深入了解String,StringBuffer和StringBuilder三個類的異同
- 2019 年 10 月 6 日
- 筆記
Java提供了三個類,用於處理字元串,分別是String、StringBuffer和StringBuilder。其中StringBuilder是jdk1.5才引入的。
這三個類有什麼區別呢?他們的使用場景分別是什麼呢?
本文的程式碼是在jdk12上運行的,jdk12和jdk5,jdk8有很大的區別,特別是String、StringBuffer和StringBuilder的實現。
jdk5和jdk8中String類的value類型是char[],到了jdk12,value類型變為byte[]。
jdk5、JDK6中的常量池是放在永久代的,永久代和Java堆是兩個完全分開的區域。
到了jdk7及以後的版本,
我們先來看看這三個類的源碼。
String類部分源碼:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence, Constable, ConstantDesc { @Stable private final byte[] value; public String(String original) { this.value = original.value; this.coder = original.coder; this.hash = original.hash; } public native String intern();String類由final修飾符修飾,所以String類是不可變的,對象一旦創建,不能改變。
String類中有個value的位元組數組成員 變數,這個變數用於存儲字元串的內容,也是用final修飾,一旦初始化,不可改變。
java提供了兩種主要方式創建字元串:
//方式1 String str = "123"; //方式2 String str = new String("123");java虛擬機規範中定義字元串都是存儲在字元串常量池中,不管是用方式1還是方式2創建字元串,都會從去字元串常量池中查找,如果已經存在,直接返回,否則創建後返回。
java編譯器在編譯java類時,遇到「abc」,「hello」這樣的字元串常量,會將這些常量放入類的常量區,類在載入時,會將字元串常量加入到字元串常量池中。
含有表達式的字元串常量,不會在編譯時放入常量區,例如,String str = "abc" + a
常量池的最大作用是共享使用,提高程式執行效率。
看看下面幾個案例。
案例1:
1 String str1 = "123"; 2 String str2 = "123"; 3 System.out.println(str1 == str2);上面程式碼運行的結果為true。
