SparkSQL中產生笛卡爾積的幾種典型場景以及處理策略
- 2021 年 3 月 16 日
- 筆記
【前言:如果你經常使用Spark SQL進行數據的處理分析,那麼對笛卡爾積的危害性一定不陌生,比如大量佔用集群資源導致其 …
Continue Reading【前言:如果你經常使用Spark SQL進行數據的處理分析,那麼對笛卡爾積的危害性一定不陌生,比如大量佔用集群資源導致其 …
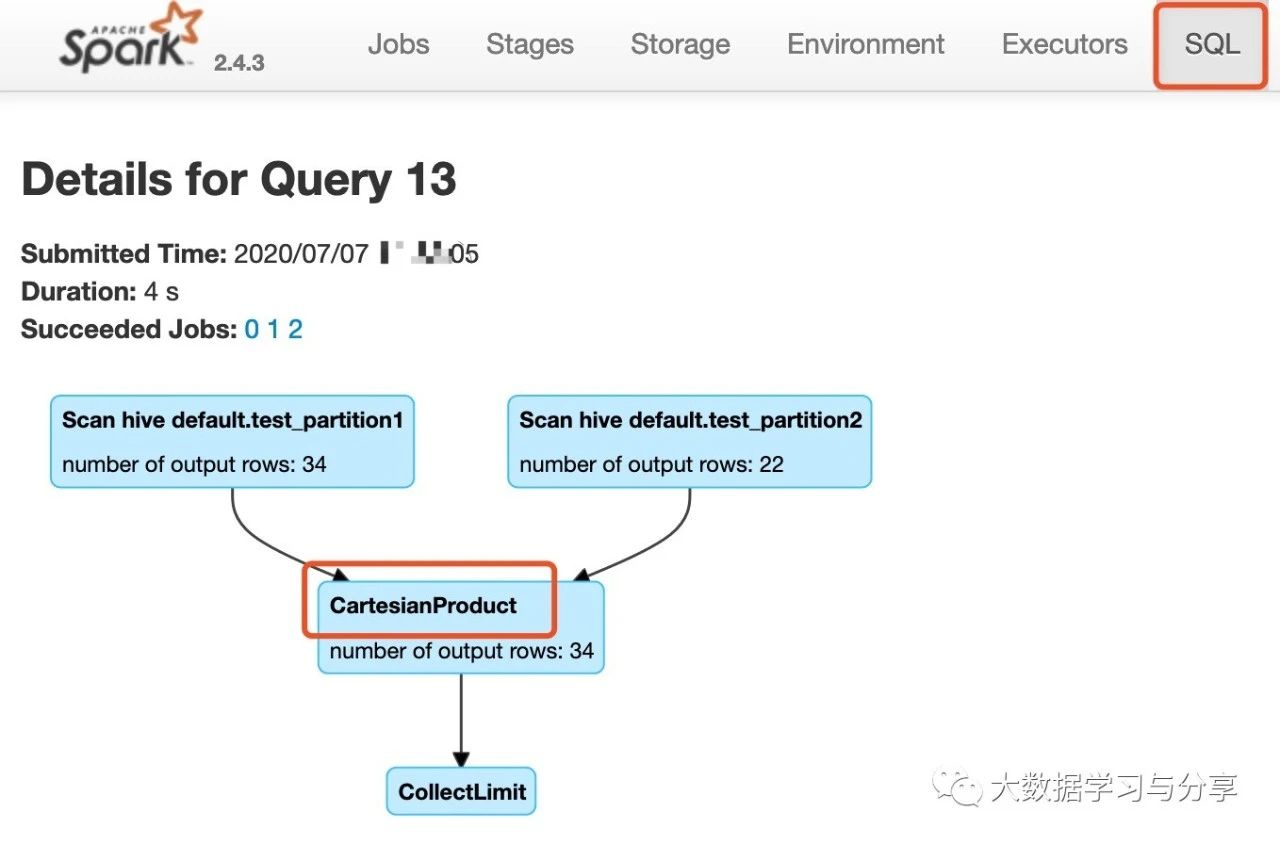
Continue Reading首先看個Not in Subquery的SQL: // test_partition1 和 test_partition …
Continue ReadingHive實現自增序列 在利用數據倉庫進行數據處理時,通常有這樣一個業務場景,為一個Hive表新增一列自增欄位(比如事實表 …
Continue Reading