> USAGE: ./hermes_demo_test.sh start_test|del|reg|list|select|create|desc|export|check_export
其中,参数说明如下:
del:只做删除表操作,删除的表为tools.conf中配置的hermes_table_name;reg:注册kafka topic到hermes,注册的topic为detail_topic;create:在hermes中创建表,字段和属性都在脚本中已硬编码,若有变化需要修改脚本;list:列出hermes表分区信息;select:查询当天分区的数据;desc:列出表的属性信息;export:导出表数据;check_export:查询导出进度。
5 构建基于工作流的任务调度Demo
5.1 设计原理
5.1.1 架构图
本Demo的设计囊括一个离线数据处理的全流程,包括模拟数据生成、数据导入、数据离线计算、数据分析查询、数据导出等多个环节,其架构和数据流转如下所示:

说明如下:
- 真实的业务场景中,数据从客户系统中产生。本Demo利用自动化脚本模拟数据的生成,先以csv数据格式的形式存放在本地文件系统中,是为模拟数据生成;
- 通过自动化脚本,分别将数据从本地文件系统中导入到不同的源中,模拟真实业务场景下客户各种的数据源,比如HDFS文件系统、FTP服务器、MySQL数据库等;
- 通过工作流任务调度,将HDFS、FTP、MySQL三种数据源中的数据分别导入到Hive中,以Hive表形式存储到TBDS平台中,是为数据导入;
- 通过工作流任务调度,将上述导入的Hive表进行关联计算,得出结果表并重新落地到Hive中,是为离线数据计算;
- 通过工作流任务调度,对离线计算所得结果表进行分析查询,并将结果出库Hive重新导入到MySQL数据库中,是为数据分析查询和数据导出。
5.1.2 demo流程
本Demo已完全由自动化脚本实现,但工作流任务本身的运行需手动执行,全流程如下图所示:

具体步骤如下,
脚本化执行部分:
- 清理工作;
- 模拟数据生成;
- 数据上传到HDFS;
- 数据上传到FTP;
- 数据导入到MySQL;
- 数据导入到Hive;
- 创建工作流服务器配置、工作流及上传定义文件。
手动执行部分:
- 提交工作流任务运行的申请;
- 管理员(本Demo设定为admin用户)审批;
- 运行工作流任务,查看结果。
5.1.3 表结构与关系图
表数据的示例,以及表与表之间的关系如下:
5.2 前提条件
运行本Demo前,需具备以下前提条件:
- 确保TBDS集群中以下服务运行正常:
- TBDS Portal
- HDFS
- FTP on HDFS
- MetaDB(或CDB)
- Hive
- Lhotse
- TBDS Authorizer
- 第2章节中的Demo准备工作已完成;
- 基于Oceanus的实时计算Demo中的
init_oceanus.sh和realtime_data_generator.sh脚本已运行,产生了实时数据并已从本地文件系统上传到以下HDFS目录/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/hdfsData/balance; - 运行脚本的操作请在Portal节点上执行,且要求Portal节点安装了以下组件
- HDFS client
- FTP client
- MySQL Client
5.3 配置文件
修改配置文件conf/wf_demo.conf中以下配置项
portalAdminPW:admin用户的密码,如123456;portalMySQLPW:portal节点上MySQL DB的root用户密码,例如[email protected]。
其余配置项按默认值即可,均不需要修改。
5.4 执行Demo脚本
执行以下步骤即可一键生成Demo
1.执行workflow_demo_init_all.sh脚本
cd tbds_lambda_demo/bin chmod +x ./*.sh ./workflow_demo_init_all.sh
2.正常运行的输出结果如下:

5.5 检查工作
执行完工作流Demo初始化的脚本后,在运行工作流调度任务前,需要确保以下几项检查工作。
5.5.1 HDFS数据
1.检查以下目录是否已成功创建:
|
序号 |
目录 |
|---|---|
|
1 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/hdfsData |
|
2 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/ftp2HdfsData |
执行命令:
xportCmd=`/data/tools/getkey.py hdfs` $exportCmd hdfs dfs -ls /user/lambda_demo_user/tbdsLambdaDemo/wfDemo/

2.检查以下数据文件是否已成功上传:
|
序号 |
数据文件 |
|---|---|
|
1 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/hdfsData/age_info.dat |
|
2 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/hdfsData/education.dat |
|
3 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/hdfsData/id_name.txt |
|
4 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/hdfsData/occupation.dat |
执行命令:
hdfs dfs -ls /user/lambda_demo_user/tbdsLambdaDemo/wfDemo/hdfsData