運行第1行程式碼時,現在常量池中創建字元串123對象,然後賦值給str1變數。
運行第2行程式碼時,發現常量池已經存在123對象,則直接將123對象的地址返回給變數str2。
str1和str2變數指向的地址一樣,他們是同一個對象,因此運行的結果為true。
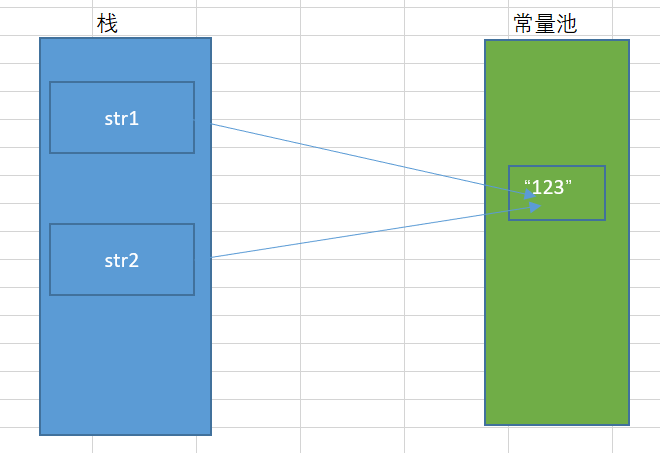
從圖中可以看出,str1使用」」引號(也是平時所說的字面量)創建字元串,在編譯期的時候就對常量池進行判斷是否存在該字元串,如果存在則不創建直接返回對象的引用;如果不存在,則先在常量池中創建該字元串實例再返回實例的引用給str1。
案例2:
1 String str1 = new String("123"); 2 String str2 = new String("123"); 3 String str3 = new String(str2); 4 System.out.println((str1==str2)); 5 System.out.println((str1==str3)); 6 System.out.println((str3==str2)); 上面程式碼運行的結果是
false false false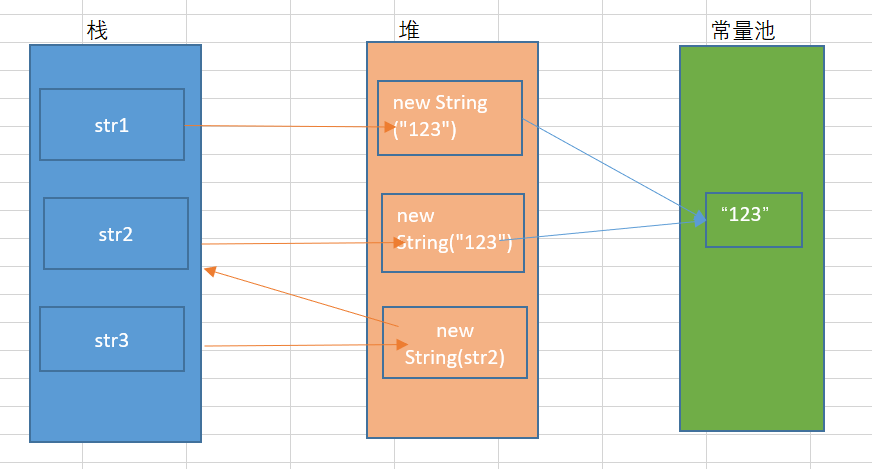
從上圖可以看出,執行第1行程式碼時,創建了兩個對象,一個存放在字元串常量池中,一個存在與堆中,還有一個對象引用str1存放在棧中。
執行第2行程式碼時,字元串常量池中已經存在「123」對象,所以只在堆中創建了一個字元串對象,並且這個對象的地址指向常量池中「123」對象的地址,同時在棧中創建一個對象引用str2,引用地址指向堆中創建的對象。
執行第3行程式碼時,在堆中創建一個字元串對象,這個對象的記憶體地址指向變數str2所執向的記憶體地址。
通過new方式創建的字元串對象,都會在堆中開闢一個新記憶體空間,用於存儲常量池中的字元串對象。
對於對象而言,==操作是用於比較兩個獨享的記憶體地址是否一致,所以上面的程式碼執行的結果都是false。
案例3:
//這行程式碼編譯後的效果等同於String str1 = "abcd"; String str1 = "ab" + "cd"; String str2 = "abcd"; System.out.println((str1 == str2)); 上面程式碼執行的結果:true。
使用包含常量的字元串連接創建的也是常量,編譯期就能確定了,類載入的時候直接進入字元串常量池,當然同樣需要判斷字元串常量池中是否已經存在該字元串。
案例4:
String str2 = "ab"; //1個對象 String str3 = "cd"; //1個對象 String str4 = str2 + str3 + 「1」; String str5 = "abcd1"; System.out.println((str4==str5)); 上面程式碼執行的結果:false。
