Java源码解析|HashMap的前世今生
- 2019 年 10 月 19 日
- 筆記
HashMap的前世今生
Java8在Java7的基础上,做了一些改进和优化。
底层数据结构和实现方法上,HashMap几乎重写了一套
所有的集合都新增了函数式的方法,比如说forEach,也新增了很多好用的函数。
前世——Java 1.7
底层数据结构
数组 + 链表
在Java1.7中HashMap使用数组+链表来作为存储结构
数组就类似一个个桶构成的容器,链表用来解决冲突,当出现冲突时,就找到当前数据应该存储的桶的位置(数组下标),在当前桶中插入新链表结点。
如下图所示:
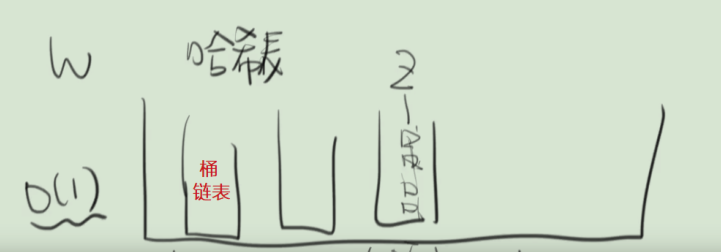
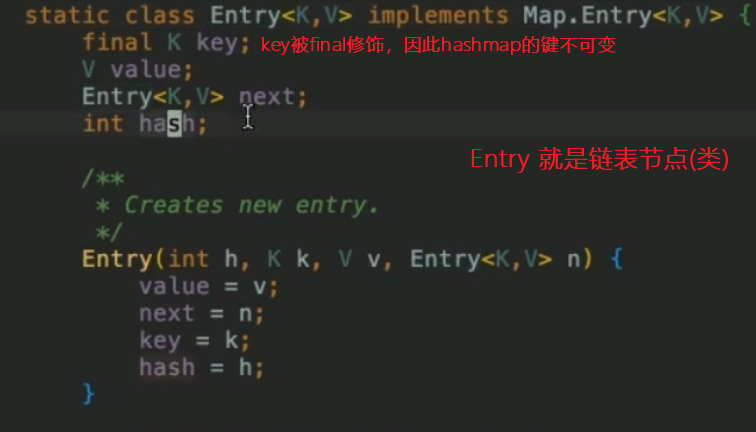
链表结点中存放(key,value)键值对
扩容与初始化
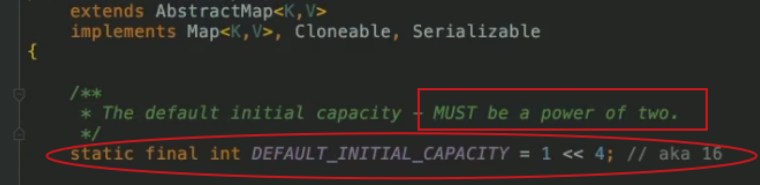
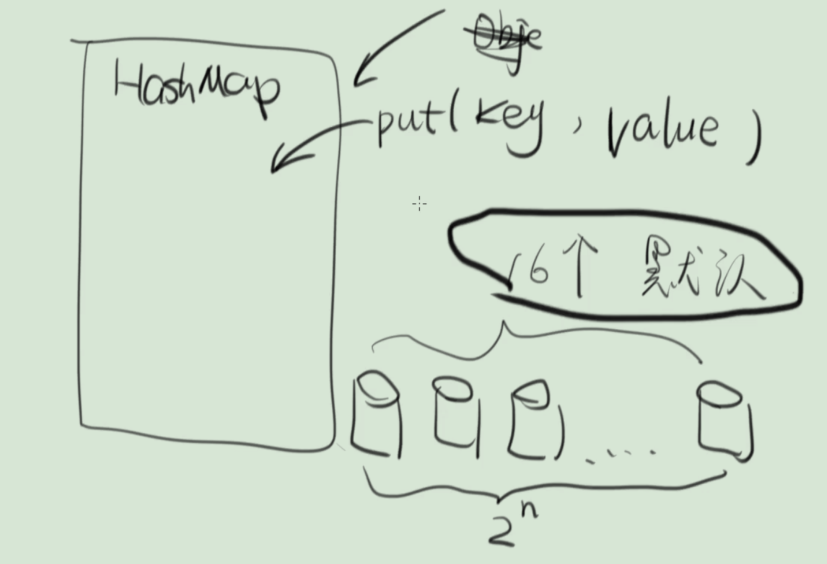
初始化:初始时,HashMap的数组大小(桶个数)默认为16,且数组大小必须是2的幂次方
看下图源码注释所示
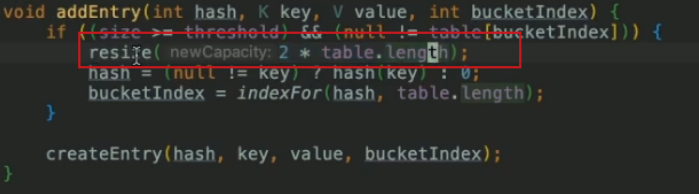
resize方法扩容
什么时候扩容?
