【目标检测】:SPP-Net深入理解(从R-CNN到SPP-Net)
- 2020 年 8 月 4 日
- 筆記
- Deep Learning, 目标检测
一. 导论
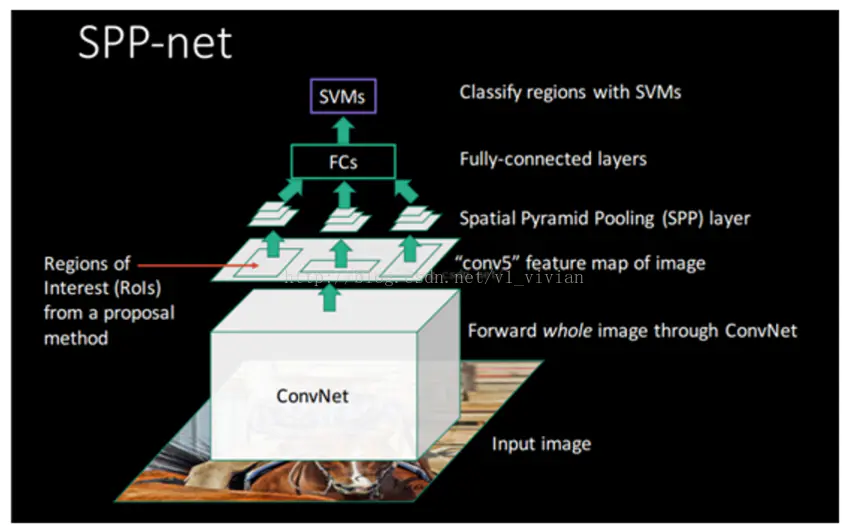
SPP-Net是何凯明在基于R-CNN的基础上提出来的目标检测模型,使用SPP-Net可以大幅度提升目标检测的速度,检测同样一张图片当中的所有目标,SPP-Net所花费的时间仅仅是RCNN的百分之一,而且检测的准确率甚至会更高。那么SPP-Net是怎么设计的呢?我们要想理解SPP-Net,先来回顾一下RCNN当中的知识吧。下图为SPP-Net的结构:
二. RCNN
rcnn进行目标检测的框架如下:
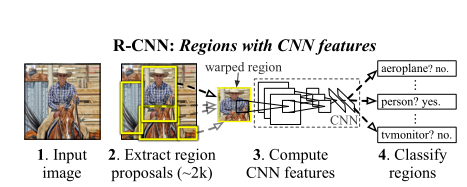
因此RCNN的步骤如下:
1.将图像输入计算机当中
2.利用selective search算法找到图片当中属于同一个物体的区域,并使用Bounding Box圈起来。这个算法不属于深度学习的算法,而是一种传统算法,这个算法不能够在GPU上运行,只能在CPU上运行,因此相比于SPP-Net具有一定的局限性。它是根据图像当中的各个部位的颜色,轮廓,纹理等将图像当中的事物进行分类。一共筛选出1-2k个候选区域,用region proposal来表示。
3. 将得到的候选区域全部进行剪裁或者缩放将其变为统一的大小,这样才可以使用图像分类神经网络(AlexNet/Google InceptionNet/VGG)对每一个候选区域进行图像识别。因此这一步我们需要进行1-2k次卷积运算,对于时间而言非常不划算。
4.最后使用SVM分类器将候选区域当中的所有图片通过全连接层进行分类,查看看是否为我们所需要检测的目标,并且输出其名称,如:人,飞机,电视机等等。同时进行bounding box的回归,这样可以使得预测的bounding box的大小和位置更加准确。在论文当中bounding-box的回归公式如下:

最后使用SVM分类器而没有使用softmax分类器的原因是在RCNN当中使用SVM后分类结果的准确率会更高(根据实验得知),论文当中的说明如下:

mAP的大小表示的是目标检测的准确率,是目标检测领域中一种重要的评价指标。整体而言R-CNN的实现还是颇为简单的,也很容易被人们所想到,这个算法在当时也是非常优越的,使用selective search的方法代替了之前做目标检测所使用的滑动窗口法来生成候选区域,不然的话使用滑动窗口法针对每个图像进行卷积运算我们可能不仅仅要进行1-2K次运算,最后运算的次数很可能是10k-50k次,这在时间上来说太不划算了,而且使用滑动窗口法还可能滑动的窗口没有框到目标,因此会丢失掉准确率。SVM分类最后的输出是每个图像bounding box的形状大小,位置以及每一个bounding box内图像分类的结果以及概率。
那么我们的SPP-Net在这之上做了哪些改进呢?
三. SPP-Net
SPP-Net发现在RCNN当中使用selective search的方法生成候选区域实在是太耗费时间了,因为所有生成的候选区域都要进行一次卷积运算来进行图像分类,那么我们能不能够直接只计算一次卷积而非1-2k次卷积呢?因此在SPP-Net当中我们省略掉了生成候选区域这一步,直接将图像做一次卷积运算,并且在卷积神经网络CNN之后增加了图像空间金字塔池化(SSP-Spatial Pyramid Pooling)的结构,这样就可以根据图像的特征将图像当中的目标区域进行分类。SPP-Net和RCNN的区别如下图所示: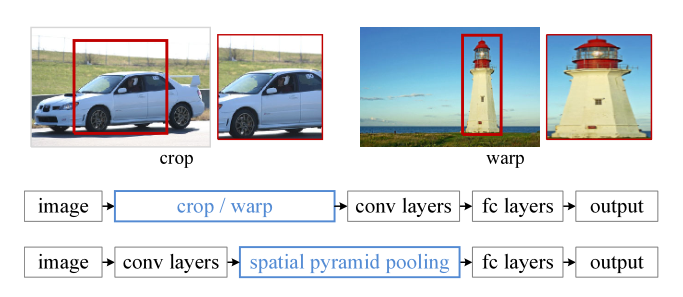
可以从上看出,图像输入到网络中之后,RCNN将候选区域进行了剪裁和缩放,然后再把剪裁好的区域“喂”入到CNN当中,而spp-net则直接将整张图片放入了卷积神经网络当中,然后使用spatial pytamid pooling(空间金字塔池化)提取卷积之后的特征,最后使用全连接神经网络连同最后的输出和空间金字塔池化层。在整个spp-net当中最为重要的结构则是我们用红色字体标注出的spatial pytamid pooling(空间金字塔池化层)了。那么整个结构是如何实现的呢?
四.空间金字塔池化结构
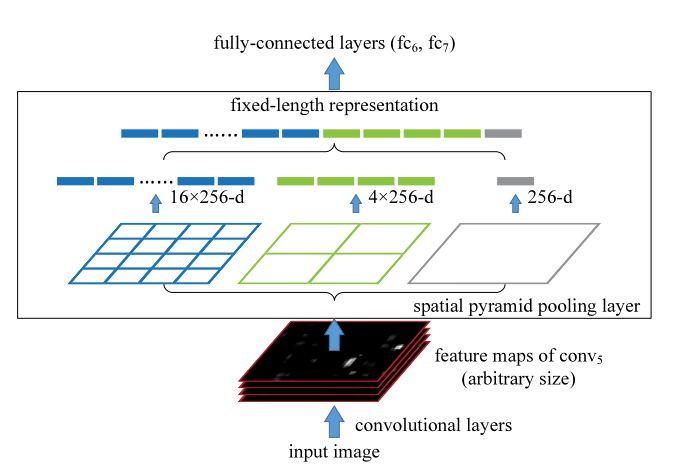
空间金字塔池化层的结构如上所示,Image经过一次卷积之后会得到256个特征图,也就是上面图中最下面的一连串黑色堆叠图,这是整个卷积神经网络的第五层吗,因此称为conv5。然后我们使用SSP结构对这256个特征图进行处理,将这256张特征图分别进行1*1,2*2,4*4的最大池化,也就是分别选取这256个特征图当中的最大值,然后最后的输出也是256个每一层特征图的最大值。比如我们做空间金字塔池化最右边的那个1*1池化,计算机仅仅会选取这256个特征图当中最大的值作为输出的结果作为图像的语义特征,这也就是最大池化,2*2的最大池化同理,但我们会做完2*2的最大池化之后会得到4个数值,每一个数值都代表这图像某一区域的特征。因此最后我们会得到21(21=4*4+1*1+2*2)*256=5376个数值作为图像高度抽象的特征。之后将这5376个特征送入全连接神经网络(fc6和fc7,一共两层全连接神经网络,这个完全看研究员自己的喜好来设定了,可以没有,也可以多层),最后用SVM分类器输出bounding box的x,y,w,h以及每一个bounding box的图象分类的结果。小编在网上查看了很多教程都没有把空间金字塔池化结构解释清楚,也是自己想了很久认真研读了论文好几遍才明白,毕竟论文上这一点其实也没讲得多清楚。最后输出的结果如下图所示:

那么为什么我们可以作这样的处理呢?我们来看看论文当中是怎么说的,下图来自于spp-net的论文:

在图的左边,(a)代表了我们进行目标检测的图像,(b)上面的那张图是卷积神经网络的第175层输出的结果,我们将其可视化了,下面的那张特征图是卷积神经网络第55层的输出结果,我们也将其可视化了。我们发现汽车的窗户正好在第175层的conv layer发现了这个特征,并且高亮的了出来是白色,在图像上表示为这个区域的灰度是很大的(有0-255个数字,因此这个高亮的地方数值可能在200以上)。这个时候第55层的特征图发现了汽车的轮胎这一个特征,在特征图当中也高亮了出来。这也是最后我们在金字塔池化层做最大池化的原因,因为最大池化就会将高亮的地方的特征提取出来,我们只提取图像当中具有物体的特征,从而忽略掉其他没有无体的地方的特征,最后再全连接神经网络当中进行特征融合并归类,就可以得到目标检测的结果了!是不是很神奇呢?
终于写完啦,如果觉得读了小编的文章您有收获的话,不要忘记了点击下方的“推荐”哦!您的支持就是对小编创作最大的动力!