當使用「+」連接字元串中含有變數時,由於變數的值是在運行時才能確定。
如果使用的jdk8以前版本的虛擬機,在拼接字元串時,會在jvm堆中生成StringBuilder對象,調用append方法拼接字元串,最後調用StringBuilder的toString方法在jvm堆中生成最終的字元串對象。
通過查看位元組碼就可以知道jdk8之前版本的"+"拼接字元串時通過StringBuilder實現的。通過查看位元組碼就可以知道,如下圖所示:
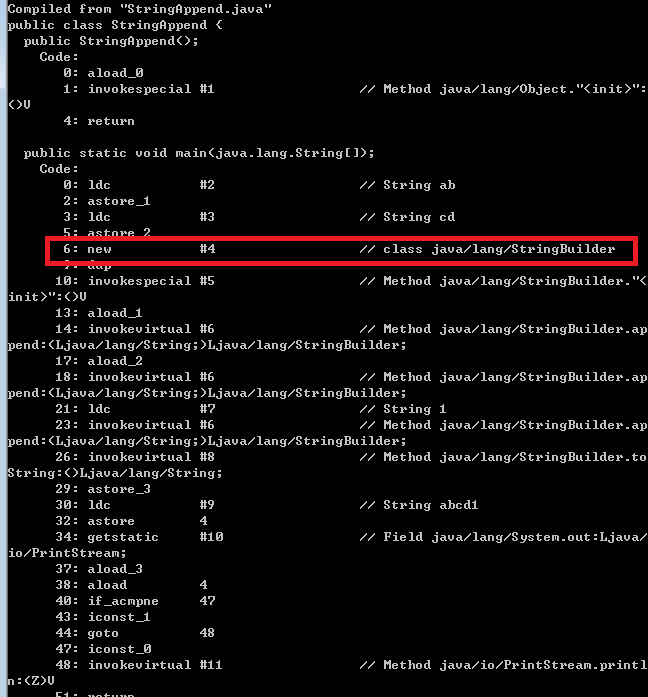
而如果使用的是jdk9以後版本的虛擬機,則是調用虛擬機自帶的InvokeDynamic拼接字元串,並且保存在堆中。位元組碼如下所示:
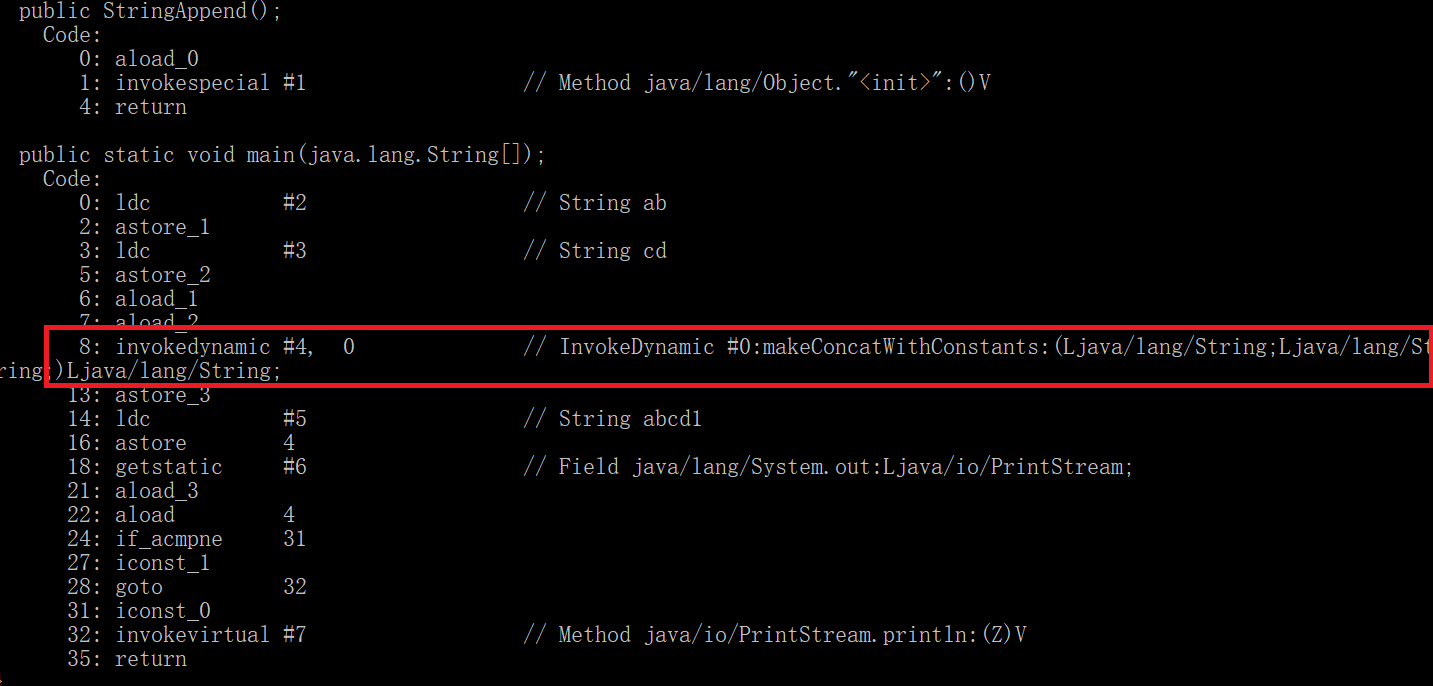
str4的對象在字元串常量池中,str5的對象在堆中,所以他們的不是同一個對象,所以返回的結果是false。
案例5:
String s5 = new String(「2」) + new String(「3」);和案例4一樣,因為new String("2")創建字元串,也是在運行時才能確定對象記憶體地址,和案例4一樣。
案例6:
final String str1 = "b"; String str2 = "a" + str1; String str3 = "ab"; System.out.println((str2 == str3)); 上面程式碼執行的結果為true。
str1是常量變數,在編譯期就確定,直接放入到字元串常量池中,上面的程式碼效果等同於:
String str2 = "a" + "b"; String str3 = "ab"; System.out.println((str2 == str3));調用String類的intern()方法,會將堆中的字元串實例放入到字元串常量池中。
案例7:
String str2 = "ab"; String str3 = "cd"; String str4 = str2 + str3 + "1"; str4.intern(); String str5 = "abcd1"; System.out.println((str4==str5));上面程式碼執行的結果:true。調用了str4.intern()方法後,將str4放入到字元串常量池中,和str5是同一個實例。
StringBuffer部分源碼:
public final class StringBuffer extends AbstractStringBuilder implements java.io.Serializable, Comparable<StringBuffer>, CharSequence {StringBuilder部分源碼:
public final class StringBuilder extends AbstractStringBuilder implements java.io.Serializable, Comparable<StringBuilder>, CharSequence {可見StringBuffer和StringBuilder都繼承了AbstractStringBuilder類。
AbstractStringBuilder類源碼:
abstract class AbstractStringBuilder implements Appendable, CharSequence { /** * The value is used for character storage. */ byte[] value;AbstractStringBuilder也有一個位元組數組的成員變數value,這個變數用於存儲字元串的值,這個變數不是用final修飾,所以是可以改變的,這個是和String的最大區別。
在調用append方法的時候,會動態增加位元組數組變數value的大小。
StringBuffer和StringBuilder功能是一樣的,都是為了提高java中字元串連接的效率,因為直接使用+進行字元串連接的話,jvm會創建多個String對象,因此造成一定的開銷。AbstractStringBuilder中採用一個byte數組來保存需要append的字元串,byte數組有一個初始大小,當append的字元串長度超過當前char數組容量時,則對byte數組進行動態擴展,也即重新申請一段更大的記憶體空間,然後將當前bute數組拷貝到新的位置,因為重新分配記憶體並拷貝的開銷比較大,所以每次重新申請記憶體空間都是採用申請大於當前需要的記憶體空間的方式,這裡是2倍。
StringBuffer和StringBuilder最大的區別是StringBuffer是執行緒安全,而StringBuilder是非執行緒安全的,從它們兩個類的源碼就可以知道,StringBuffer類的方法前面都是synchronized修飾符。
String一旦賦值或實例化後就不可更改,如果賦予新值將會重新開闢記憶體地址進行存儲。
而StringBuffer和StringBuilder類使用append和insert等方法改變字元串值時只是在原有對象存儲的記憶體地址上進行連續操作,減少了資源的開銷。
總結:
1、頻繁使用「+」操作拼接字元時,換成StringBuffer和StringBuilder類的append方法實現。
2、多執行緒環境下進行大量的拼接字元串操作使用StringBuffer,StringBuffer是執行緒安全的;
3、單執行緒環境下進行大量的拼接字元串操作使用StringBuilder,StringBuilder是執行緒不安全的。