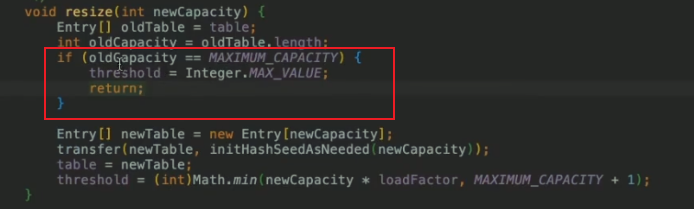
桶里链表结点元素超过threshole变量= 16 * 扩容因子0.75 = 12个时开始扩容

限定扩容最大值为Integer的大小
-
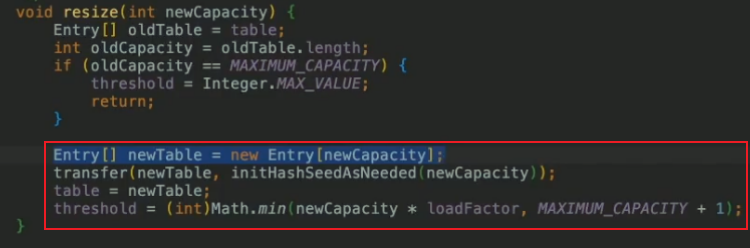
扩容一倍:
-
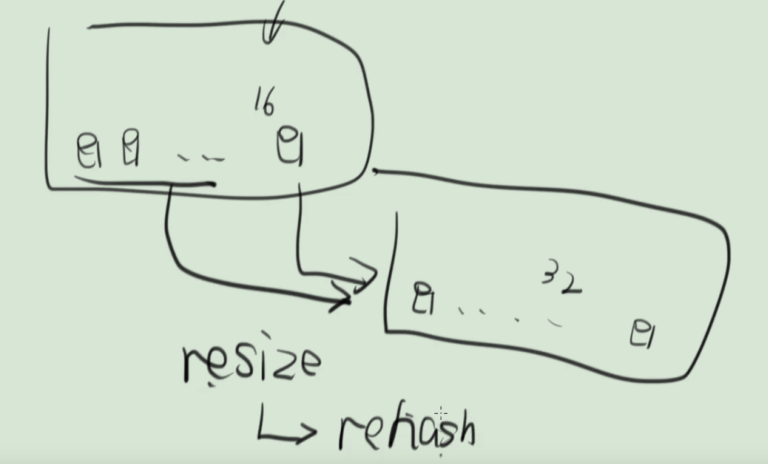
怎么扩容:开辟新的数组(桶),使用transfer方法将旧数组数据拷贝到新数组中,部分元素重写计算hash值(rehash)
-
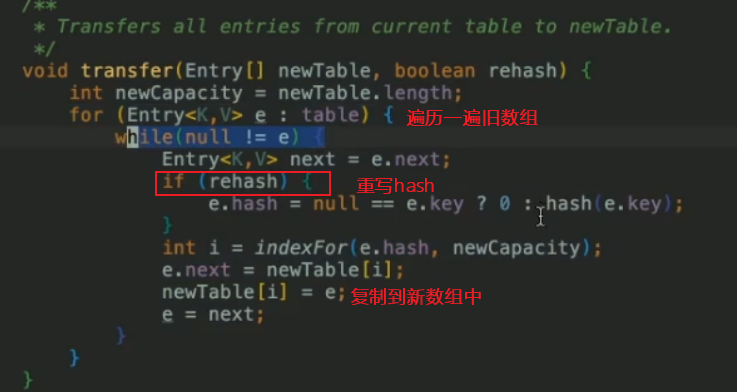
transfer函数,把旧表的桶搬到新的桶
遍历每一个桶的链表,重新rehash,indexFor拿到新表的下标,放到新表
hash算法
- 为什么数组的大小必须为2的幂呢
我们在求key的hash值在数组的下标的方法中发现 数组设置为2的幂,是为了在求模转成位运算时,恰好可以得到数组下标

举个栗子:比如,假设 数组长度为2的5次方,也就是32个长度,我们拿key的hash值(32位)与数组长度作&与运算,就能得到一个在数组长度范围内的下标,这个下标就是当前key应该在表table的位置了。
看下图演示吧:
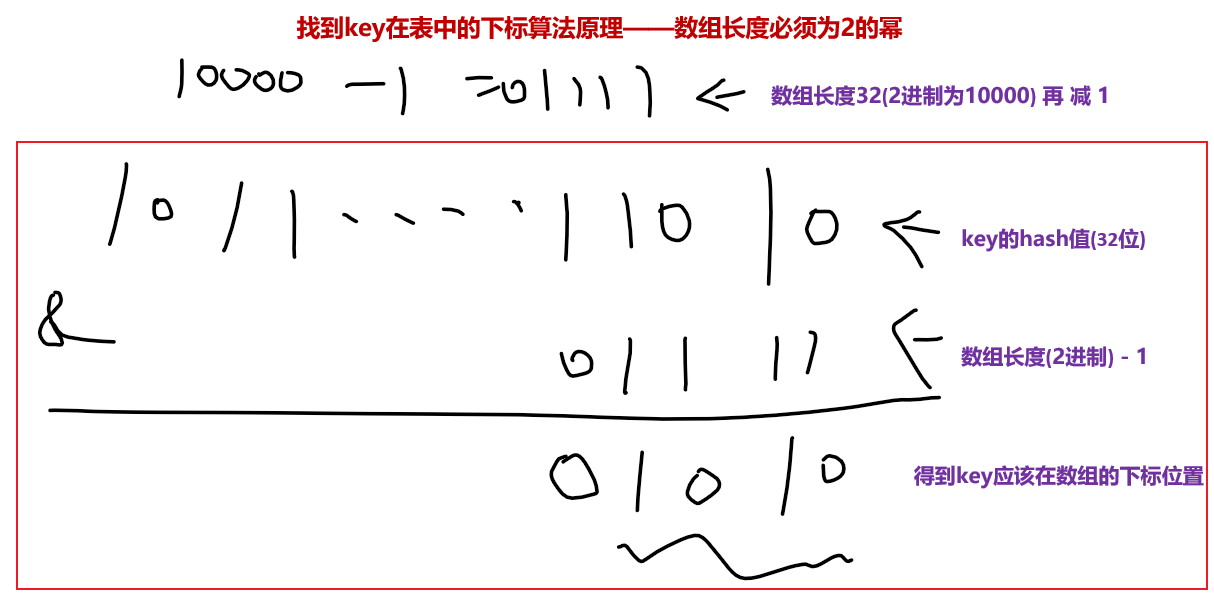
所以数组大小必须规定为2的幂的原因就是为了hash算法将来计算key在数组中的index下标。
由key得到hashcode的算法,在1.7中比较复杂,就不过多陈述了。
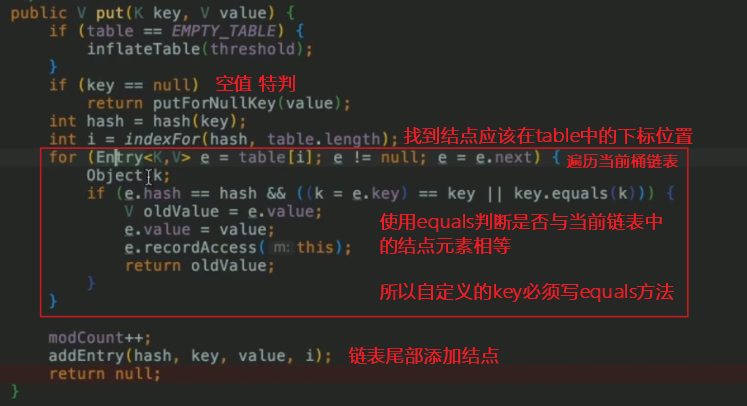
put方法
- 需要使用equals方法比较key,所以自定义的类需要重载equals方法
- 因此也推荐使用String这种已经重写equals方法的类作为键key。

遗留问题:安全、死锁
1.hashmap1.7线程不安全
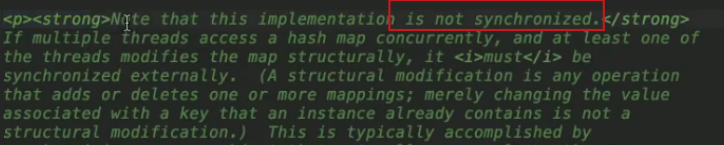
并发下并发下,扩容时,需要使用transfer函数拷贝链表数据,有坑,容易出现死循环链表,死锁
2.hash碰撞的安全问题
Java1.7中的hash算法会出现碰撞,可以通过恶意请求引发DOS
如下,hash值相同
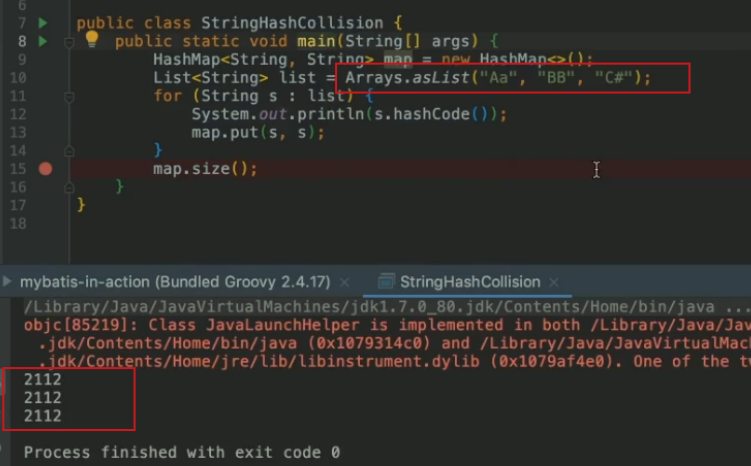
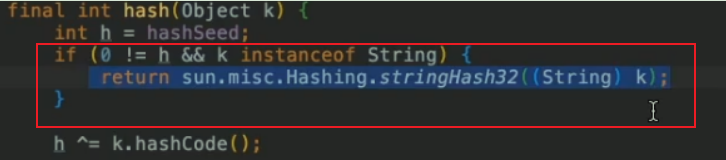
解决方法:换一种hash计算方法

今生——Java 1.8
底层数据结构
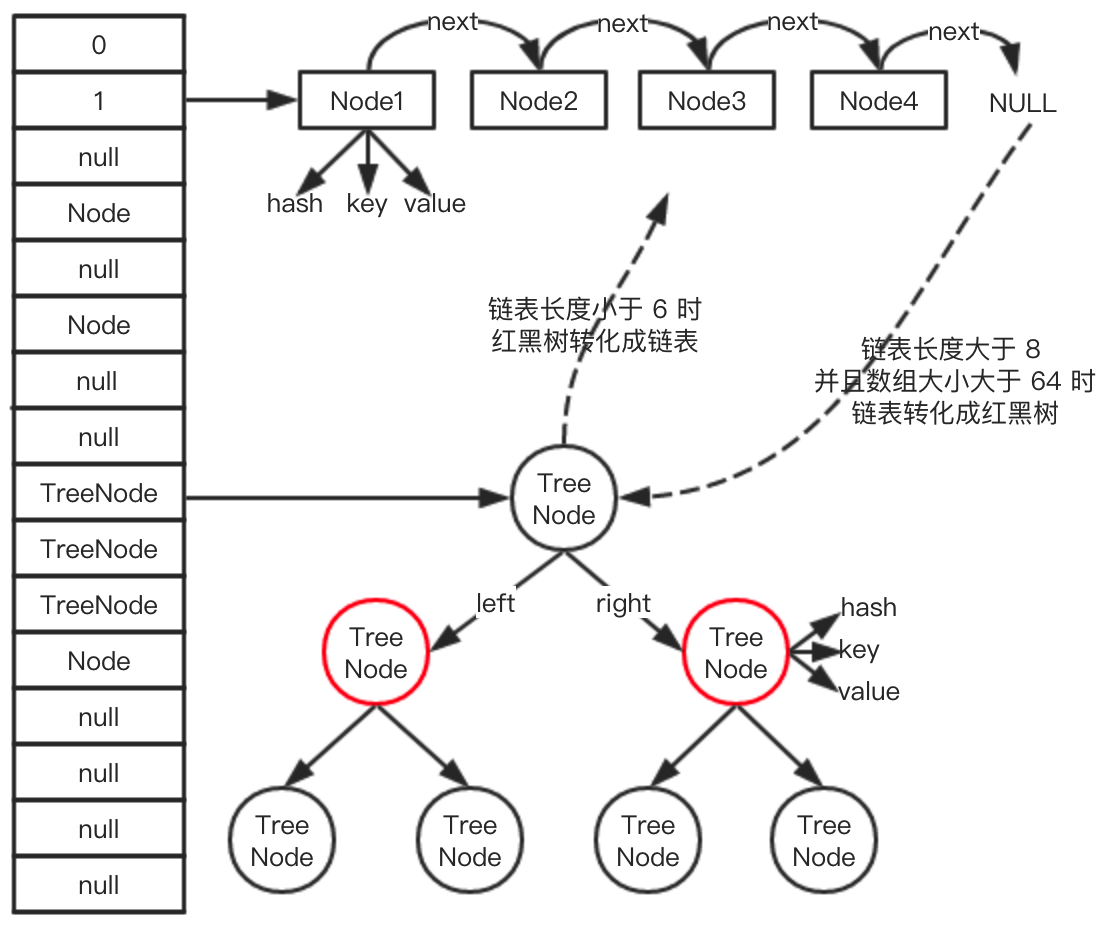
- HashMap底层的数据结构是:数组+链表+红黑树。
- 当链表的长度大于等于8时,链表会转化成红黑树;