5.5.2 FTP数据
1.检查以下目录是否已成功创建:
|
序号 |
目录 |
|---|---|
|
1 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/ftpData |
执行命令:
cd lambda_demo/bin ftpHost=`./utils.sh ftpServerList | head -n 1` ftpPort="2222" ftp -n <<EOF open $ftpHost $ftpPort user lambda_demo_user lambda_demo_user ls /user/lambda_demo_user/tbdsLambdaDemo/wfDemo/ bye EOF

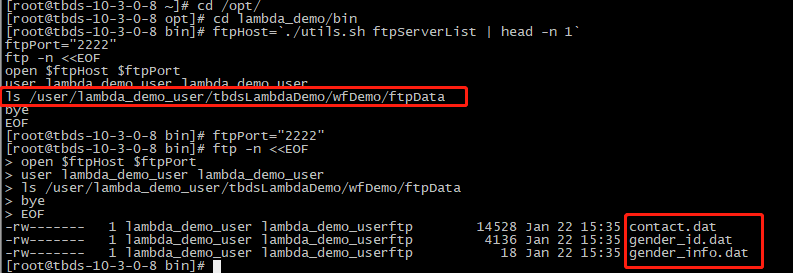
2.检查以下数据文件是否已成功上传到上述已创建的目录 :
|
序号 |
数据文件 |
|---|---|
|
1 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/ftpData/ contact.dat |
|
2 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/ftpData/ gender_id.dat |
|
3 |
/user/lambda_demo_user/tbdsLambdaDemo/wfDemo/ftpData/ gender_info.dat |
执行命令:
cd lambda_demo/bin ftpHost=`./utils.sh ftpServerList | head -n 1` ftpPort="2222" ftp -n <<EOF open $ftpHost $ftpPort user lambda_demo_user lambda_demo_user ls /user/lambda_demo_user/tbdsLambdaDemo/wfDemo/ftpData bye EOF
5.5.3 MySQL数据
1.连接到MetaDB/CDB MySQL服务器,执行以下命令:
cd lambda_demo/bin source ../conf/wf_demo.conf metadbMaster=`./utils.sh metadbMaster` mysql -u$metaDbMasterUser -p$metaDbMasterPW -h$metadbMaster

2.检查以下数据库是否已成功创建:
|
序号 |
数据库 |
|---|---|
|
1 |
lambda_demo_db |
成功连接到MetaDB/CDB MySQL后,执行命令:
show databases;

