
分散式機器學習:模型平均MA與彈性平均EASGD(PySpark)
- 2022 年 6 月 30 日
- 筆記
電腦科學一大定律:許多看似過時的東西可能過一段時間又會以新的形式再次回歸。 1 模型平均方法(MA) 1.1 演算法描述 …
Continue Reading電腦科學一大定律:許多看似過時的東西可能過一段時間又會以新的形式再次回歸。 1 模型平均方法(MA) 1.1 演算法描述 …
Continue Reading
1 分散式機器學習概述 大規模機器學習訓練常面臨計算量大、訓練數據大(單機存不下)、模型規模大的問題,對此分散式機器學習 …
Continue Reading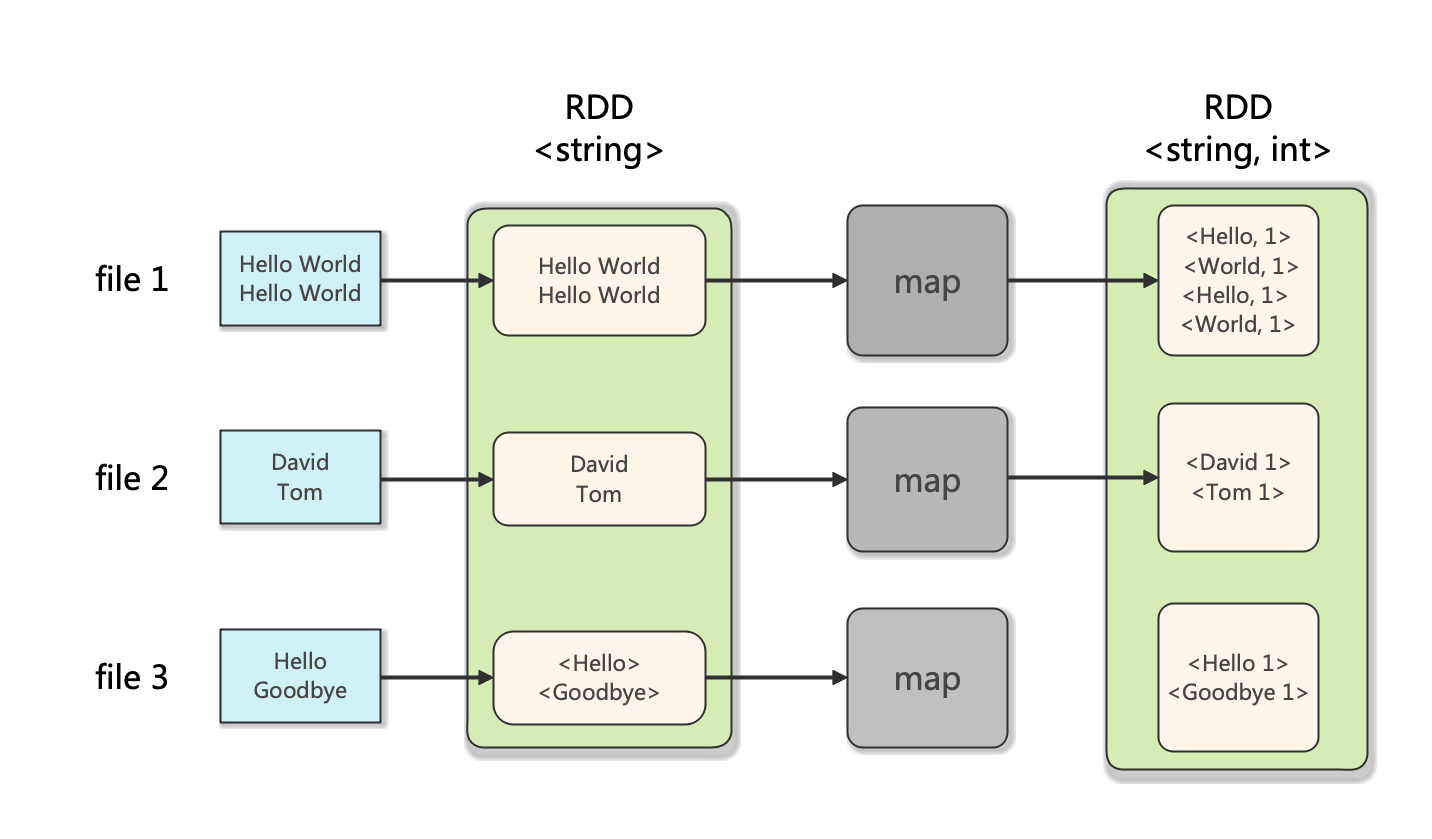
1 導引 我們在部落格《Hadoop: 單詞計數(Word Count)的MapReduce實現 》中學習了如何用Hado …
Continue Reading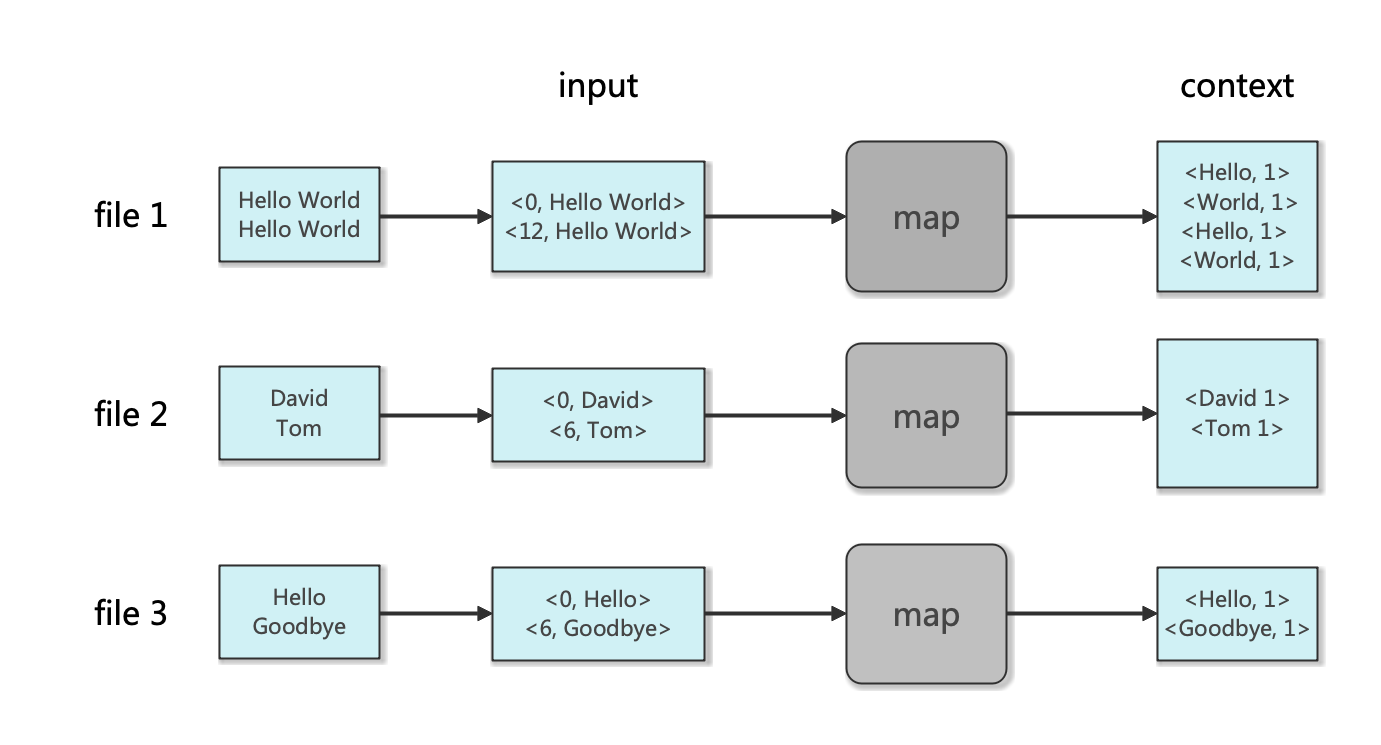
1.Map與Reduce過程 1.1 Map過程 首先,Hadoop會把輸入數據劃分成等長的輸入分片(input spl …
Continue Reading摘要:結構上Hive On Spark和SparkSQL都是一個翻譯層,把一個SQL翻譯成分散式可執行的Spark程式。 …
Continue Reading
因為在我最近的科研中需要用到分散式的社區檢測(也稱為圖聚類(graph clustering))演算法,專門去查找了相關文 …
Continue Reading
在上一篇博文《分散式機器學習中的模型聚合》(鏈接://www.cnblogs.com/orion-orion/p/156 …
Continue Reading
論文1在聯邦(分散式)學習的情景下引入了多任務學習,其採用的手段是使每個client/task節點的訓練數據分布不同 …
Continue Reading今天開始跑分散式機器學習論文實驗了,這裡介紹一下論文的常用數據集(因為我的研究領域是分散式機器學習,所以下面列出的數據集 …
Continue Reading
前言 Catalyst是Spark SQL核心優化器,早期主要基於規則的優化器RBO,後期又引入基於代價進行優化的CBO …
Continue Reading