- 当红黑树的大小小于等于6时,红黑树会转化成链表;
整体的数据结构如下:
扩容与初始化
常见属性:
//初始容量为 16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //最大容量 static final int MAXIMUM_CAPACITY = 1 << 30; //负载因子默认值 static final float DEFAULT_LOAD_FACTOR = 0.75f; //桶上的链表长度大于等于8时,链表转化成红黑树 static final int TREEIFY_THRESHOLD = 8; //桶上的红黑树大小小于等于6时,红黑树转化成链表 static final int UNTREEIFY_THRESHOLD = 6; //当数组容量大于 64 时,链表才会转化成红黑树 static final int MIN_TREEIFY_CAPACITY = 64; //记录迭代过程中 HashMap 结构是否发生变化,如果有变化,迭代时会 fail-fast transient int modCount; //HashMap 的实际大小,可能不准(因为当你拿到这个值的时候,可能又发生了变化) transient int size; //存放数据的数组 transient Node<K,V>[] table; // 扩容的门槛,有两种情况 // 如果初始化时,给定数组大小的话,通过 tableSizeFor 方法计算,数组大小永远接近于 2 的幂次方,比如你给定初始化大小 19,实际上初始化大小为 32,为 2 的 5 次方。 // 如果是通过 resize 方法进行扩容,大小 = 数组容量 * 0.75 int threshold; //链表的节点 static class Node<K,V> implements Map.Entry<K,V> { //红黑树的节点 static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>- 可以看到初始容量为16,最大容量为2的30次方
- 当数组容量大于 64 时,并且链表结点数>=8时,链表才会转化成红黑树
而转化成红黑树的概率是非常小的(千万分之一),原因是一个合适的hash计算不会很少出现多次碰撞
在考虑设计链表结点数>=8这个值的时候,我们参考了泊松分布概率函数,由泊松分布中得出结论,链表各个长度的命中概率为:
* 0: 0.60653066 * 1: 0.30326533 * 2: 0.07581633 * 3: 0.01263606 * 4: 0.00157952 * 5: 0.00015795 * 6: 0.00001316 * 7: 0.00000094 * 8: 0.00000006意思是,当链表的长度是8的时候,出现的概率是0.00000006,不到千万分之一,所以说正常情况下,链表的长度不可能到达8,而一旦到达8时,肯定是hash 算法出了问题,所以在这种情况下,为了让HashMap仍然有较高的查询性能,所以让链表转化成红黑树,我们正常写代码,使用HashMap时,几乎不会碰到链表转化成红黑树的情况。
- 扩容
扩容有两种情况:
-
如果初始化时,给定数组大小的话,通过 tableSizeFor 方法计算,数组的容量大小会近似一下,数组大小永远是 2 的幂次方,比如你给定初始化大小 19,实际上初始化大小为 32,也就是 2 的 5 次方。
-
如果是通过 resize 方法进行扩容,当大小 > 数组容量 * 0.75进行resize
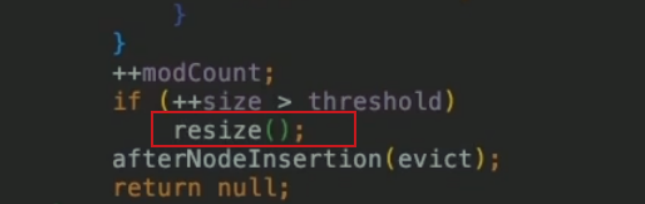
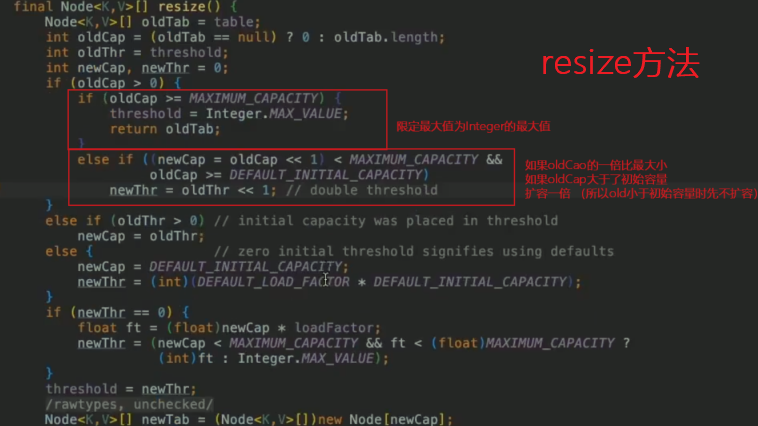
- 扩容后拷贝原来的table,像java1.7的transfer函数,java1.8中保持顺序复制,线程仍然不安全
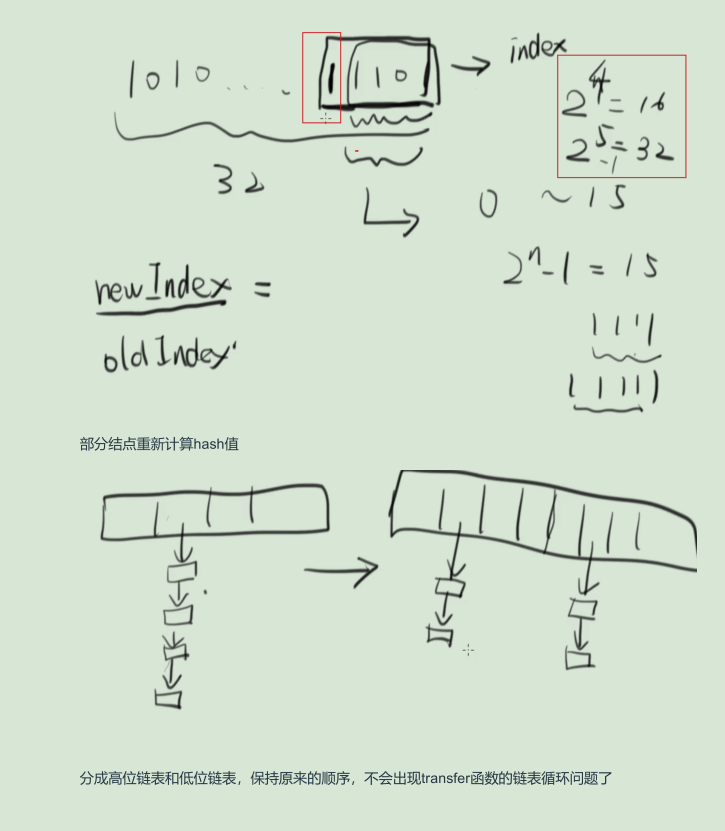
-
扩容时的高低位链表 不太懂。
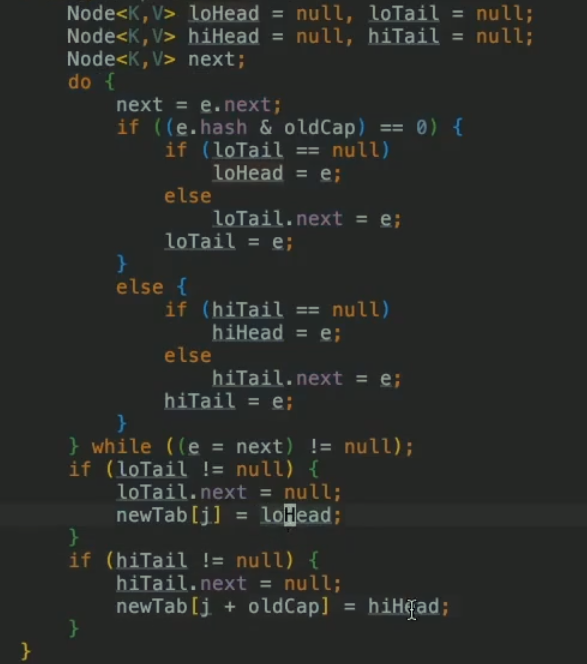
-
resize效率低,需要拷贝,所以初始化时最好指定一定的容量,避免频繁扩容带来的性能问题。
put插入方法
- HashMap新增结点步骤如下:

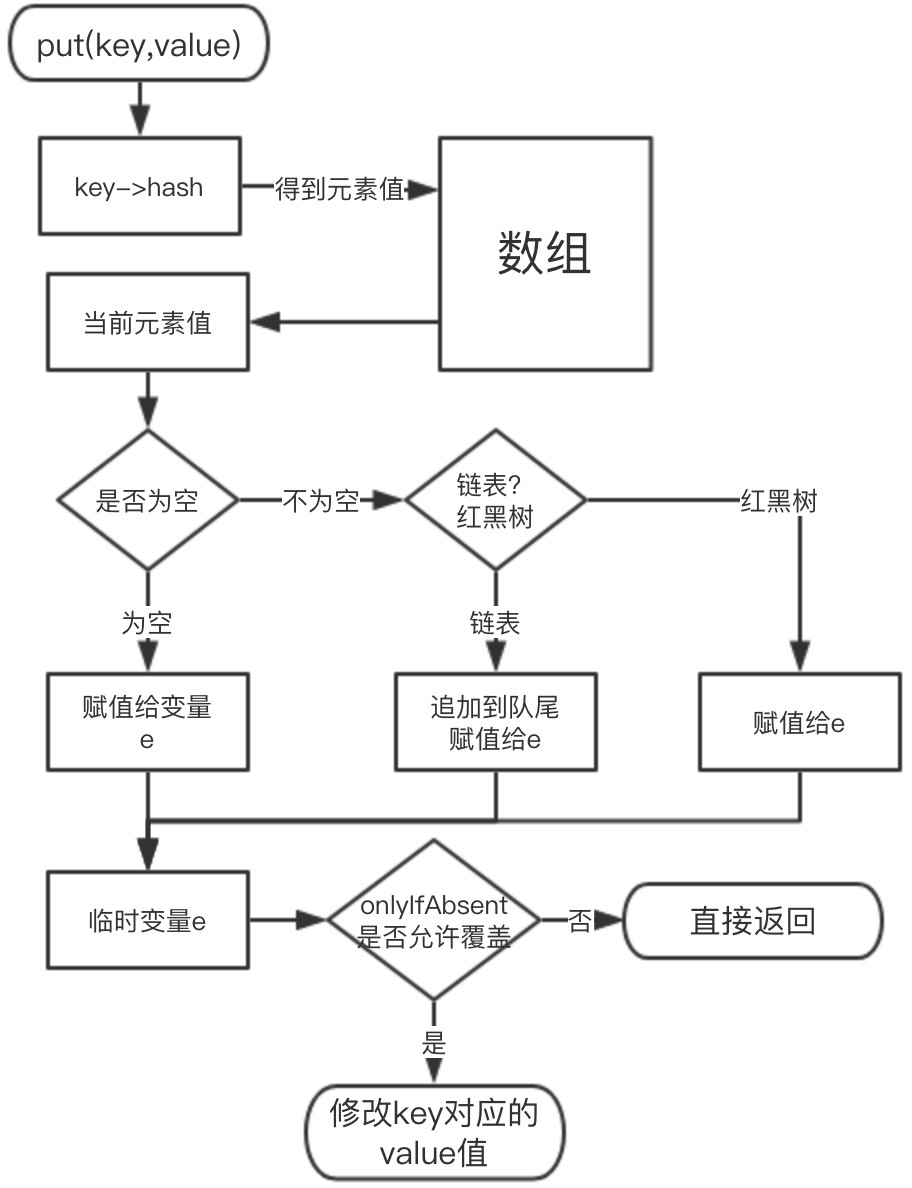
- put的部分代码如下
// 入参 hash:通过 hash 算法计算出来的值。 // 入参 onlyIfAbsent:false 表示即使 key 已经存在了,仍然会用新值覆盖原来的值,默认为 false final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // n 表示数组的长度,i 为数组索引下标,p 为 i 下标位置的 Node 值 Node<K,V>[] tab; Node<K,V> p; int n, i; //如果数组为空,使用 resize 方法初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 如果当前索引位置是空的,直接生成新的节点在当前索引位置上 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 如果当前索引位置有值的处理方法,即我们常说的如何解决 hash 冲突 else { // e 当前节点的临时变量 Node<K,V> e; K k; // 如果 key 的 hash 和值都相等,直接把当前下标位置的 