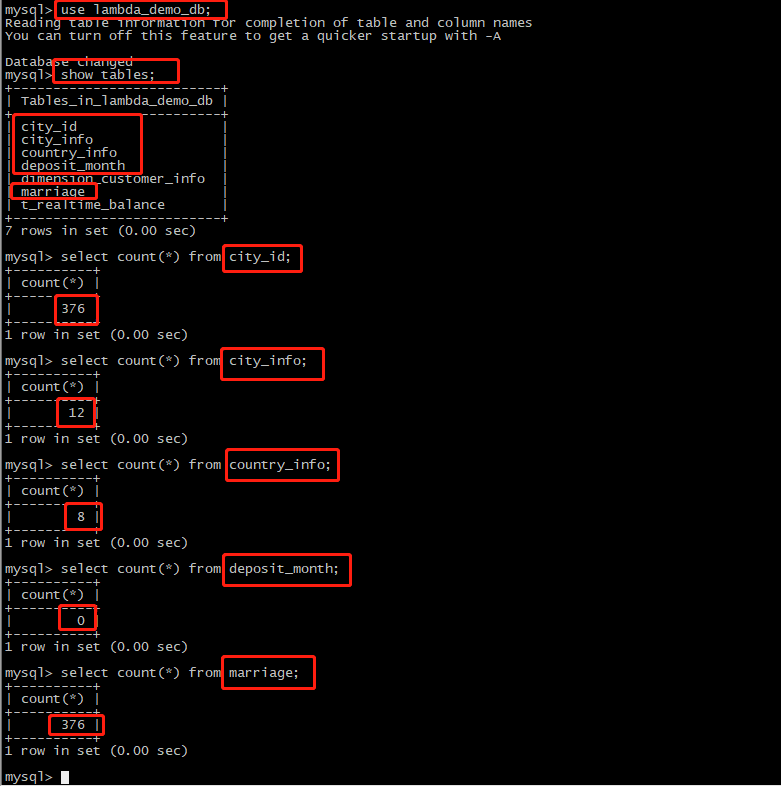
3.若数据库已成功创建,检查以下数据表是否已成功创建,且对应条目数符合预期:
|
序号 |
数据表 |
条目数 |
|---|---|---|
|
1 |
city_id |
376 |
|
2 |
city_info |
12 |
|
3 |
country_info |
8 |
|
4 |
deposit_month |
0 |
|
5 |
marriage |
376 |
4.成功连接到MetaDB/CDB MySQL后,执行命令:
use lambda_demo_db; show tables; select count(*) from city_id; select count(*) from city_info; select count(*) from country_info; select count(*) from deposit_month; select count(*) from marriage;
5.5.4 Hive表
1.连接到Hive Server,执行以下命令:
cd lambda_demo/bin source ../conf/wf_demo.conf zkList=`./utils.sh zkList` hiveServerConnectStr="jdbc:hive2://$zkList/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2" beeline -u "$hiveServerConnectStr" -n$portalAdmin -p$portalAdminPW
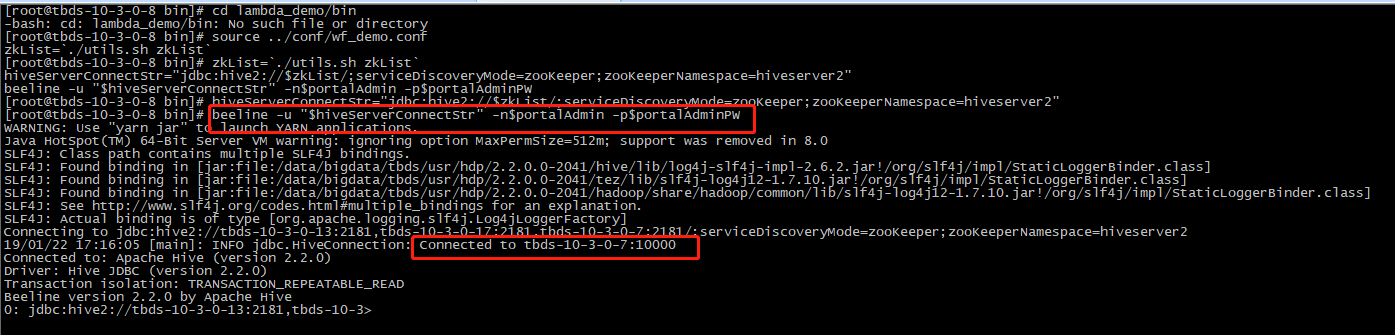
2.检查以下数据库是否已成功创建:
|
序号 |
数据库 |
|---|---|
|
1 |
lambda_demo_db |
成功连接到Hive Server后,执行命令:
show databases;

