
分散式機器學習:同步並行SGD演算法的實現與複雜度分析(PySpark)
- 2022 年 6 月 26 日
- 筆記
1 分散式機器學習概述 大規模機器學習訓練常面臨計算量大、訓練數據大(單機存不下)、模型規模大的問題,對此分散式機器學習 …
Continue Reading1 分散式機器學習概述 大規模機器學習訓練常面臨計算量大、訓練數據大(單機存不下)、模型規模大的問題,對此分散式機器學習 …
Continue Reading
摘要:對於Spark用戶而言,藉助Volcano提供的批量調度、細粒度資源管理等功能,可以更便捷的從Hadoop遷移到K …
Continue Reading最近要在 Spark job 中通過 Spark SQL 的方式讀取 Elasticsearch 數據,踩了一些坑,總結 …
Continue Reading
1. PageRank的兩種串列迭代求解演算法 我們在部落格《數值分析:冪迭代和PageRank演算法(Numpy實現)》演算法 …
Continue Reading
1. 梯度計算式導出 我們在部落格《統計學習:邏輯回歸與交叉熵損失(Pytorch實現)》中提到,設\(w\)為權值(最後 …
Continue Reading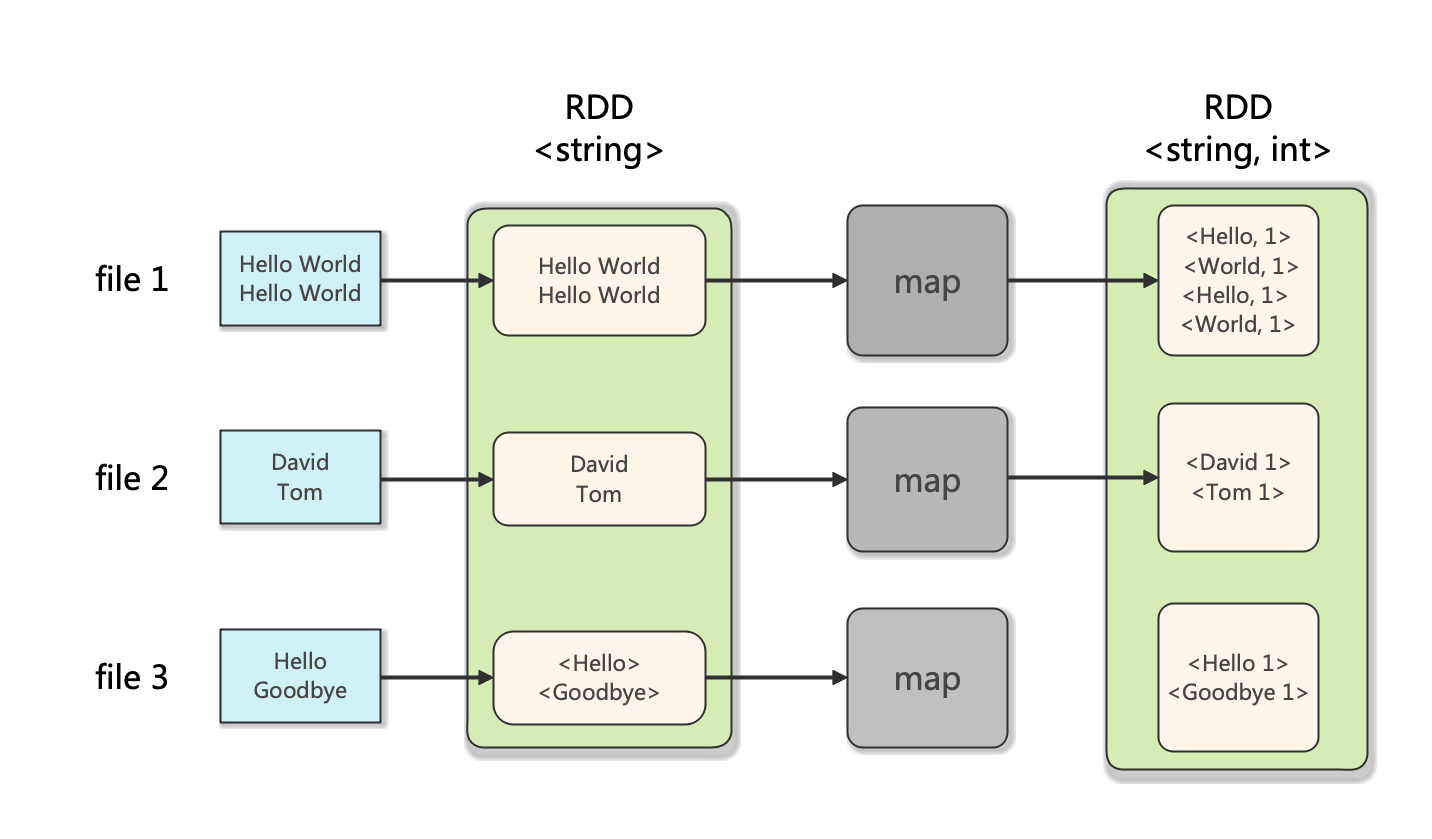
1 導引 我們在部落格《Hadoop: 單詞計數(Word Count)的MapReduce實現 》中學習了如何用Hado …
Continue Reading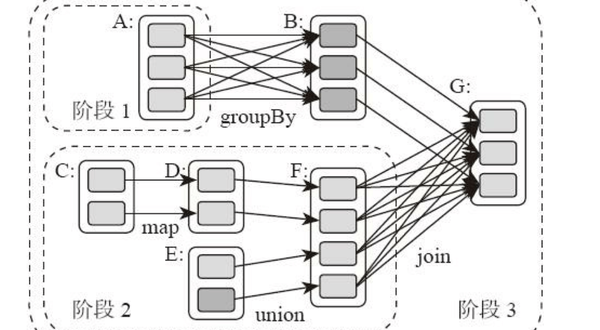
摘要:相比MapReduce僵化的Map與Reduce分階段計算相比,Spark的計算框架更加富有彈性和靈活性,運行性能 …
Continue Reading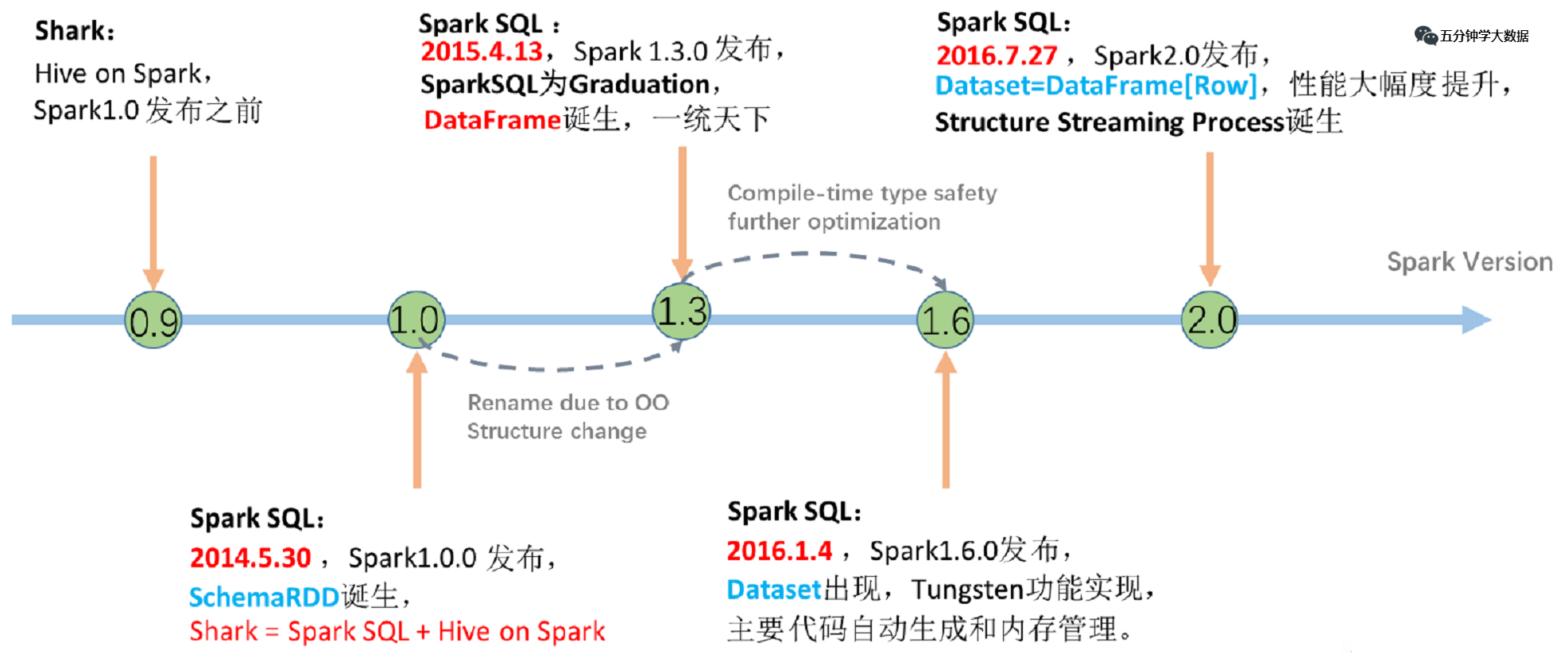
本文目錄 一、Apache Spark 二、Spark SQL發展歷程 三、Spark SQL底層執行原理 四、Cata …
Continue Reading
Spark配置介紹 Spark中的配置選項在四個地方可以進行配置,其中優先順序如下: SparkConf(程式碼) > …
Continue Reading
Spark系列面試題 Spark面試題(一) Spark面試題(二) Spark面試題(三) Spark面試題(四) S …
Continue Reading