Node 值赋值给临时变量 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果是红黑树,使用红黑树的方式新增 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 是个链表,把新节点放到链表的尾端 else { // 自旋 for (int binCount = 0; ; ++binCount) { // e = p.next 表示从头开始,遍历链表 // p.next == null 表明 p 是链表的尾节点 if ((e = p.next) == null) { // 把新节点放到链表的尾部 p.next = newNode(hash, key, value, null); // 当链表的长度大于等于 8 时,链表转红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash);//树化 break; } // 链表遍历过程中,发现有元素和新增的元素相等,结束循环 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //更改循环的当前元素,使 p 在遍历过程中,一直往后移动。 p = e; } } // 说明新节点的新增位置已经找到了 if (e != null) { V oldValue = e.value; // 当 onlyIfAbsent 为 false 时,才会覆盖值 if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); // 返回老值 return oldValue; } } // 记录 HashMap 的数据结构发生了变化 ++modCount; //如果 HashMap 的实际大小大于扩容的门槛,开始扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }如果数组有了key,但不想覆盖 value,可以选择putlfAbsent方法,这个方法有个内置变量onlylfAbsent,内置是true,就不会覆盖,我们平时使用的put方法,内置onlylfAbsent为false,是允许覆盖的。
- 链表新增结点:把新结点添加到链表尾部就行了。
- 红黑树新增结点步骤如下