3.若数据库已成功创建,检查以下数据表是否已成功创建,且对应条目数符合预期:
|
序号 |
数据表 |
条目数 |
|---|---|---|
|
1 |
age_info |
0 |
|
2 |
city_id |
0 |
|
3 |
city_info |
0 |
|
4 |
contact |
0 |
|
5 |
country_info |
0 |
|
6 |
deposit_date |
0 |
|
7 |
education |
0 |
|
8 |
gender_id |
0 |
|
9 |
gender_info |
0 |
|
10 |
marriage |
0 |
|
11 |
occupation |
0 |
|
12 |
person |
0 |
|
13 |
trans_deposit |
0 |
成功连接到Hive Server后,执行命令:
use lambda_demo_db; show tables; select count(*) from age_info; select count(*) from city_id; select count(*) from city_info; select count(*) from contact; select count(*) from country_info; select count(*) from deposit_date; select count(*) from education; select count(*) from gender_id; select count(*) from gender_info; select count(*) from marriage; select count(*) from occupation; select count(*) from person; select count(*) from trans_deposit;
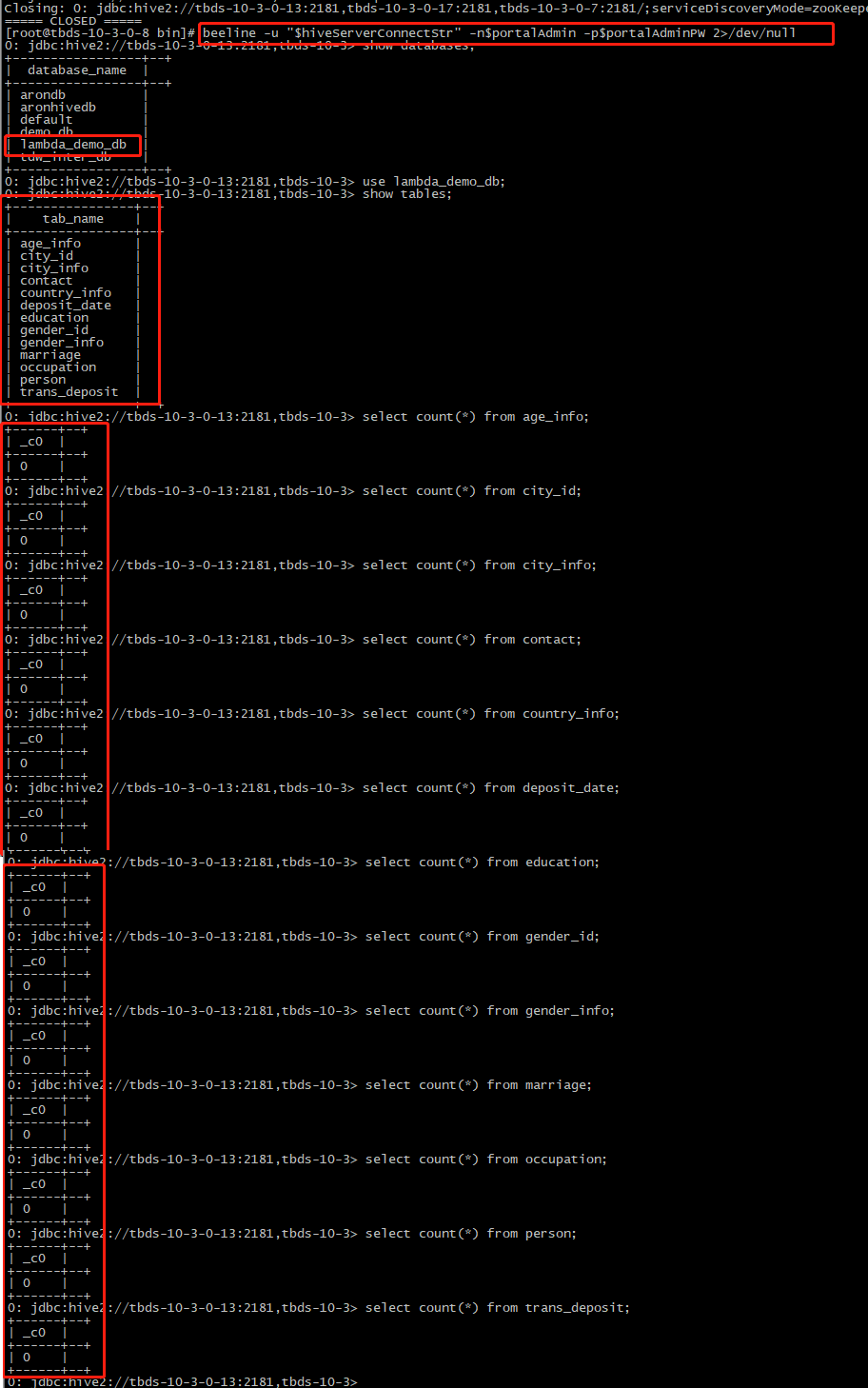
5.5.5 Portal页面
1.用户
用户lambda_demo_user已创建,初始密码为lambda_demo_user,验证能够以该用户登陆Portal页面。

2.项目
进入平台管理->项目管理,验证项目lambda_demo_project已创建,

项目成员包含两位,即admin和lambda_demo_user,角色均为operator/dev/projectManager。
3.密钥
进入用户管理->密钥管理,搜索lambda_demo_user,验证已为lambda_demo_user创建一个hadoop模块的密钥并已启用。
4.工作流服务器配置
进入工作流 -> 服务器配置,验证已成功创建以下4个工作流服务器配置
|
序号 |
类型 |
服务器标识 |
|---|---|---|
|
1 |
Hive |
hive_lambda_demo |
|
2 |
FTP |
ftp_lambda_demo |
|
3 |
HDFS |
hdfs_lambda_demo |
|
4 |
MySQL |
mysql_lambda_demo |

