scrapy爬蟲案例–爬取陽關熱線問政平台
- 2021 年 5 月 8 日
- 筆記
陽光熱線問政平台://wz.sun0769.com/political/index/politicsNewest?id= …
Continue Reading陽光熱線問政平台://wz.sun0769.com/political/index/politicsNewest?id= …
Continue Reading
Scrapy Scrapy是純python實現的一個為了爬取網站數據、提取結構性數據而編寫的應用框架。 Scrapy使用 …
Continue Reading
筆者最近對scrapy的學習可謂如火如荼,雖然但是,即使是一整天地學習下來也會有中間兩三個小時的「無效學習」,不是筆者開 …
Continue ReadingSelenium是一個Web的自動化測試工具,最初是為網站自動化測試而開發的,可以按指定的命令自動操作,但是他需要與第三 …
Continue ReadingBeautiful Soup 是一個HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 數據。 一 …
Continue Reading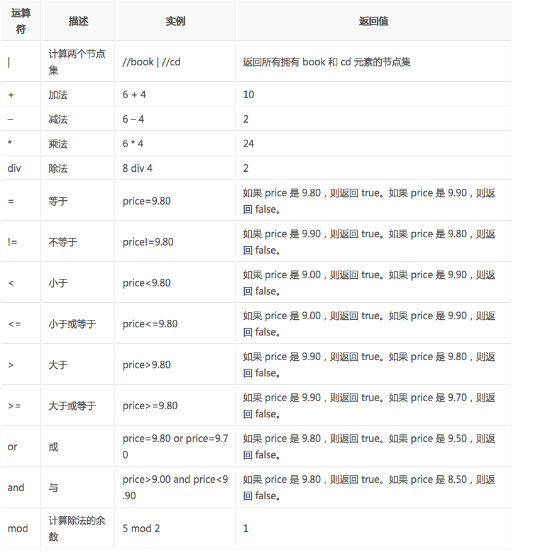
使用lxml之前,我們首先要會使用XPath。利用XPath,就可以將html文檔當做xml文檔去進行處理解析了。 一、 …
Continue Reading一、什麼是正則表達式? 正則表達式,又稱規則表達式,通常被用來檢索、替換那些符合某個模式(規則)的文本。 正則表達式是對 …
Continue Readingurllib3是一個功能強大,對SAP健全的 HTTP客戶端,許多Python生態系統已經使用了urllib3。 一、安 …
Continue Readingurllib是Python中請求url連接的官方標準庫,在Python3中將Python2中的urllib和urllib …
Continue Reading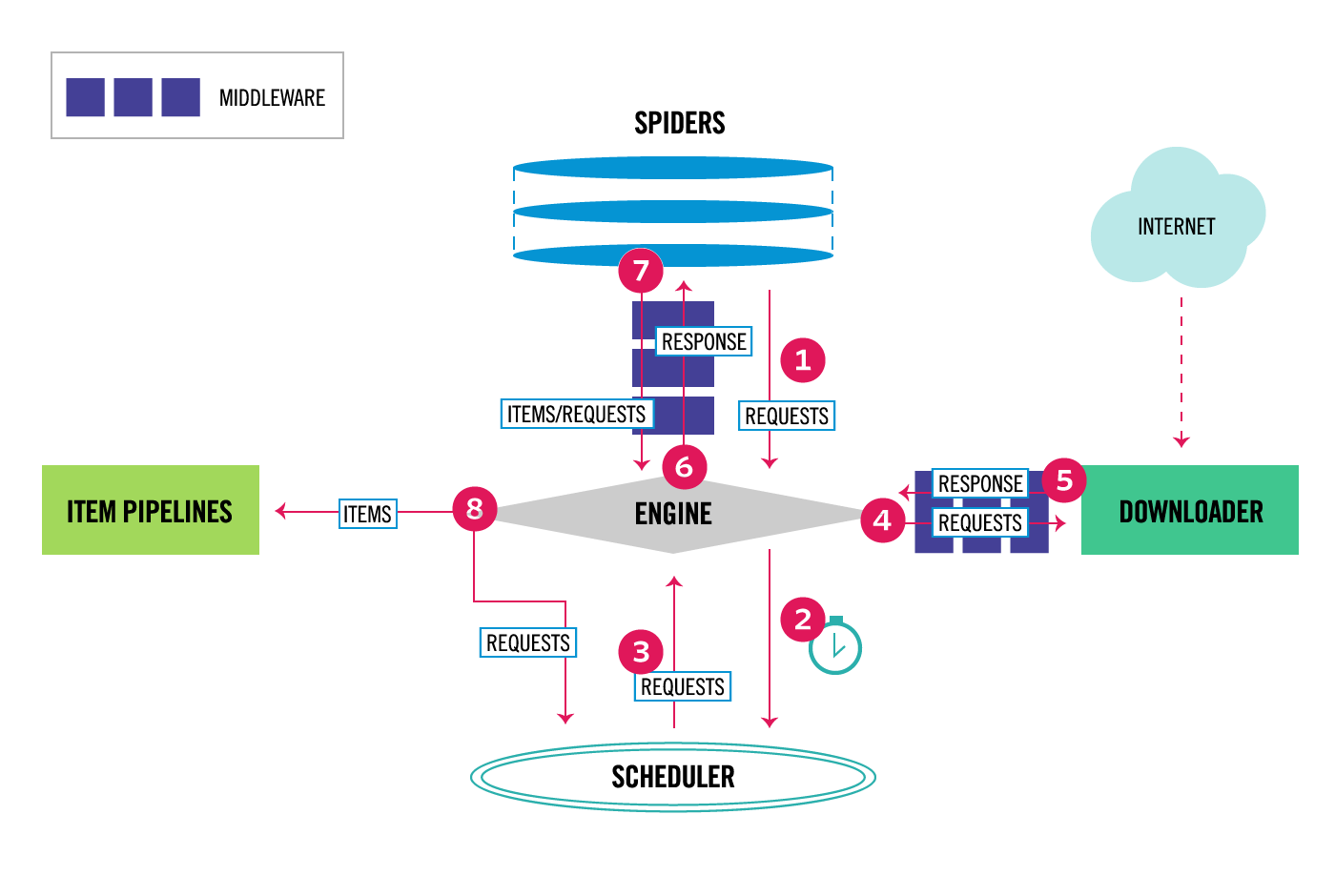
基於Scrapy的B站爬蟲 最近又被叫去做爬蟲了,不得不拾起兩年前搞的東西。 說起來那時也是突發奇想,想到做一個B站的爬 …
Continue Reading