//入参 h:key 的hash值 final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v) { Class<?> kc = null; boolean searched = false; //找到根节点 TreeNode<K,V> root = (parent != null) ? root() : this; //自旋 for (TreeNode<K,V> p = root;;) { int dir, ph; K pk; // p hash 值大于 h,说明 p 在 h 的右边 if ((ph = p.hash) > h) dir = -1; // p hash 值小于 h,说明 p 在 h 的左边 else if (ph < h) dir = 1; //要放进去key在当前树中已经存在了(equals来判断) else if ((pk = p.key) == k || (k != null && k.equals(pk))) return p; //自己实现的Comparable的话,不能用hashcode比较了,需要用compareTo else if ((kc == null && //得到key的Class类型,如果key没有实现Comparable就是null (kc = comparableClassFor(k)) == null) || //当前节点pk和入参k不等 (dir = compareComparables(kc, k, pk)) == 0) { if (!searched) { TreeNode<K,V> q, ch; searched = true; if (((ch = p.left) != null && (q = ch.find(h, k, kc)) != null) || ((ch = p.right) != null && (q = ch.find(h, k, kc)) != null)) return q; } dir = tieBreakOrder(k, pk); } TreeNode<K,V> xp = p; //找到和当前hashcode值相近的节点(当前节点的左右子节点其中一个为空即可) if ((p = (dir <= 0) ? p.left : p.right) == null) { Node<K,V> xpn = xp.next; //生成新的节点 TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn); //把新节点放在当前子节点为空的位置上 if (dir <= 0) xp.left = x; else xp.right = x; //当前节点和新节点建立父子,前后关系 xp.next = x; x.parent = x.prev = xp; if (xpn != null) ((TreeNode<K,V>)xpn).prev = x; //balanceInsertion 对红黑树进行着色或旋转,以达到更多的查找效率,着色或旋转的几种场景如下 //着色:新节点总是为红色;如果新节点的父亲是黑色,则不需要重新着色;如果父亲是红色,那么必须通过重新着色或者旋转的方法,再次达到红黑树的5个约束条件 //旋转: 父亲是红色,叔叔是黑色时,进行旋转 //如果当前节点是父亲的右节点,则进行左旋 //如果当前节点是父亲的左节点,则进行右旋 //moveRootToFront 方法是把算出来的root放到根节点上 moveRootToFront(tab, balanceInsertion(root, x)); return null; } } }- 有关红黑树还需要补充知识点(占坑)
get查找方法
链表查询的时间复杂度是O(n),红黑树的查询复杂度是O(log(n)。在链表数据不多的时候,使用链表进行遍历也比较快,只有当链表数据比较多的时候,才会转化成红黑树,但红黑树需要的占用空间是链表的2倍,考虑到转化时间和空间损耗,所以我们需要定义出转化的边界值,链表结点>=8时才进行树化。
-
HashMap查找步骤:

- 链表查找 key是自定义类时需要重写equals方法(来比较链表结点值是否相等)
// 采用自旋方式从链表中查找 key,e 初始为为链表的头节点 do { // 如果当前节点 hash 等于 key 的 hash,并且 equals 相等,当前节点就是我们要找的节点 // 当 hash 冲突时,同一个 hash 值上是一个链表的时候,我们是通过 equals 方法来比较 key 是否相等的 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; // 否则,把当前节点的下一个节点拿出来继续寻找 } while ((e = e.next) != null);- 红黑树查找 key是自定义类时需要重写compator方法(来判断红黑树往左子结点走还是往右走)

hash算法精简
使用异或计算hash,拿高16位异或低16位
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } key 在数组中的位置公式:tab[(n - 1) & hash]- h^(h>>>16),这么做的好处是使大多数场景下,算出来的hash值比较分散。
hash 值算出来之后,要计算当前key在数组中的索引下标位置时,可以采用对数组长度取模,但是取模操作对于处理器的计算是比较慢的,数学上有个公式,当b是2的幂次方时,a%b=a&(b-1),所以此处索引位置的计算公式我们可以更换为:(n-1)&hash。

因为树有可能退化到链表状态,所以红黑树是一个二叉平衡树,通过自旋来调整高度
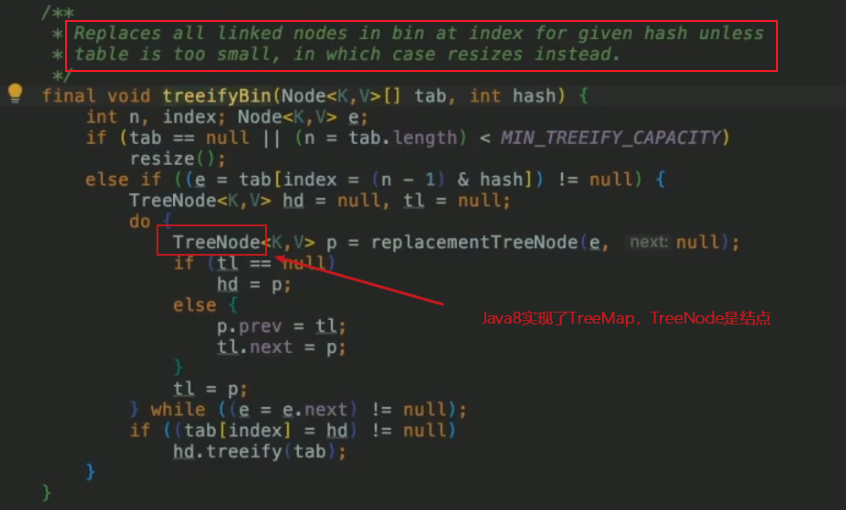
新增方法
- getOrDefault方法:如果 key 对应的值不存在,返回期望的默认值 defaultValue