确保服务器均为可用状态,可点击操作->编辑进行验证。

5.工作流文件夹与定义文件
进入工作流 -> 工作流,验证已成功创建workflow_lambda_demo_folder工作流文件夹和文件workflow_lambda_demo,其定义能够点击打开并展示如下。

5.6 运行Demo任务
1.先点击保存工作流:

2.在工作流任务定义中,从上而下依次右键任务,点击运行:

注:如果运行失败,可以尝试点击编辑任务,然后保存任务,再点击运行任务进行尝试。

5.7 查看结果
5.7.1 Hive表
1.连接到Hive Server,执行以下命令:
cd lambda_demo/bin source ../conf/wf_demo.conf zkList=`./utils.sh zkList` hiveServerConnectStr="jdbc:hive2://$zkList/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2" beeline -u "$hiveServerConnectStr" -n"$portalAdmin" -p"$portalAdminPW" 2>/dev/null
2.检查以下数据表的数据是否已成功从各数据源导入Hive和通过Hive SQL生成,且对应条目数符合预期:
|
序号 |
数据表 |
条目数 |
|---|---|---|
|
1 |
age_info |
376 |
|
2 |
city_id |
376 |
|
3 |
city_info |
12 |
|
4 |
contact |
376 |
|
5 |
country_info |
8 |
|
6 |
deposit_date |
不定 |
|
7 |
education |
376 |
|
8 |
gender_id |
376 |
|
9 |
gender_info |
2 |
|
10 |
marriage |
376 |
|
11 |
occupation |
376 |
|
12 |
person |
376 |
|
13 |
trans_deposit |
不定 |
各数据表:
表age_info
select count(*) from lambda_demo_db.age_info; select * from lambda_demo_db.age_info limit 5;

表city_id
select count(*) from lambda_demo_db.city_id; select * from lambda_demo_db.city_id limit 5;

表city_info
select count(*) from lambda_demo_db.city_info; select * from lambda_demo_db.city_info limit 5;

表contact
select count(*) from lambda_demo_db.contact; select * from lambda_demo_db.contact limit 5;
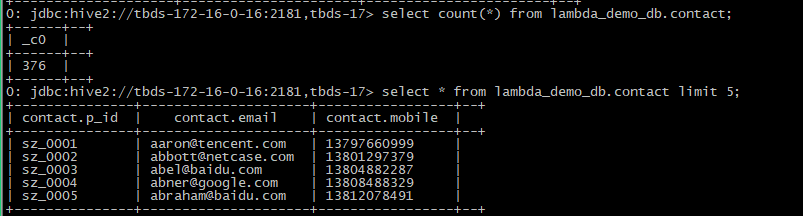
表country_info
select count(*) from lambda_demo_db.country_info; select * from lambda_demo_db.country_info limit 5;

表deposit_date
select count(*) from lambda_demo_db.deposit_date; select * from lambda_demo_db.deposit_date limit 5;

表education
select count(*) from lambda_demo_db.education; select * from lambda_demo_db.education limit 5;

表gender_id
select count(*) from lambda_demo_db.gender_id; select * from lambda_demo_db.gender_id limit 5;

表gender_info
select count(*) from lambda_demo_db.gender_info; select * from lambda_demo_db.gender_info limit 5;

表marriage
select count(*) from lambda_demo_db.marriage; select * from lambda_demo_db.marriage limit 5;

表occupation
select count(*) from lambda_demo_db.occupation; select * from lambda_demo_db.occupation limit 5;

表person
select count(*) from lambda_demo_db.person; select * from lambda_demo_db.person limit 5;

表trans_deposit
select count(*) from lambda_demo_db.trans_deposit; select * from lambda_demo_db.trans_deposit limit 5;

5.7.2 MySQL表
1.连接到MetaDB/CDB MySQL服务器,执行以下命令:
cd tbds_lambda_demo/bin source ../conf/wf_demo.conf metadbMaster=`./utils.sh metadbMaster` mysql -u$metaDbMasterUser -p$metaDbMasterPW -h$metadbMaster
2.检查以下数据表的数据是否已导入成功,且对应条目数符合预期:
|
检查项 |
序号 |
数据表 |
条目数 |
|---|---|---|---|
|
MySQL |
1 |
deposit_month |
376(无特殊情况下) |
表deposit_month
select count(*) from lambda_demo_db.deposit_month; select * from lambda_demo_db.deposit_month limit 5;

附录
工具包下载