public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? defaultValue : e.value; }- putlfAbsent(K key,V value):如果map中存在key了,那么value就不会覆盖,如果不存在key,新增成功。
- compute 方法:允许我们把 key和value的值进行计算后,再put到map中,为防止key值不存在造成未知错误,
- computelfPresent方法:表示只有在key存在的时候,才执行计算
public void compute(){ HashMap<Integer,Integer> map = Maps.newHashMap(); map.put(10,10); log.info("compute 之前值为:{}",map.get(10)); map.compute(10,(key,value) -> key * value); log.info("compute 之后值为:{}",map.get(10)); // 还原测试值 map.put(10,10); // 如果为 11 的 key 不存在的话,需要注意 value 为空的情况,下面这行代码就会报空指针 // map.compute(11,(key,value) -> key * value); // 为了防止 key 不存在时导致的未知异常,我们一般有两种办法 // 1:自己判断空指针 map.compute(11,(key,value) -> null == value ? null : key * value); // 2:computeIfPresent 方法里面判断 map.computeIfPresent(11,(key,value) -> key * value); log.info("computeIfPresent 之后值为:{}",map.get(11)); } 结果是: compute 之前值为:10 compute 之后值为:100 computeIfPresent 之后值为:null(这个结果中,可以看出,使用 computeIfPresent 避免了空指针)从前世到今生的奈何桥——default
- Java8在集合类上新增了很多方法,为什么Java7中这些接口的的实现者不需要强制实现这些方法呢?
主要是因为这些新增的方法被default 关键字修饰了,default一旦修饰接口上的方法,我们需要在接口的方法中写默认实现,并且子类无需强制实现这些方法,所以Java7接口的实现者无需感知。
总结:HashMap的三生三世
Java8在Java7的基础上,做了一些改进和优化,通过default关键字来连接两代。HashMap几乎重写了一套,所有的集合都新增了函数式的方法,比如说forEach,也新增了很多好用的函数。
